
Il nostro cervello ha una straordinaria capacità di elaborare le informazioni visive. Possiamo dare uno sguardo a una scena complessa e in pochi millisecondi essere in grado di analizzarla in oggetti e i loro attributi, come colore o dimensione, e utilizzare queste informazioni per descrivere la scena in un linguaggio semplice. Alla base di questa capacità apparentemente semplice c’è un calcolo complesso eseguito dalla nostra corteccia visiva, che implica prendere milioni di impulsi neurali trasmessi dalla retina e trasformarli in una forma più significativa che può essere mappata nella semplice descrizione del linguaggio. Per comprendere appieno come funziona questo processo nel cervello, dobbiamo capire sia come l’informazione semanticamente significativa viene rappresentata nell’attivazione dei neuroni alla fine della gerarchia dell’elaborazione visiva, sia come tale rappresentazione può essere appresa in gran parte esperienza non insegnata.
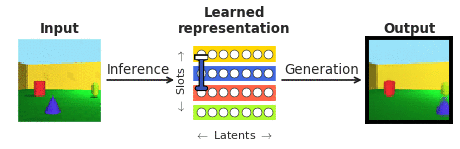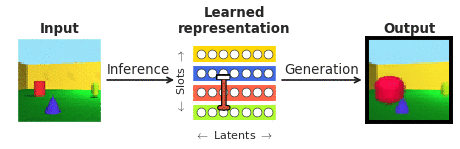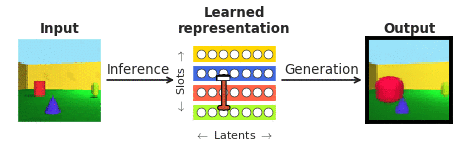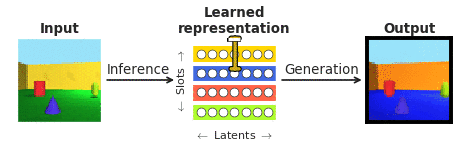
Per rispondere a queste domande nel contesto della percezione del volto, abbiamo unito le forze con i nostri collaboratori di Caltech (Doris Tsao) e l’Accademia cinese delle scienze (Il Chang). Abbiamo scelto i volti perché sono ben studiati nella comunità delle neuroscienze e sono spesso visti come “microcosmo del riconoscimento degli oggetti”. In particolare, abbiamo voluto confrontare le risposte dei singoli neuroni corticali nelle zone del viso alla fine della gerarchia di elaborazione visiva, registrate dai nostri collaboratori, con una classe recentemente emersa di cosiddette reti neurali profonde “districanti” che, a differenza delle solite “reti neurali” sistemi “scatola nera”, mirano esplicitamente a essere interpretabili per gli esseri umani. Una rete neurale “districante” impara a mappare immagini complesse in un piccolo numero di neuroni interni (chiamati unità latenti), ciascuno dei quali rappresenta un singolo attributo semanticamente significativo della scena, come il colore o la dimensione di un oggetto (vedi Figura 1). A differenza dei classificatori profondi “scatola nera” addestrati a riconoscere oggetti visivi attraverso una quantità biologicamente irrealistica di supervisione esterna, tali modelli districanti vengono addestrati senza un segnale di insegnamento esterno utilizzando un obiettivo auto-supervisionato di ricostruire le immagini di input (generazione nella Figura 1) dalle loro rappresentazione latente appresa (ottenuta tramite inferenza nella Figura 1).
Districare era ipotizzato essere importante nella comunità del machine learning quasi dieci anni fa come componente integrale per costruirne di più efficiente in termini di dati, trasferibile, GiustoE fantasioso sistemi di intelligenza artificiale. Tuttavia, per anni, la costruzione di un modello in grado di districare i nodi nella pratica è sfuggita al campo. Il primo modello in grado di farlo con successo e robustezza, chiamato β-VAEè stato sviluppato prendendo ispirazione dalle neuroscienze: β-VAE impara da prevedere i propri input; richiede un’esperienza visiva simile per un apprendimento di successo come quello incontrato dai bambini; e la sua rappresentazione latente appresa rispecchia il proprietà conosciute del cervello visivo.
Nel nostro nuova cartaabbiamo misurato la misura in cui le unità districate scoperte da un β-VAE addestrato su un dataset di immagini di volti sono simili alle risposte dei singoli neuroni al termine dell’elaborazione visiva registrate nei primati che guardano gli stessi volti. I dati neurali sono stati raccolti dai nostri collaboratori sotto la rigorosa supervisione di Comitato istituzionale per la cura e l’uso degli animali del Caltech. Quando abbiamo effettuato il confronto, abbiamo scoperto qualcosa di sorprendente: sembrava che la manciata di unità districate scoperte da β-VAE si comportassero come se fossero equivalenti a un sottoinsieme di neuroni reali di dimensioni simili. Quando abbiamo guardato più da vicino, abbiamo trovato una forte mappatura uno a uno tra i neuroni reali e quelli artificiali (vedi Figura 2). Questa mappatura era molto più forte di quella di modelli alternativi, inclusi i classificatori profondi precedentemente considerati modelli computazionali all’avanguardia dell’elaborazione visiva, o un modello artigianale di percezione del volto visto come il “gold standard” nella comunità delle neuroscienze. Non solo, le unità β-VAE codificavano informazioni semanticamente significative come età, sesso, dimensione degli occhi o presenza di un sorriso, permettendoci di capire quali attributi i singoli neuroni nel cervello utilizzano per rappresentare i volti.
.jpg)
Se β-VAE fosse effettivamente in grado di scoprire automaticamente unità latenti artificiali che sono equivalenti ai neuroni reali in termini di come rispondono alle immagini del volto, allora dovrebbe essere possibile tradurre l’attività dei neuroni reali nelle loro controparti artificiali abbinate e utilizzare il generatore (vedi Figura 1) del β-VAE addestrato per visualizzare quali volti rappresentano i neuroni reali. Per testarlo, abbiamo presentato ai primati nuove immagini del volto che il modello non aveva mai sperimentato e abbiamo verificato se potevamo riprodurle utilizzando il generatore β-VAE (vedere Figura 3). Abbiamo scoperto che ciò era effettivamente possibile. Utilizzando l’attività di appena 12 neuroni, siamo stati in grado di generare immagini di volti che erano ricostruzioni più accurate degli originali e di migliore qualità visiva rispetto a quelle prodotte dai modelli generativi profondi alternativi. Ciò nonostante il fatto che i modelli alternativi siano noti per essere generatori di immagini migliori rispetto al β-VAE in generale.
.jpg)
I nostri risultati riassunti nel nuova carta suggeriscono che il cervello visivo può essere compreso a livello di singolo neurone, anche alla fine della sua gerarchia di elaborazione. Ciò è contrario alla credenza comune che le informazioni siano semanticamente significative multiplex tra un gran numero di tali neuroniognuno di essi rimane in gran parte non interpretabile individualmente, non diversamente da come le informazioni vengono codificate attraverso strati interi di neuroni artificiali in classificatori profondi. Non solo, i nostri risultati suggeriscono che è possibile che il cervello impari a supportare la nostra capacità senza sforzo di percepire visivamente ottimizzando l’obiettivo di districamento. Mentre β-VAE è stato originariamente sviluppato ispirandosi a principi neuroscientifici di alto livellol’utilità delle rappresentazioni districate per il comportamento intelligente è stata finora dimostrata principalmente nel comunità di apprendimento automatico. In linea con la ricca storia di reciprocamente vantaggiosi interazioni tra neuroscienze e machine learningsperiamo che le ultime intuizioni dell’apprendimento automatico possano ora fornire un feedback alla comunità delle neuroscienze per indagare il merito delle rappresentazioni districate per supportare l’intelligenza nei sistemi biologici, in particolare come base per ragionamento astrattoo generalizzabile ed efficiente apprendimento del compito.

