
Negli ultimi anni, gli agenti di intelligenza artificiale hanno avuto successo in una serie di ambienti di gioco complessi. Ad esempio, AlphaZero sconfiggi i programmi dei campioni del mondo di scacchi, shogi e Go dopo aver iniziato conoscendo solo le regole di base su come giocare. Attraverso insegnamento rafforzativo (RL), questo unico sistema appreso giocando un round dopo l’altro di giochi attraverso un processo ripetitivo di tentativi ed errori. Ma AlphaZero si allenava comunque separatamente su ciascun gioco, incapace di imparare semplicemente un altro gioco o attività senza ripetere da zero il processo RL. Lo stesso vale per altri successi di RL, come Atari, Cattura la bandiera, StarCraft II, Dota 2E Nascondino. La missione di DeepMind di risolvere l’intelligenza per far avanzare la scienza e l’umanità ci ha portato a esplorare come potremmo superare questa limitazione per creare agenti IA con comportamenti più generali e adattivi. Invece di imparare un gioco alla volta, questi agenti sarebbero in grado di reagire a condizioni completamente nuove e svolgere un intero universo di giochi e compiti, compresi quelli mai visti prima.
Oggi abbiamo pubblicato “L’apprendimento a tempo indeterminato porta ad agenti generalmente capaci“, una prestampa che descrive in dettaglio i nostri primi passi per addestrare un agente in grado di giocare a molti giochi diversi senza bisogno di dati di interazione umana. Abbiamo creato un vasto ambiente di gioco che chiamiamo XLand, che include molti giochi multiplayer all’interno di mondi 3D coerenti e facilmente riconoscibili dall’uomo. Questo ambiente rende possibile formulare nuovi algoritmi di apprendimento, che controllano dinamicamente il modo in cui un agente si allena e i giochi su cui si allena. Le capacità dell’agente migliorano in modo iterativo come risposta alle sfide che si presentano durante la formazione, con il processo di apprendimento che perfeziona continuamente i compiti di formazione in modo l’agente non smette mai di imparare. Il risultato è un agente con la capacità di riuscire in un’ampia gamma di compiti, dai semplici problemi di ricerca di oggetti a giochi complessi come nascondino e cattura la bandiera, che non sono stati incontrati durante l’addestramento. l’agente mostra comportamenti generali ed euristici come la sperimentazione, comportamenti che sono ampiamente applicabili a molti compiti piuttosto che specializzati in un compito individuale. Questo nuovo approccio segna un passo importante verso la creazione di agenti più generali con la flessibilità necessaria per adattarsi rapidamente ad ambienti in costante cambiamento.
Un universo di compiti formativi
La mancanza di dati di addestramento – in cui i punti “dati” sono compiti diversi – è stato uno dei principali fattori che limitano il comportamento degli agenti addestrati in RL a essere sufficientemente generale da poter essere applicato a tutti i giochi. Senza essere in grado di addestrare gli agenti su una serie sufficientemente vasta di compiti, gli agenti addestrati con RL non sono stati in grado di adattare i loro comportamenti appresi a nuovi compiti. Ma progettando uno spazio simulato per consentire compiti generati proceduralmenteil nostro team ha creato un modo per formarsi e generare esperienza da attività create a livello di programmazione. Ciò ci consente di includere miliardi di attività in XLand, attraverso vari giochi, mondi e giocatori.
I nostri agenti IA abitano avatar 3D in prima persona in un ambiente multiplayer pensato per simulare il mondo fisico. I giocatori percepiscono l’ambiente circostante osservando le immagini RGB e ricevono una descrizione testuale del loro obiettivo e si allenano su una serie di giochi. Questi giochi sono semplici come giochi cooperativi per trovare oggetti ed esplorare mondi, in cui l’obiettivo di un giocatore potrebbe essere “essere vicino al cubo viola”. I giochi più complessi possono basarsi sulla scelta tra più opzioni di ricompensa, come “essere vicino al cubo viola o mettere la sfera gialla sul pavimento rosso”, mentre i giochi più competitivi includono giocare contro co-giocatori, come il nascondino simmetrico dove ogni giocatore ha l’obiettivo: “vedere l’avversario e fare in modo che l’avversario non mi veda”. Ogni gioco definisce le ricompense per i giocatori e l’obiettivo finale di ogni giocatore è massimizzare le ricompense.
Poiché Xland può essere specificato a livello di codice, lo spazio di gioco consente la generazione di dati in modo automatizzato e algoritmico. E poiché i compiti in XLand coinvolgono più giocatori, il comportamento dei co-giocatori influenza notevolmente le sfide affrontate dall’agente AI. Queste interazioni complesse e non lineari creano una fonte di dati ideale su cui allenarsi, poiché a volte anche piccoli cambiamenti nei componenti dell’ambiente possono comportare grandi cambiamenti nelle sfide per gli agenti.

Metodi di formazione
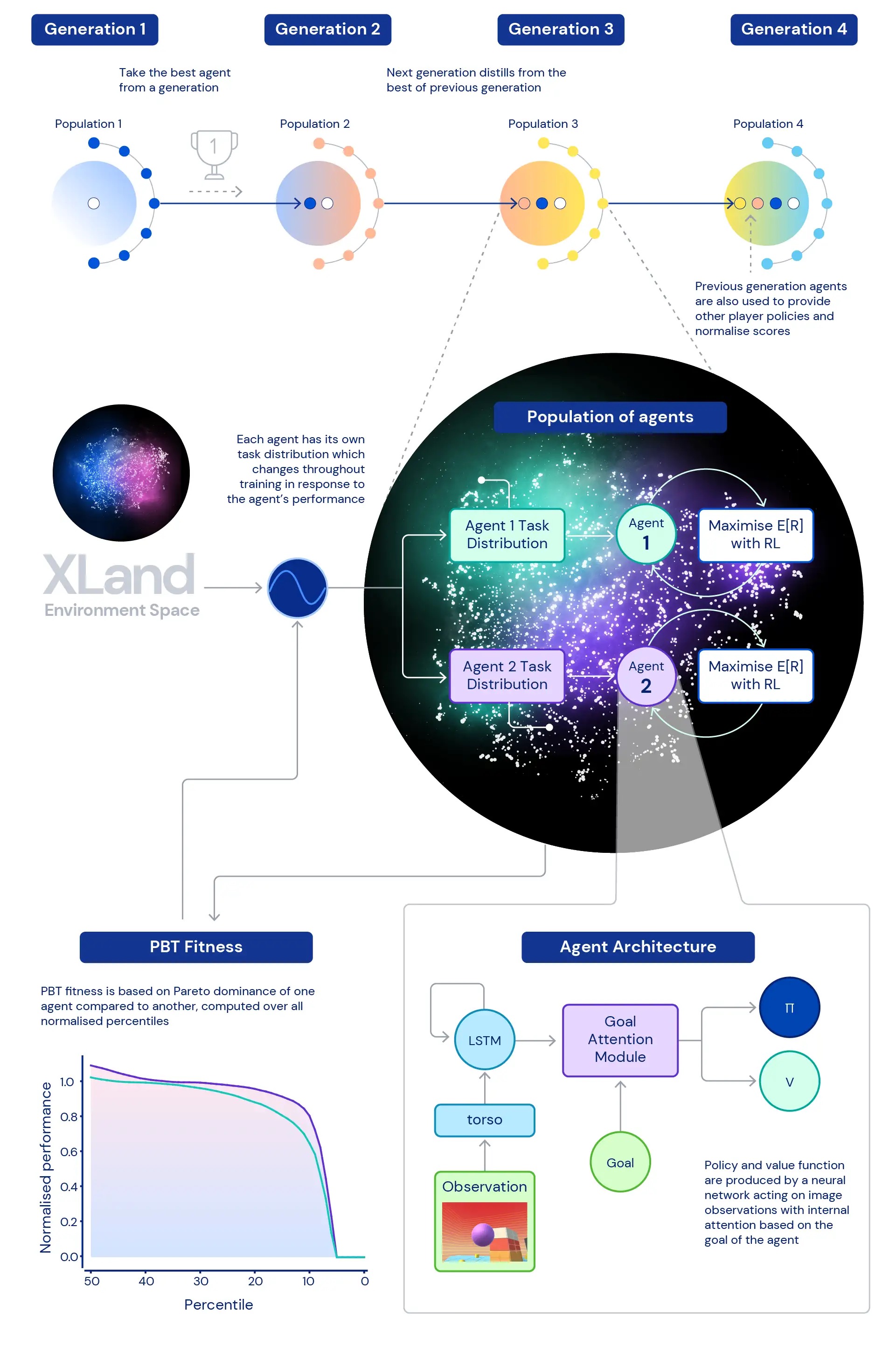
Centrale nella nostra ricerca è il ruolo di profondo RL nell’addestramento delle reti neurali dei nostri agenti. L’architettura della rete neurale che utilizziamo fornisce un meccanismo di attenzione sullo stato ricorrente interno dell’agente, aiutando a guidare l’attenzione dell’agente con stime di obiettivi secondari unici per il gioco a cui sta giocando. Abbiamo scoperto che questo agente attento agli obiettivi (GOAT) apprende politiche più generalmente capaci.
Abbiamo anche esplorato la questione: quale distribuzione dei compiti di formazione produrrà il miglior agente possibile, soprattutto in un ambiente così vasto? La generazione dinamica delle attività che utilizziamo consente modifiche continue alla distribuzione delle attività di formazione dell’agente: ogni attività viene generata per non essere né troppo difficile né troppo facile, ma adatta alla formazione. Usiamo quindi formazione basata sulla popolazione (PBT) per regolare i parametri della generazione dinamica delle attività sulla base di un’idoneità che mira a migliorare la capacità generale degli agenti. Infine, concatenamo più esecuzioni di formazione in modo che ogni generazione di agenti possa eseguire il bootstrap della generazione precedente.
Ciò porta a un processo di formazione finale con RL profondo al centro aggiornando le reti neurali degli agenti ad ogni fase dell’esperienza:
- i passaggi dell’esperienza provengono da compiti di formazione che vengono generati dinamicamente in risposta al comportamento degli agenti,
- le funzioni di generazione dei compiti degli agenti mutano in risposta alle prestazioni e alla robustezza relative degli agenti,
- nel circuito più esterno, le generazioni di agenti si avviano l’una dall’altra, forniscono co-giocatori sempre più ricchi all’ambiente multiplayer e ridefiniscono la misurazione stessa della progressione.
Il processo di formazione inizia da zero e crea iterativamente complessità, modificando costantemente il problema di apprendimento per mantenere l’agente in apprendimento. La natura iterativa del sistema di apprendimento combinato, che non ottimizza una metrica di prestazione limitata ma piuttosto lo spettro definito iterativamente di capacità generali, porta a un processo di apprendimento potenzialmente aperto per gli agenti, limitato solo dall’espressività dello spazio ambientale e dell’agente. rete neurale.
Misurare il progresso
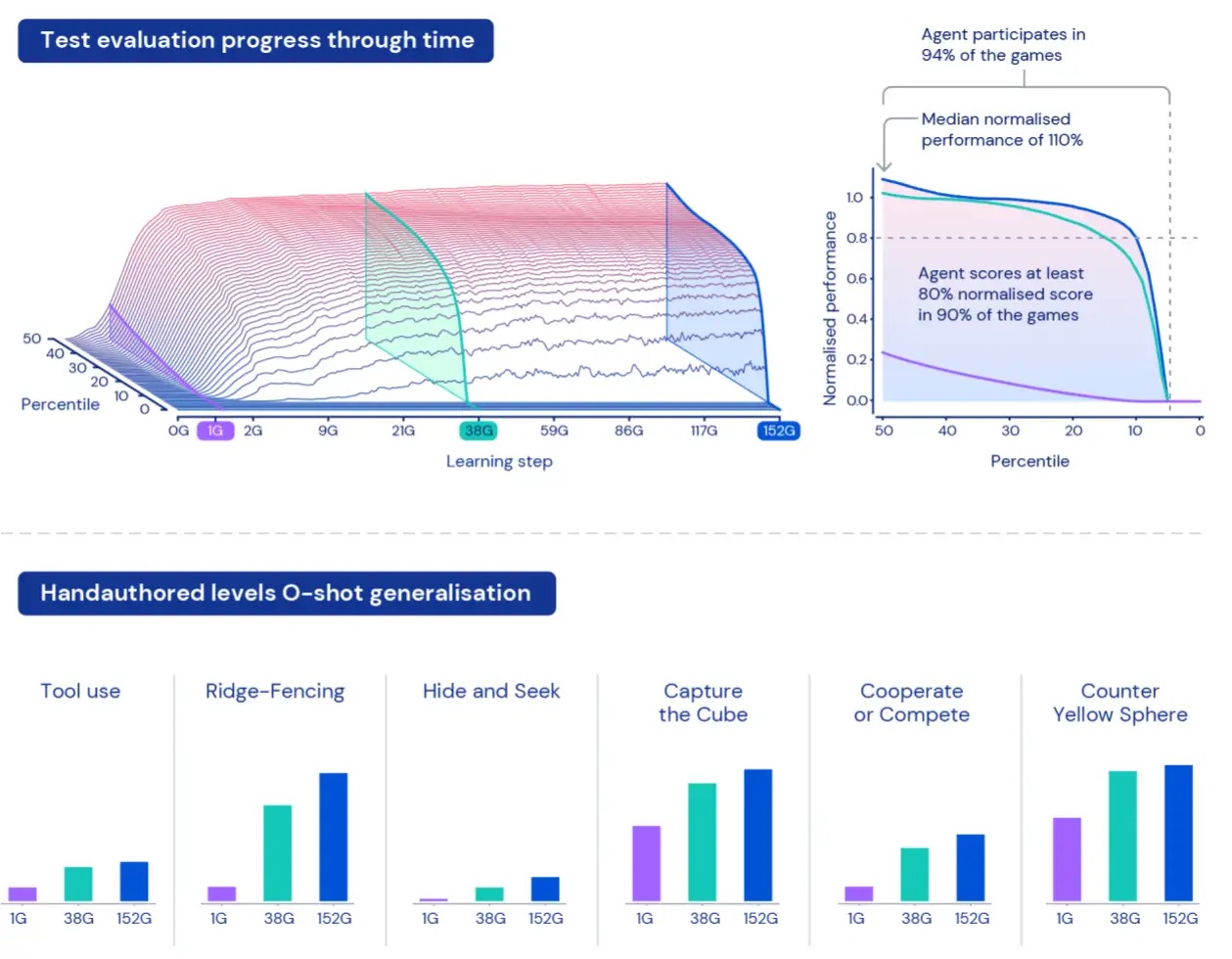
Per misurare le prestazioni degli agenti in questo vasto universo, creiamo una serie di attività di valutazione utilizzando giochi e mondi che rimangono separati dai dati utilizzati per la formazione. Questi compiti “trattenuti” includono compiti specificamente progettati dall’uomo come nascondino e cattura la bandiera.
A causa delle dimensioni di XLand, comprendere e caratterizzare le prestazioni dei nostri agenti può essere una sfida. Ogni compito implica diversi livelli di complessità, diverse scale di ricompense ottenibili e diverse capacità dell’agente, quindi semplicemente calcolare la media della ricompensa rispetto ai compiti assegnati nasconderebbe le reali differenze in termini di complessità e ricompense e tratterebbe effettivamente tutti i compiti come ugualmente interessanti, il che non è necessariamente vero per gli ambienti generati proceduralmente.
Per superare queste limitazioni, adottiamo un approccio diverso. In primo luogo, normalizziamo i punteggi per attività utilizzando il valore di equilibrio di Nash calcolato utilizzando il nostro attuale gruppo di giocatori addestrati. In secondo luogo, prendiamo in considerazione l’intera distribuzione dei punteggi normalizzati – invece di guardare i punteggi medi normalizzati, guardiamo i diversi percentili dei punteggi normalizzati – così come la percentuale di attività in cui l’agente ottiene almeno un livello di ricompensa: partecipazione. Ciò significa che un agente è considerato migliore di un altro solo se supera le prestazioni in tutti i percentili. Questo approccio alla misurazione ci offre un modo significativo per valutare le prestazioni e la robustezza dei nostri agenti.
Agenti più generalmente capaci
Dopo aver formato i nostri agenti per cinque generazioni, abbiamo riscontrato miglioramenti costanti nell’apprendimento e nelle prestazioni in tutto il nostro spazio di valutazione. Giocando a circa 700.000 giochi unici in 4.000 mondi unici all’interno di XLand, ogni agente della generazione finale ha sperimentato 200 miliardi di passaggi di addestramento come risultato di 3,4 milioni di compiti unici. Al momento, i nostri agenti sono stati in grado di partecipare a ogni attività di valutazione generata proceduralmente, ad eccezione di una manciata impossibile anche per un essere umano. E i risultati che stiamo vedendo mostrano chiaramente un comportamento generale, zero-shot in tutto lo spazio delle attività, con la frontiera dei percentili di punteggio normalizzati in continuo miglioramento.
Osservando qualitativamente i nostri agenti, spesso vediamo emergere comportamenti generali ed euristici, piuttosto che comportamenti specifici altamente ottimizzati per compiti individuali. Invece di agenti che conoscono esattamente la “cosa migliore” da fare in una nuova situazione, vediamo prove di agenti che sperimentano e cambiano lo stato del mondo finché non raggiungono uno stato gratificante. Vediamo anche che gli agenti fanno affidamento sull’uso di altri strumenti, inclusi oggetti per occludere la visibilità, creare rampe e recuperare altri oggetti. Poiché l’ambiente è multiplayer, possiamo esaminare la progressione dei comportamenti degli agenti durante l’addestramento in modalità hold-out dilemmi socialicome in un gioco di “pollo”. Con il progredire dell’addestramento, i nostri agenti sembrano mostrare un comportamento più cooperativo quando giocano con una copia di se stessi. Data la natura dell’ambiente, è difficile individuare l’intenzionalità: i comportamenti che vediamo spesso sembrano accidentali, ma li vediamo comunque verificarsi in modo coerente.
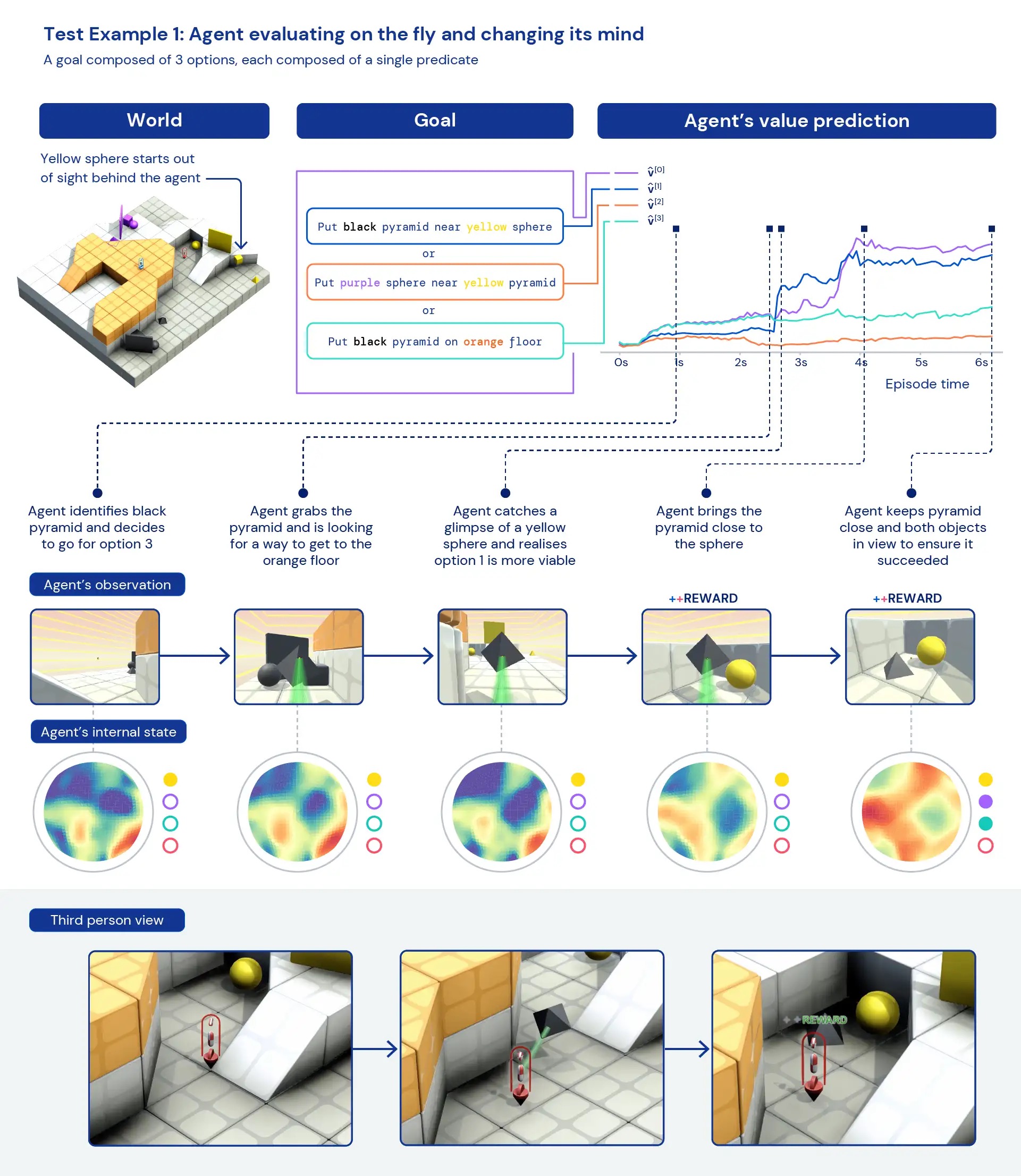
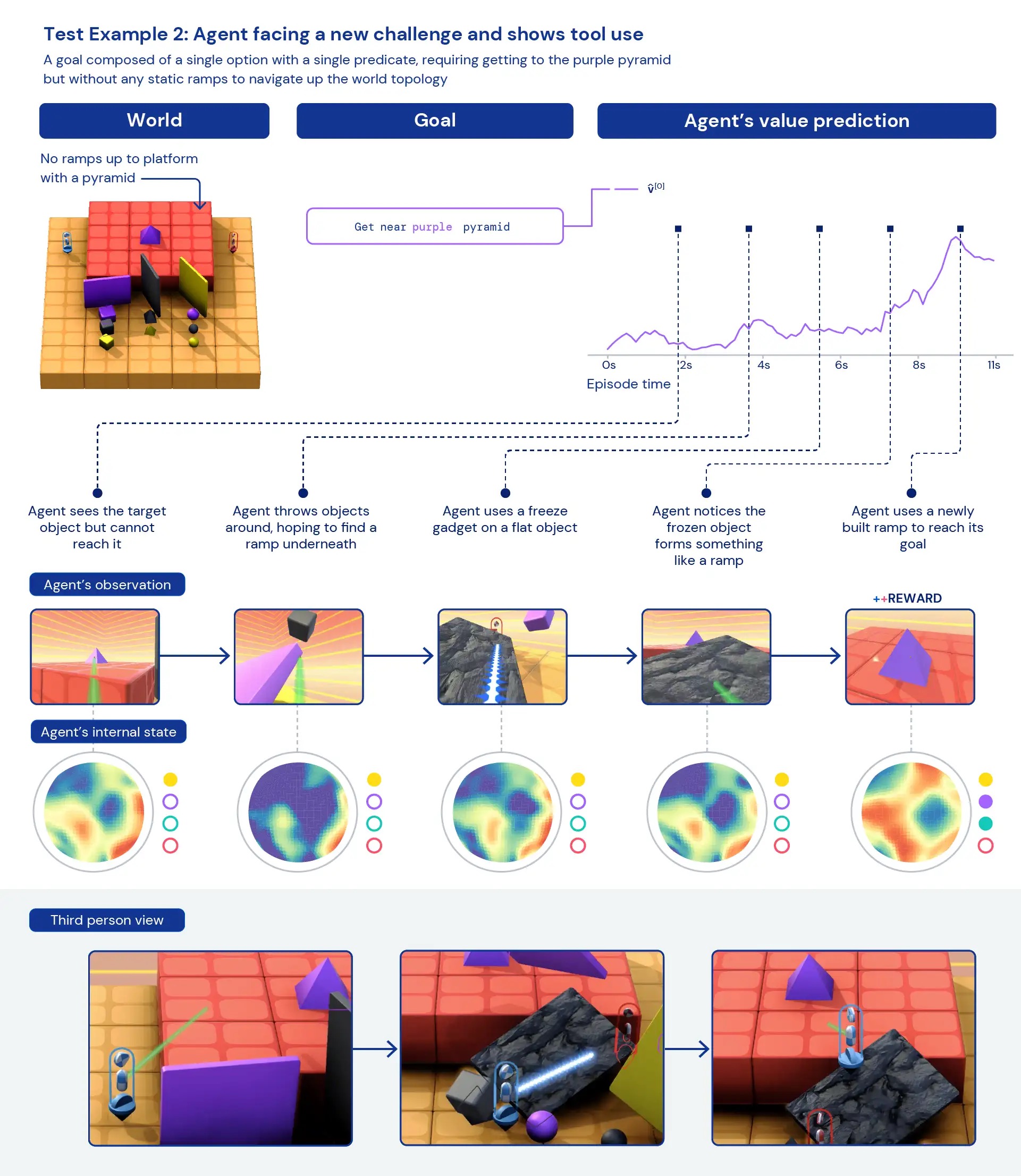
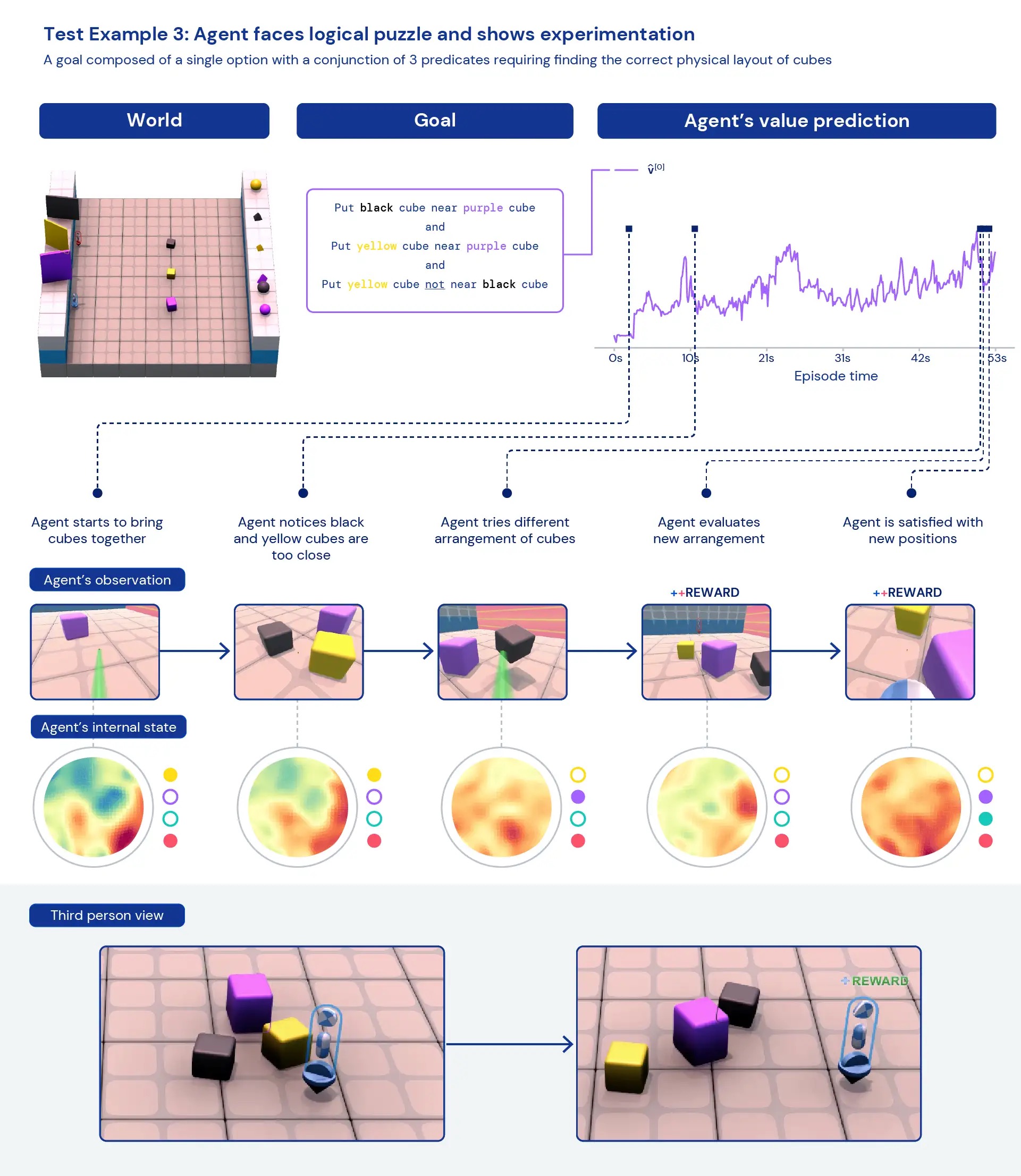



Analizzando le rappresentazioni interne dell’agente, possiamo dire che adottando questo approccio all’apprendimento per rinforzo in un vasto spazio di compiti, i nostri agenti sono consapevoli delle basi del loro corpo e del passare del tempo e comprendono la struttura di alto livello dei giochi incontrano. Forse ancora più interessante, riconoscono chiaramente gli stati di ricompensa del loro ambiente. Questa generalità e diversità di comportamento nei nuovi compiti suggerisce il potenziale per mettere a punto questi agenti sui compiti a valle. Ad esempio, nel documento tecnico mostriamo che con soli 30 minuti di formazione mirata su un compito complesso appena presentato, gli agenti possono adattarsi rapidamente, mentre gli agenti addestrati con RL da zero non possono apprendere affatto questi compiti.
Sviluppando un ambiente come XLand e nuovi algoritmi di addestramento che supportano la creazione di complessità illimitata, abbiamo visto chiari segnali di generalizzazione zero-shot da parte degli agenti RL. Sebbene questi agenti stiano iniziando a essere generalmente capaci in questo ambito di attività, non vediamo l’ora di continuare la nostra ricerca e sviluppo per migliorare ulteriormente le loro prestazioni e creare agenti sempre più adattivi.
Per maggiori dettagli, vedere il prestampa del nostro documento tecnico – E video dei risultati abbiamo visto. Ci auguriamo che questo possa aiutare anche altri ricercatori a vedere un nuovo percorso verso la creazione di agenti IA più adattivi e generalmente capaci. Se sei entusiasta di questi progressi, considera unendosi al nostro team.

