
introduzione
Nel mondo in rapida evoluzione dell'intelligenza artificiale, è fondamentale tenere traccia dei costi API, soprattutto quando si creano applicazioni basate su LLM come Generazione aumentata di recupero (RAG) condutture in produzione. Sperimentare diversi LLM per ottenere i migliori risultati spesso implica effettuare numerose richieste API al server, ciascuna richiesta comportando un costo. Comprendere e monitorare dove viene speso ogni dollaro è fondamentale per gestire queste spese in modo efficace.
In questo articolo implementeremo LLM osservabilità con RAG utilizzando solo 10-12 righe di codice. L'osservabilità ci aiuta a monitorare parametri chiave come latenza, numero di token, richieste e costo per richiesta.
obiettivi formativi
- Comprendere il concetto di osservabilità LLM e come aiuta a monitorare e ottimizzare le prestazioni e i costi dei LLM nelle applicazioni.
- Esplora diversi parametri chiave da monitorare e monitorare, ad esempio l'utilizzo dei token, la latenza, il costo per richiesta e le sperimentazioni tempestive.
- Come costruire una pipeline di generazione aumentata di recupero insieme all'osservabilità.
- Come utilizzare BeyondLLM per valutare ulteriormente la pipeline RAG utilizzando le metriche della triade RAG, ovvero pertinenza del contesto, pertinenza della risposta e fondatezza.
- Adattare saggiamente la dimensione del blocco e i valori top-K per ridurre i costi, utilizzare un numero efficiente di token e migliorare la latenza.
Questo articolo è stato pubblicato come parte del Blogathon sulla scienza dei dati.
Cos'è l'osservabilità LLM?
Pensa all'osservabilità LLM proprio come monitori le prestazioni della tua auto o tieni traccia delle tue spese quotidiane, l'osservabilità LLM implica osservare e comprendere ogni dettaglio di come funzionano questi modelli di intelligenza artificiale. Ti aiuta a tenere traccia dell'utilizzo contando il numero di “token”, unità di elaborazione utilizzate da ciascuna richiesta al modello. Questo ti aiuta a rispettare il budget ed evitare spese impreviste.
Inoltre, monitora le prestazioni registrando il tempo impiegato da ciascuna richiesta, garantendo che nessuna parte del processo sia inutilmente lenta. Fornisce informazioni preziose mostrando modelli e tendenze, aiutandoti a identificare le inefficienze e le aree in cui potresti spendere troppo. L'osservabilità LLM è una best practice da seguire durante la creazione di applicazioni in produzione, in quanto può automatizzare la pipeline delle azioni per inviare avvisi se qualcosa va storto.
Cos'è la generazione aumentata di recupero?
Il Retrieval Augmented Generation (RAG) è un concetto in cui porzioni di documento rilevanti vengono restituite a un Large Language Model (LLM) come apprendimento in-contesto (ovvero, prompt a poche riprese) basato sulla query di un utente. In poche parole, RAG è composto da due parti: il retriever e il generatore.
Quando un utente inserisce una query, questa viene prima convertita in incorporamenti. Questi incorporamenti di query vengono quindi cercati in un database vettoriale dal retriever per restituire i documenti più rilevanti o semanticamente simili. Questi documenti vengono passati come apprendimento in contesto al modello del generatore, consentendo al LLM di generare una risposta ragionevole. RAG riduce la probabilità di allucinazioni e fornisce risposte specifiche del dominio basate sulla base di conoscenze fornita.
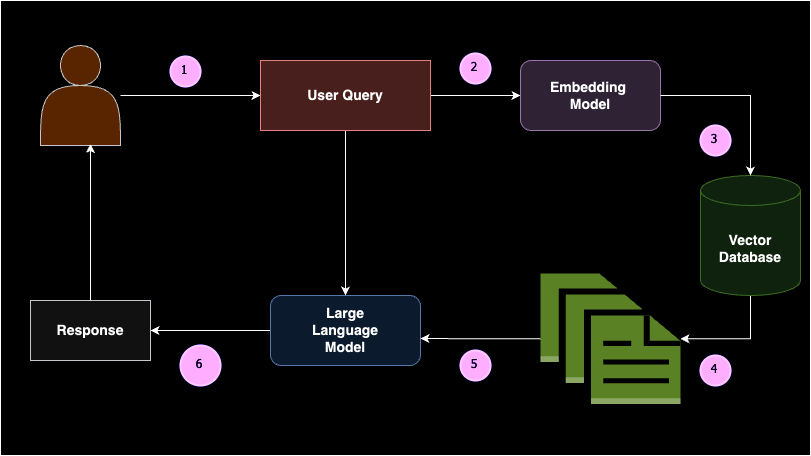
La creazione di una pipeline RAG coinvolge diversi componenti chiave: origine dati, suddivisioni del testo, database vettoriale, modelli di incorporamento e modelli linguistici di grandi dimensioni. RAG è ampiamente implementato quando è necessario connettere un modello linguistico di grandi dimensioni a un'origine dati personalizzata. Ad esempio, se desideri creare il tuo ChatGPT per gli appunti della tua lezione, RAG sarebbe la soluzione ideale. Questo approccio garantisce che il modello possa fornire risposte accurate e pertinenti basate sui dati specifici, rendendolo estremamente utile per applicazioni personalizzate.
Perché utilizzare l'Osservabilità con RAG?
La creazione di un'applicazione RAG dipende da diversi casi d'uso. Ogni caso d'uso dipende dalle proprie istruzioni personalizzate per l'apprendimento nel contesto. I prompt personalizzati includono una combinazione di prompt di sistema e prompt dell'utente, il prompt di sistema rappresenta le regole o le istruzioni in base alle quali LLM deve comportarsi e il prompt dell'utente è il prompt ampliato per la query dell'utente. Scrivere un buon prompt al primo tentativo è un caso molto raro.
L’utilizzo dell’osservabilità con Retrieval Augmented Generation (RAG) è fondamentale per garantire operazioni efficienti ed economicamente vantaggiose. L'osservabilità ti aiuta a monitorare e comprendere ogni dettaglio della tua pipeline RAG, dal monitoraggio dell'utilizzo dei token alla misurazione della latenza, delle richieste e dei tempi di risposta. Tenendo sotto stretto controllo questi parametri, puoi identificare e risolvere le inefficienze, evitare spese impreviste e ottimizzare le prestazioni del tuo sistema. In sostanza, l'osservabilità fornisce le informazioni necessarie per mettere a punto la configurazione RAG, garantendo che funzioni senza intoppi, rispetti il budget e fornisca costantemente risposte accurate e specifiche del dominio.
Facciamo un esempio pratico e capiamo perché è necessario utilizzare l'osservabilità durante l'utilizzo di RAG. Supponiamo che tu abbia creato l'app e ora sia in produzione
Chatta con YouTube: osservabilità con l'implementazione RAG
Esaminiamo ora i passaggi dell'Osservabilità con l'Implementazione RAG.
Passaggio 1: installazione
Prima di procedere con l'implementazione del codice, è necessario installare alcune librerie. Queste librerie includono Oltre il LLM, OpenAI, Fenicee l'API di trascrizione di YouTube. Beyond LLM è una libreria che ti aiuta a creare applicazioni RAG avanzate in modo efficiente, incorporando osservabilità, messa a punto, incorporamenti e valutazione del modello.
pip install beyondllm
pip install openai
pip install arize-phoenix(evals)
pip install youtube_transcript_api llama-index-readers-youtube-transcriptPassaggio 2: imposta la chiave API OpenAI
Configura la variabile di ambiente per la chiave API OpenAI, necessaria per autenticare e accedere ai servizi OpenAI come LLM e incorporamento.
import os, getpass
os.environ('OPENAI_API_KEY') = getpass.getpass("API:")
# import required libraries
from beyondllm import source,retrieve,generator, llms, embeddings
from beyondllm.observe import ObserverPassaggio 3: impostazione dell'osservabilità
L'abilitazione dell'osservabilità dovrebbe essere il primo passaggio nel codice per garantire che tutte le operazioni successive vengano tracciate.
Observe = Observer()
Observe.run()Passaggio 4: definire LLM e incorporamento
Poiché la chiave API OpenAI è già archiviata nella variabile di ambiente, ora puoi definire il modello LLM e di incorporamento per recuperare il documento e generare la risposta di conseguenza.
llm=llms.ChatOpenAIModel()
embed_model = embeddings.OpenAIEmbeddings()Passaggio 5: RAG Parte 1-Retriever
BeyondLLM è un framework nativo per Data Scientist. Per acquisire dati, puoi definire l'origine dati all'interno della funzione “fit”. In base all'origine dati, puoi specificare il `dtype` nel nostro caso è YouTube. Inoltre, possiamo suddividere in blocchi i nostri dati per evitare problemi di lunghezza del contesto del modello e restituire solo il blocco specifico. La sovrapposizione dei blocchi definisce il numero di token che devono essere ripetuti nel blocco consecutivo.
Il recupero automatico in BeyondLLM aiuta a recuperare il numero k rilevante di documenti in base al tipo. Esistono vari tipi di retriever come ibrido, riclassificazione, riclassificazione di incorporamento di flag e altro ancora. In questo caso d'uso utilizzeremo un normale retriever, ovvero un in-memory retriever.
data = source.fit("https://www.youtube.com/watch?v=IhawEdplzkI",
dtype="youtube",
chunk_size=512,
chunk_overlap=50)
retriever = retrieve.auto_retriever(data,
embed_model,
type="normal",
top_k=4)
Passaggio 6: RAG Parte 2-Generatore
Il modello generatore combina la query dell'utente e i documenti rilevanti della classe retriever e li passa al Large Language Model. Per facilitare ciò, BeyondLLM supporta un modulo generatore che concatena questa pipeline, consentendo un'ulteriore valutazione della pipeline sulla triade RAG.
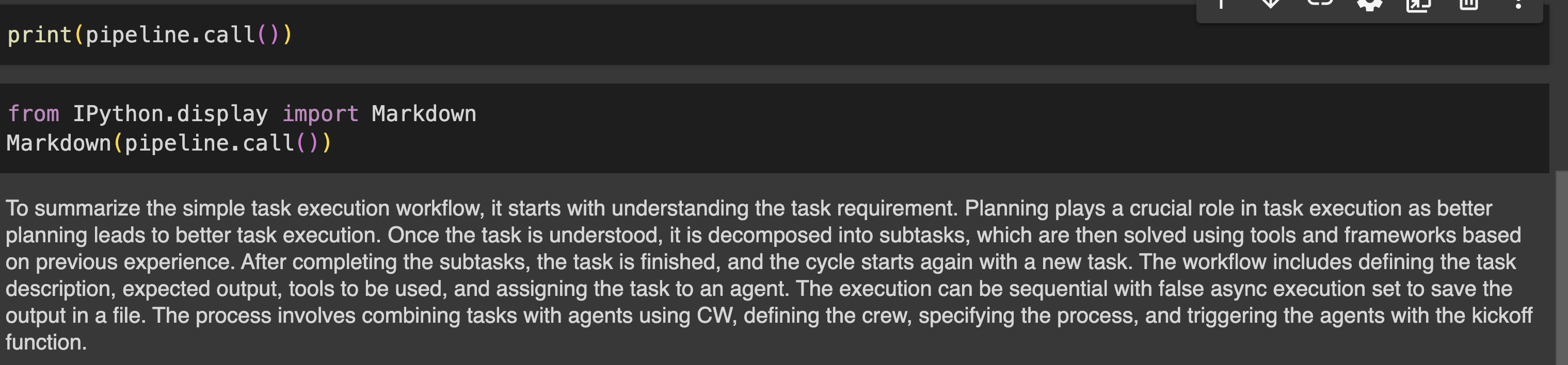
user_query = "summarize simple task execution worflow?"
pipeline = generator.Generate(question=user_query,retriever=retriever,llm=llm)
print(pipeline.call())Produzione
Passaggio 7: valutare la pipeline
La valutazione della pipeline RAG può essere eseguita utilizzando le metriche della triade RAG che includono pertinenza del contesto, pertinenza della risposta e fondatezza.
- Rilevanza del contesto : misura la pertinenza dei blocchi recuperati da auto_retriever in relazione alla query dell'utente. Determina l'efficienza di auto_retriever nel recuperare informazioni contestualmente rilevanti, garantendo che le basi per la generazione di risposte siano solide.
- Pertinenza della risposta : valuta la pertinenza della risposta di LLM alla query dell'utente.
- Radicamento : Determina quanto bene le risposte del modello linguistico sono radicate nelle informazioni recuperate dall'auto_retriever, con l'obiettivo di identificare ed eliminare qualsiasi contenuto allucinatorio. Ciò garantisce che i risultati siano basati su informazioni accurate e fattuali.
print(pipeline.get_rag_triad_evals())
#or
# run it individually
print(pipeline.get_context_relevancy()) # context relevancy
print(pipeline.get_answer_relevancy()) # answer relevancy
print(pipeline.get_groundedness()) # groundednessProduzione:

Phoenix Dashboard: analisi dell'osservabilità LLM
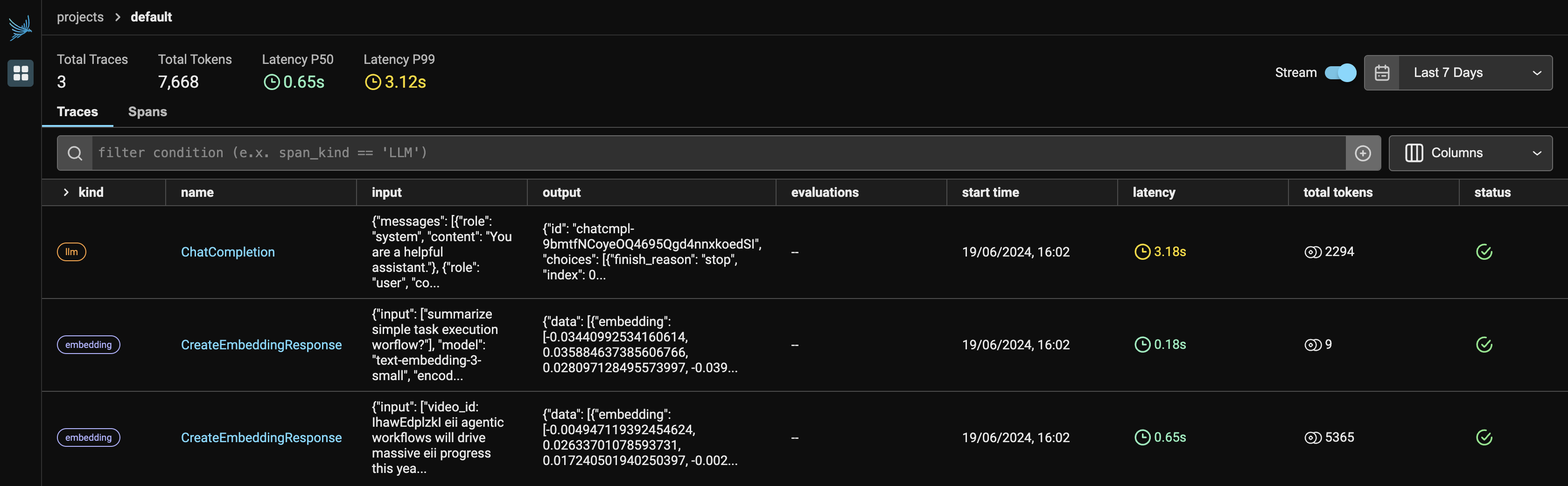
La Figura-1 indica il dashboard principale di Phoenix, una volta eseguito Observer.run(), restituisce due collegamenti:
- Host locale: http://127.0.0.1:6006/
- Se localhost non è in esecuzione, puoi scegliere un collegamento alternativo per visualizzare l'app Phoenix nel tuo browser.
Poiché stiamo utilizzando due servizi di OpenAI, verranno visualizzati sia LLM che gli incorporamenti sotto il provider. Mostrerà il numero di token utilizzati da ciascun provider, insieme alla latenza, all'ora di inizio, all'input fornito alla richiesta API e all'output generato da LLM.
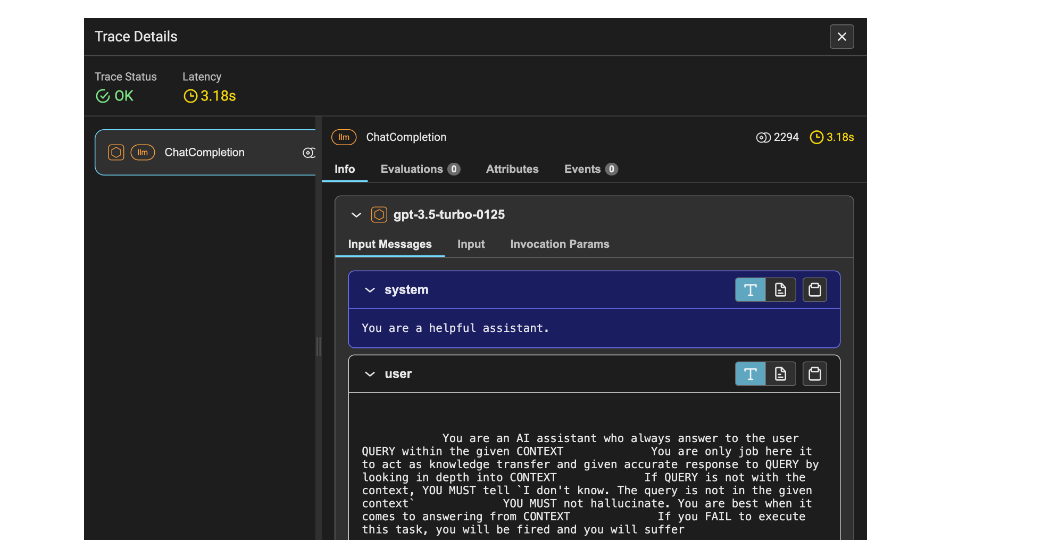
La Figura 2 mostra i dettagli della traccia del LLM. Include la latenza, pari a 1,53 secondi, il numero di token, pari a 2212, e informazioni quali il prompt del sistema, il prompt dell'utente e la risposta.
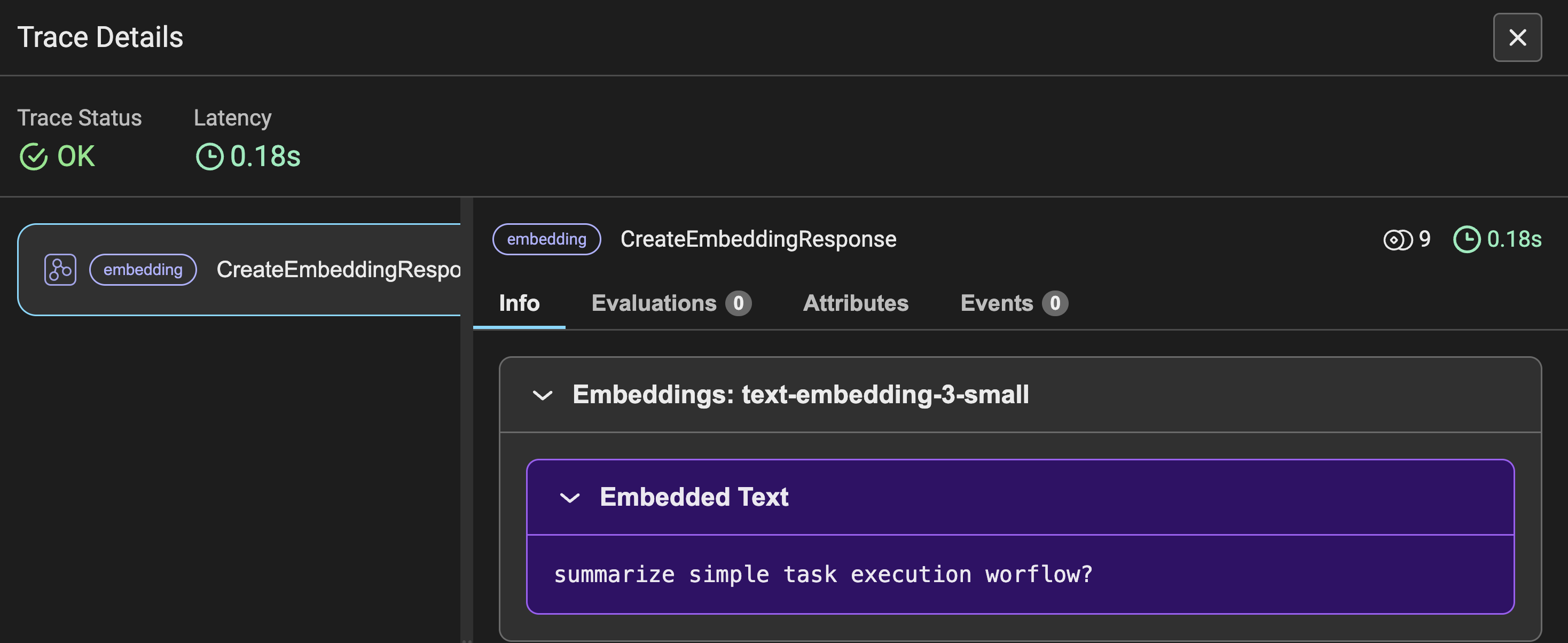
La Figura 3 mostra i dettagli della traccia degli incorporamenti per la query richiesta dall'utente, insieme ad altri parametri simili alla Figura 2. Invece della richiesta, vedi la query di input convertita in incorporamenti.
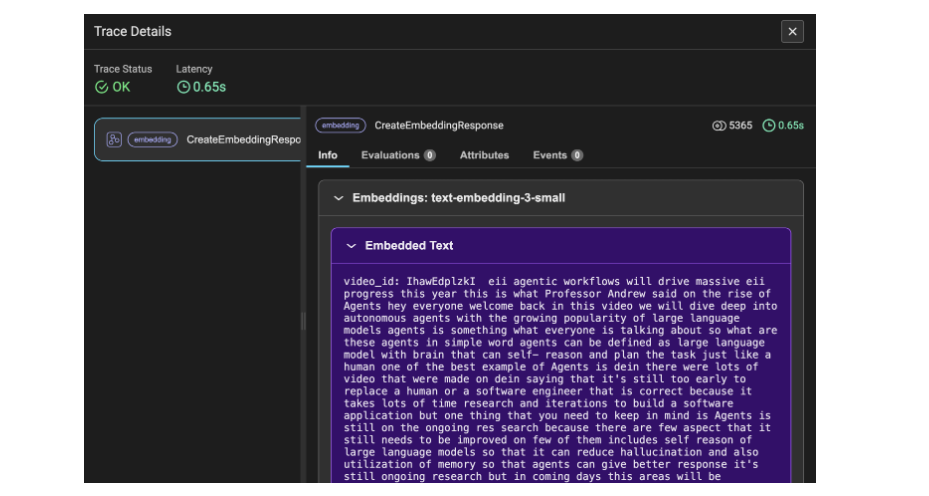
La Figura 4 mostra i dettagli della traccia degli incorporamenti per i dati della trascrizione di YouTube. Qui i dati vengono convertiti in blocchi e quindi in incorporamenti, motivo per cui i token utilizzati ammontano a 5365. Questo dettaglio della traccia indica i dati video della trascrizione come informazioni.
Conclusione
Per riassumere, hai creato con successo una pipeline di Retrieval Augmented Generation (RAG) insieme a concetti avanzati come valutazione e osservabilità. Con questo approccio, puoi utilizzare ulteriormente l'apprendimento per automatizzare e scrivere script per gli avvisi se qualcosa va storto o utilizzare le richieste per tracciare i dettagli di registrazione per ottenere informazioni migliori sulle prestazioni dell'applicazione e, ovviamente, mantenere i costi all'interno del bilancio. Inoltre, incorporare l'osservabilità ti aiuta a ottimizzare l'utilizzo del modello e garantisce prestazioni efficienti ed economicamente vantaggiose per le tue esigenze specifiche.
Punti chiave
- Comprendere la necessità di osservabilità durante la creazione di applicazioni basate su LLM come la generazione aumentata di recupero.
- Metriche chiave da tracciare come numero di token, latenza, richieste e costi per ogni richiesta API effettuata.
- Implementazione di valutazioni RAG e triadi utilizzando BeyondLLM con righe di codice minime.
- Monitoraggio e tracciamento dell'osservabilità LLM utilizzando BeyondLLM e Phoenix.
- Pochi insight istantanei sui dettagli di traccia di LLM e incorporamenti che devono essere automatizzati per migliorare le prestazioni dell'applicazione.
Domande frequenti
R. Quando si tratta di osservabilità, è utile tenere traccia di modelli closed source come GPT, Gemini, Claude e altri. Phoenix supporta integrazioni dirette con Langchain, LLamaIndex e il framework DSPY, nonché con fornitori LLM indipendenti come OpenAI, Bedrock e altri.
R. BeyondLLM supporta la valutazione della pipeline Retrieval Augmented Generation (RAG) utilizzando i LLM supportati. Puoi facilmente valutare RAG su BeyondLLM con i modelli Ollama e HuggingFace. Le metriche di valutazione includono la pertinenza del contesto, la pertinenza della risposta, la fondatezza e la verità fondamentale.
R. Il costo dell'API OpenAI viene speso in base al numero di token utilizzati. È qui che l'osservabilità può aiutarti a mantenere il monitoraggio e la traccia di token per richiesta, token complessivi, costi per richiesta, latenza. Queste metriche aiutano davvero ad attivare una funzione per avvisare il costo all'utente.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
Fonte: www.analyticsvidhya.com

