
Presentazione dell’impilamento RGB come nuovo punto di riferimento per la manipolazione robotica basata sulla visione
Prendere un bastone e metterlo in equilibrio su un tronco o impilare un sasso su una pietra può sembrare azioni semplici – e abbastanza simili – per una persona. Tuttavia, la maggior parte dei robot ha difficoltà a gestire più di un compito simile alla volta. Manipolare un bastone richiede una serie di comportamenti diversi rispetto a impilare pietre, per non parlare di impilare vari piatti uno sopra l’altro o assemblare mobili. Prima di poter insegnare ai robot come eseguire questo tipo di compiti, è necessario che imparino a interagire con una gamma molto più ampia di oggetti. Nell’ambito di La missione di DeepMind e come passo verso la creazione di robot più generalizzabili e utili, stiamo esplorando come consentire ai robot di comprendere meglio le interazioni di oggetti con geometrie diverse.
In un documento che sarà presentato a CoRL 2021 (Conference on Robot Learning) e ora disponibile come prestampa su ApriRecensioneintroduciamo l’impilamento RGB come nuovo punto di riferimento per la manipolazione robotica basata sulla visione. In questo benchmark, un robot deve imparare ad afferrare diversi oggetti e a tenerli in equilibrio uno sopra l’altro. Ciò che distingue la nostra ricerca dal lavoro precedente è la diversità degli oggetti utilizzati e il gran numero di valutazioni empiriche eseguite per convalidare i nostri risultati. I nostri risultati dimostrano che una combinazione di simulazione e dati del mondo reale può essere utilizzata per apprendere la complessa manipolazione di più oggetti e suggeriscono una solida base di partenza per il problema aperto della generalizzazione a nuovi oggetti. Per supportare altri ricercatori, siamo open source una versione del nostro ambiente simulato e rilasciando il file disegni per costruire il nostro ambiente di impilamento RGB di robot reali, insieme ai modelli di oggetti RGB e alle informazioni per stamparli in 3D. Siamo anche open source una raccolta di librerie e strumenti utilizzato nella nostra ricerca sulla robotica in modo più ampio.
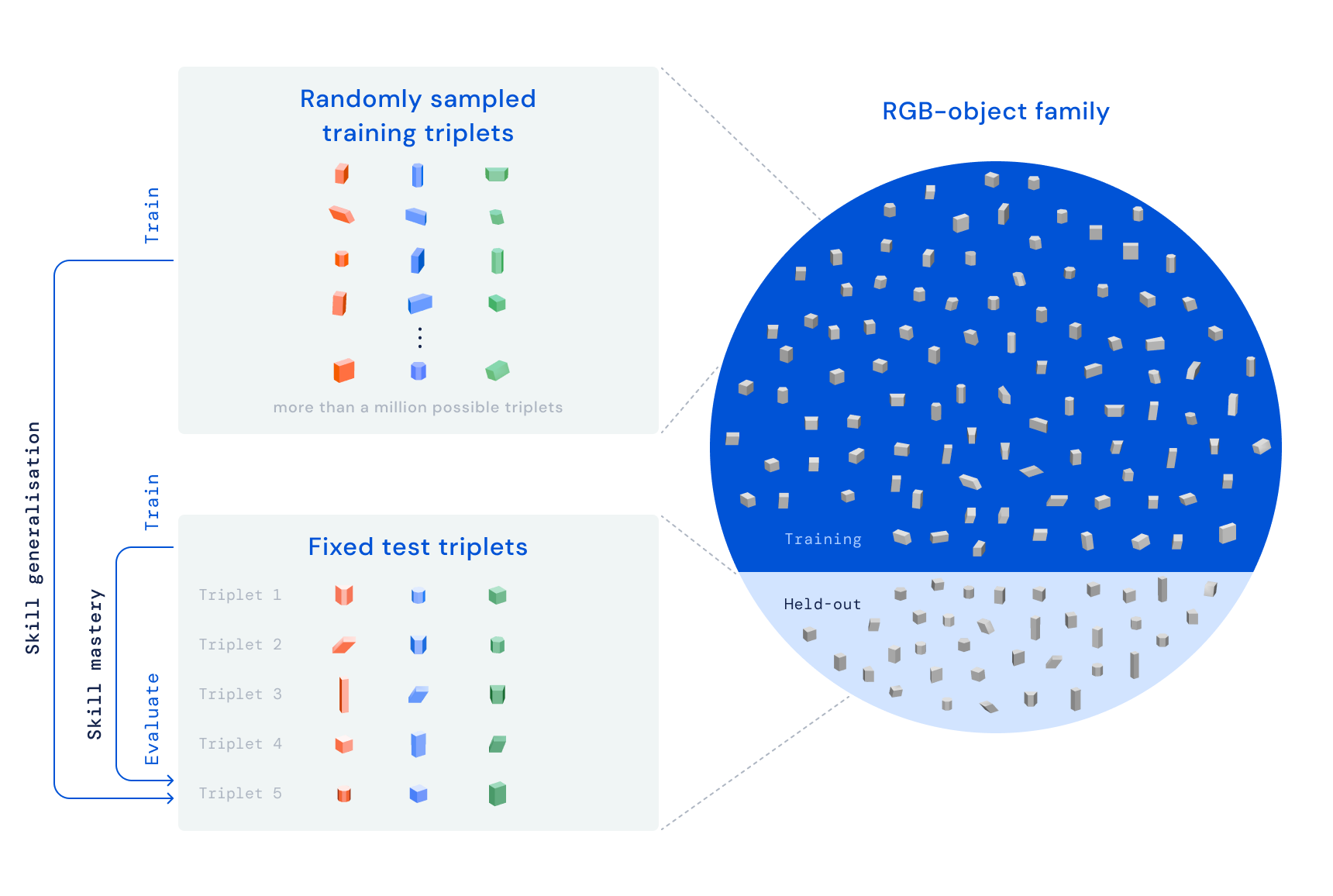
Con l’impilamento RGB, il nostro obiettivo è addestrare un braccio robotico tramite rinforzo imparando a impilare oggetti di forme diverse. Posizioniamo una pinza parallela collegata a un braccio robotico sopra un cestello e tre oggetti nel cestello: uno rosso, uno verde e uno blu, da cui il nome RGB. Il compito è semplice: entro 20 secondi impila l’oggetto rosso sopra l’oggetto blu, mentre l’oggetto verde funge da ostacolo e distrazione. Il processo di apprendimento garantisce che l’agente acquisisca competenze generalizzate attraverso la formazione su più set di oggetti. Variamo intenzionalmente le affordance di presa e impilamento: le qualità che definiscono il modo in cui l’agente può afferrare e impilare ciascun oggetto. Questo principio di progettazione costringe l’agente a mostrare comportamenti che vanno oltre una semplice strategia di pick-and-place.

Il nostro benchmark RGB-Stacking include due versioni di attività con diversi livelli di difficoltà. In “Skill Mastery”, il nostro obiettivo è formare un singolo agente abile nell’impilare un set predefinito di cinque triplette. Nella “Generalizzazione delle abilità” utilizziamo le stesse triplette per la valutazione, ma addestriamo l’agente su un ampio insieme di oggetti di addestramento, per un totale di oltre un milione di possibili triplette. Per testare la generalizzazione, questi oggetti di addestramento escludono la famiglia di oggetti da cui sono state scelte le triplette di test. In entrambe le versioni, disaccoppiamo la nostra pipeline di apprendimento in tre fasi:
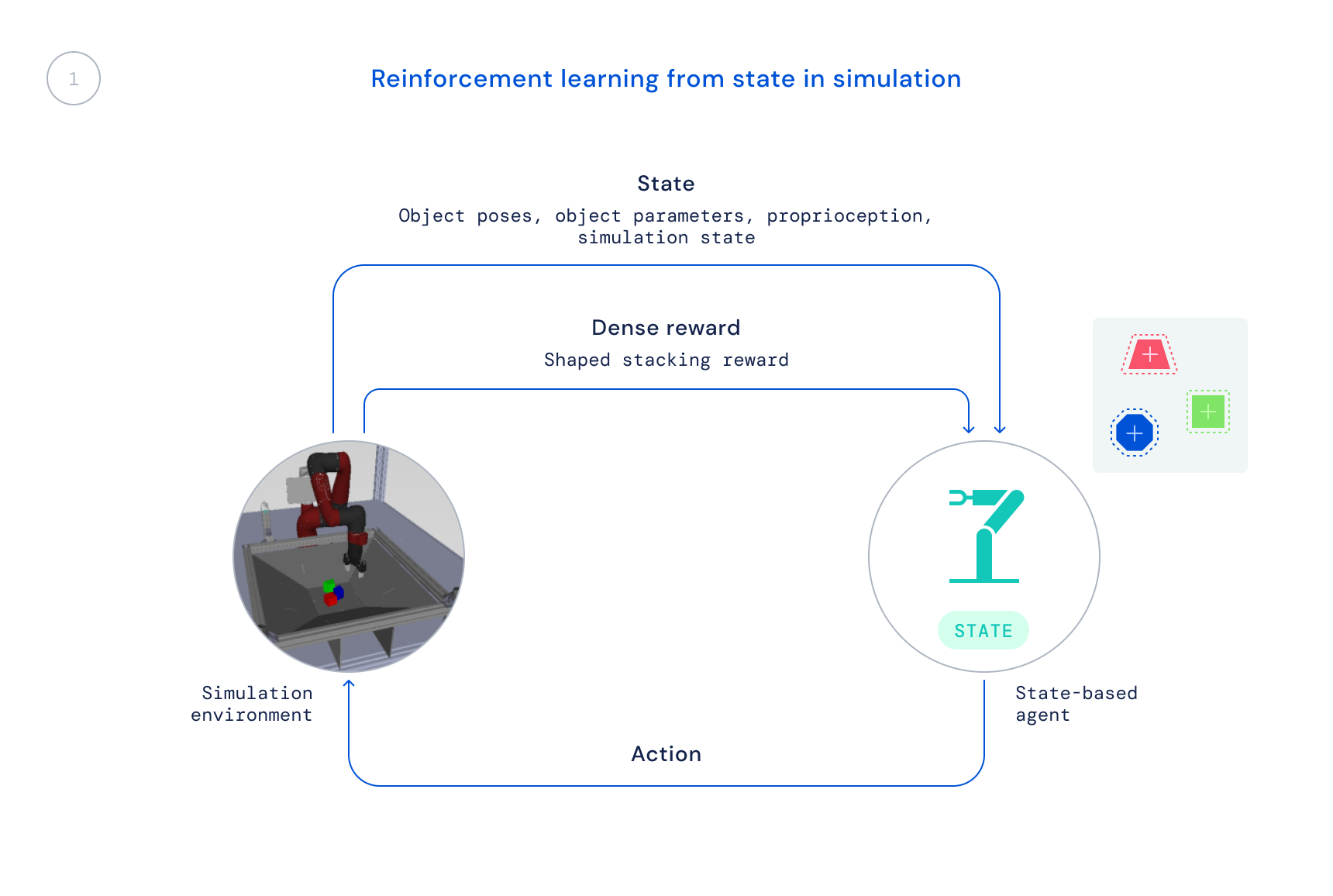
- Innanzitutto, ci alleniamo nella simulazione utilizzando un algoritmo RL standard: Massima ottimizzazione delle politiche a posteriori (MPO). In questa fase utilizziamo lo stato del simulatore, consentendo un addestramento rapido poiché le posizioni degli oggetti vengono fornite direttamente all’agente invece che l’agente deve imparare a trovare gli oggetti nelle immagini. La politica risultante non è direttamente trasferibile al robot reale poiché queste informazioni non sono disponibili nel mondo reale.
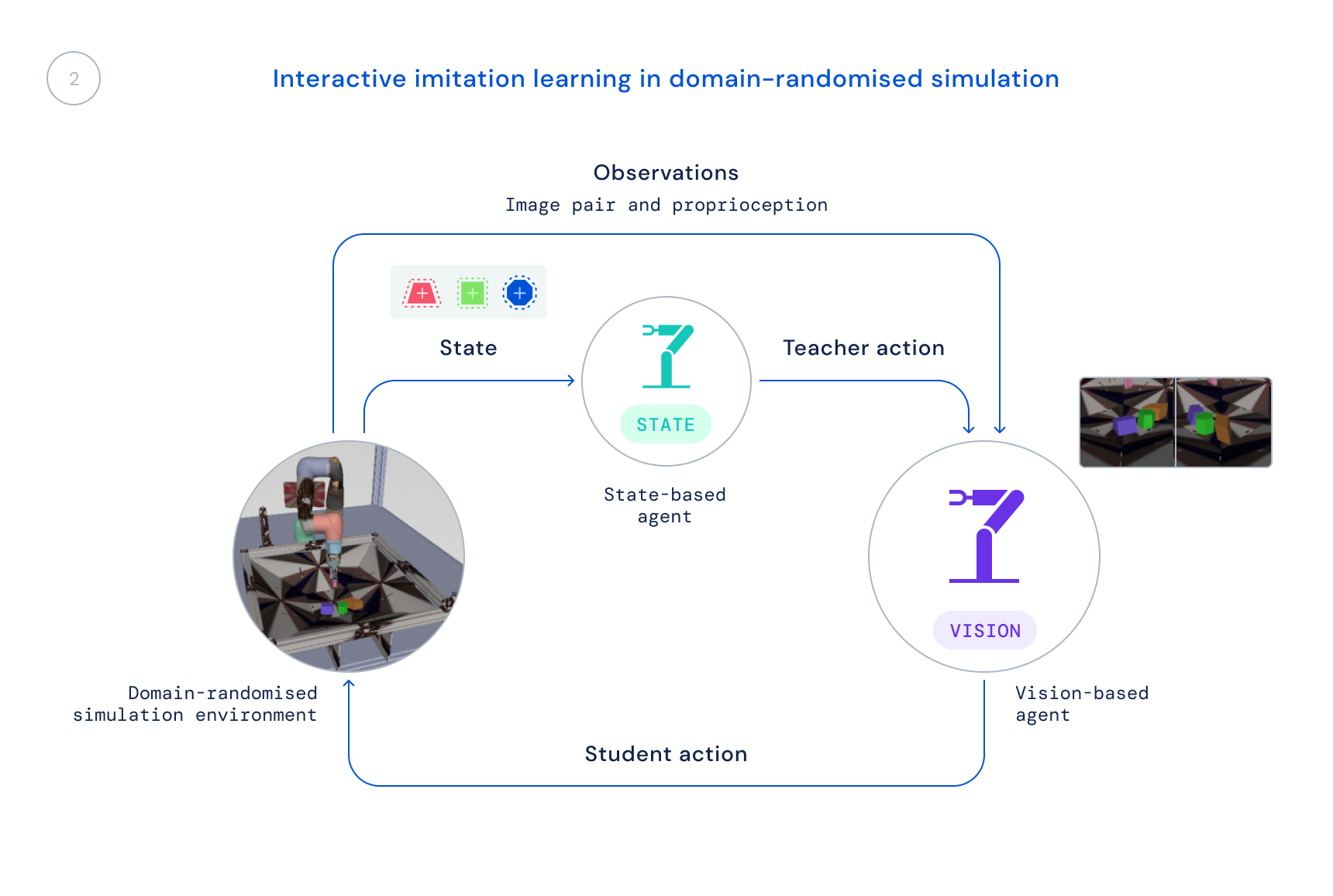
- Successivamente, alleniamo una nuova politica di simulazione che utilizza solo osservazioni realistiche: immagini e stato propriocettivo del robot. Utilizziamo una simulazione randomizzata del dominio per migliorare il trasferimento alle immagini e alle dinamiche del mondo reale. La politica statale funge da insegnante, fornendo all’agente di apprendimento correzioni ai suoi comportamenti, e tali correzioni vengono distillate nella nuova politica.
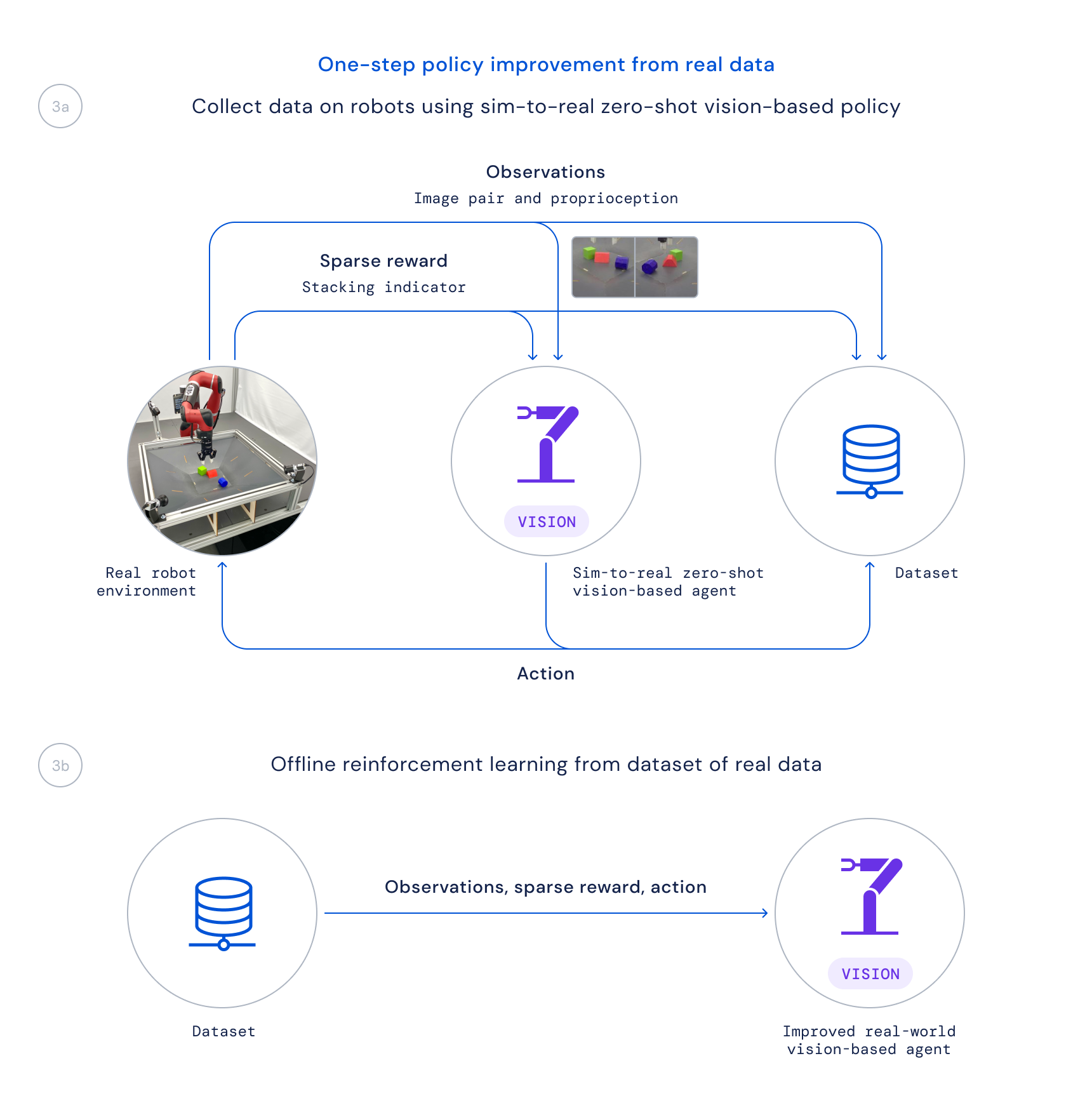
- Infine, raccogliamo dati utilizzando questa policy su robot reali e formiamo una policy migliorata da questi dati offline, valutando le buone transizioni basate su una funzione Q appresa, come fatto in Regressione regolarizzata critica (CRR). Questo ci consente di utilizzare i dati raccolti passivamente durante il progetto invece di eseguire un lungo algoritmo di formazione online sui robot reali.
Disaccoppiare la nostra pipeline di apprendimento in questo modo si rivela cruciale per due ragioni principali. In primo luogo, ci permette di risolvere del tutto il problema, poiché ci vorrebbe semplicemente troppo tempo se iniziassimo da zero direttamente sui robot. In secondo luogo, aumenta la velocità della nostra ricerca, poiché persone diverse nel nostro team possono lavorare su parti diverse della pipeline prima di combinare questi cambiamenti per un miglioramento complessivo.

Negli ultimi anni si è lavorato molto sull’applicazione di algoritmi di apprendimento per risolvere difficili problemi di manipolazione di robot reali su larga scala, ma il focus di tale lavoro si è in gran parte concentrato su compiti come afferrare, spingere o altre forme di manipolazione di singoli oggetti. L’approccio allo stacking RGB lo descriviamo nel nostro articolo, accompagnato da le nostre risorse sulla robotica sono ora disponibili su GitHubsi traduce in sorprendenti strategie di impilamento e padronanza nell’impilare un sottoinsieme di questi oggetti. Tuttavia, questo passaggio rappresenta solo la superficie di ciò che è possibile – e la sfida della generalizzazione rimane non completamente risolta. Mentre i ricercatori continuano a lavorare per risolvere la sfida aperta della vera generalizzazione nella robotica, speriamo che questo nuovo punto di riferimento, insieme all’ambiente, ai progetti e agli strumenti che abbiamo rilasciato, contribuisca a nuove idee e metodi che possano rendere la manipolazione ancora più semplice e i robot più capaci. .

