
Oggi stiamo lanciando una prima versione di Gemelli 2.5 flash In anteprima Attraverso l'API Gemelli via Google per studiare E Vertex ai. Basandosi sulla popolare fondazione di 2.0 Flash, questa nuova versione offre un importante aggiornamento delle capacità di ragionamento, pur dando la priorità alla velocità e al costo. Gemini 2.5 Flash è il nostro primo modello di ragionamento completamente ibrido, dando agli sviluppatori la possibilità di attivare o disattivare. Il modello consente inoltre agli sviluppatori di impostare i budget di pensiero per trovare il giusto compromesso tra qualità, costo e latenza. Anche con pensando, Gli sviluppatori possono mantenere la velocità rapida di 2.0 flash e migliorare le prestazioni.
I nostri modelli Gemini 2.5 sono modelli pensanti, in grado di ragionare attraverso i loro pensieri prima di rispondere. Invece di generare immediatamente un output, il modello può eseguire un processo di “pensiero” per comprendere meglio il prompt, abbattere compiti complessi e pianificare una risposta. Su compiti complessi che richiedono più passaggi di ragionamento (come risolvere i problemi di matematica o analizzare le domande di ricerca), il processo di pensiero consente al modello di arrivare a risposte più accurate e complete. In effetti, Gemini 2.5 Flash funziona fortemente Prommette difficili in LMarenaSecondo solo a 2,5 Pro.
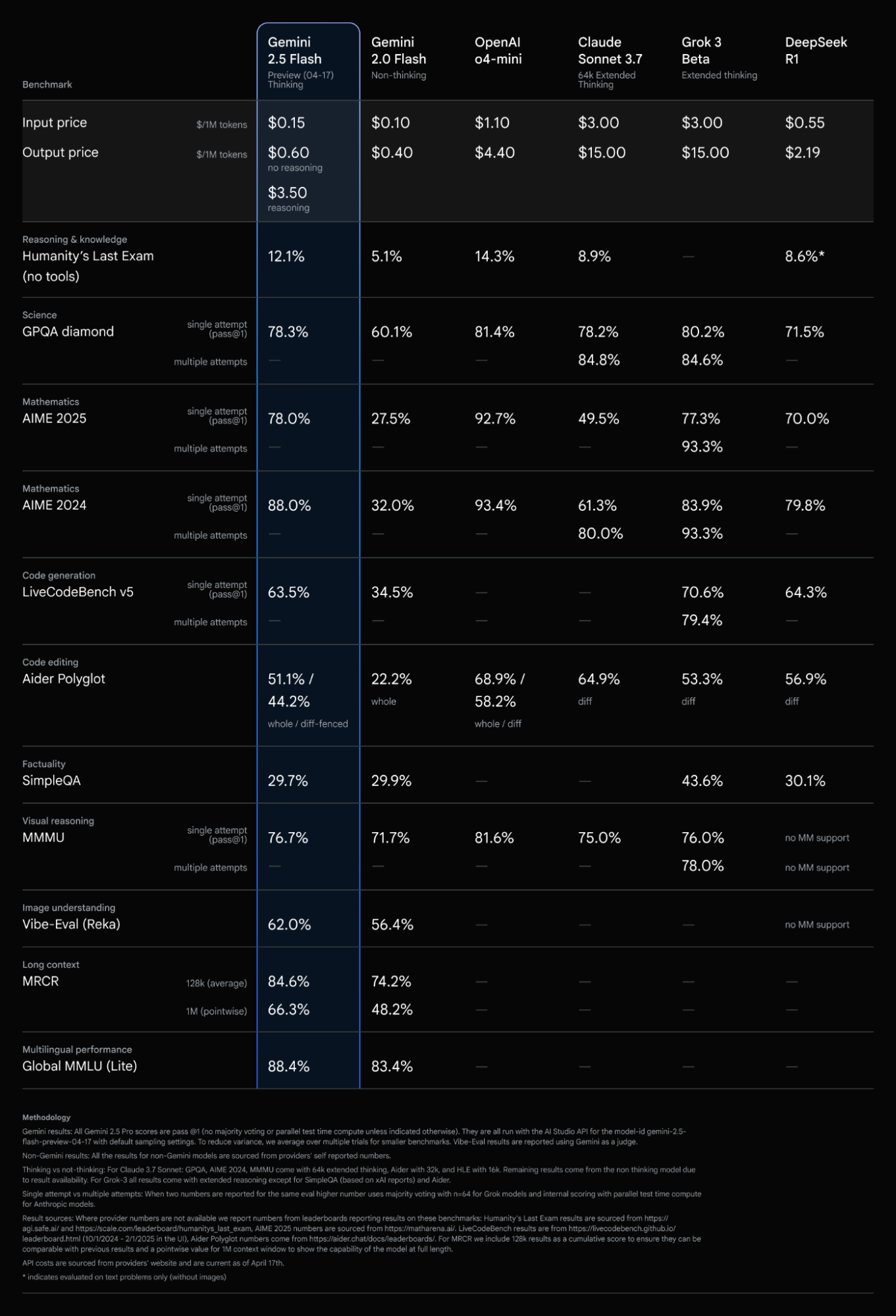
2.5 Flash ha metriche comparabili con altri modelli leader per una frazione del costo e delle dimensioni.
Il nostro modello di pensiero più economico
2.5 Flash continua a condurre come modello con il miglior rapporto prezzo / prestazione.
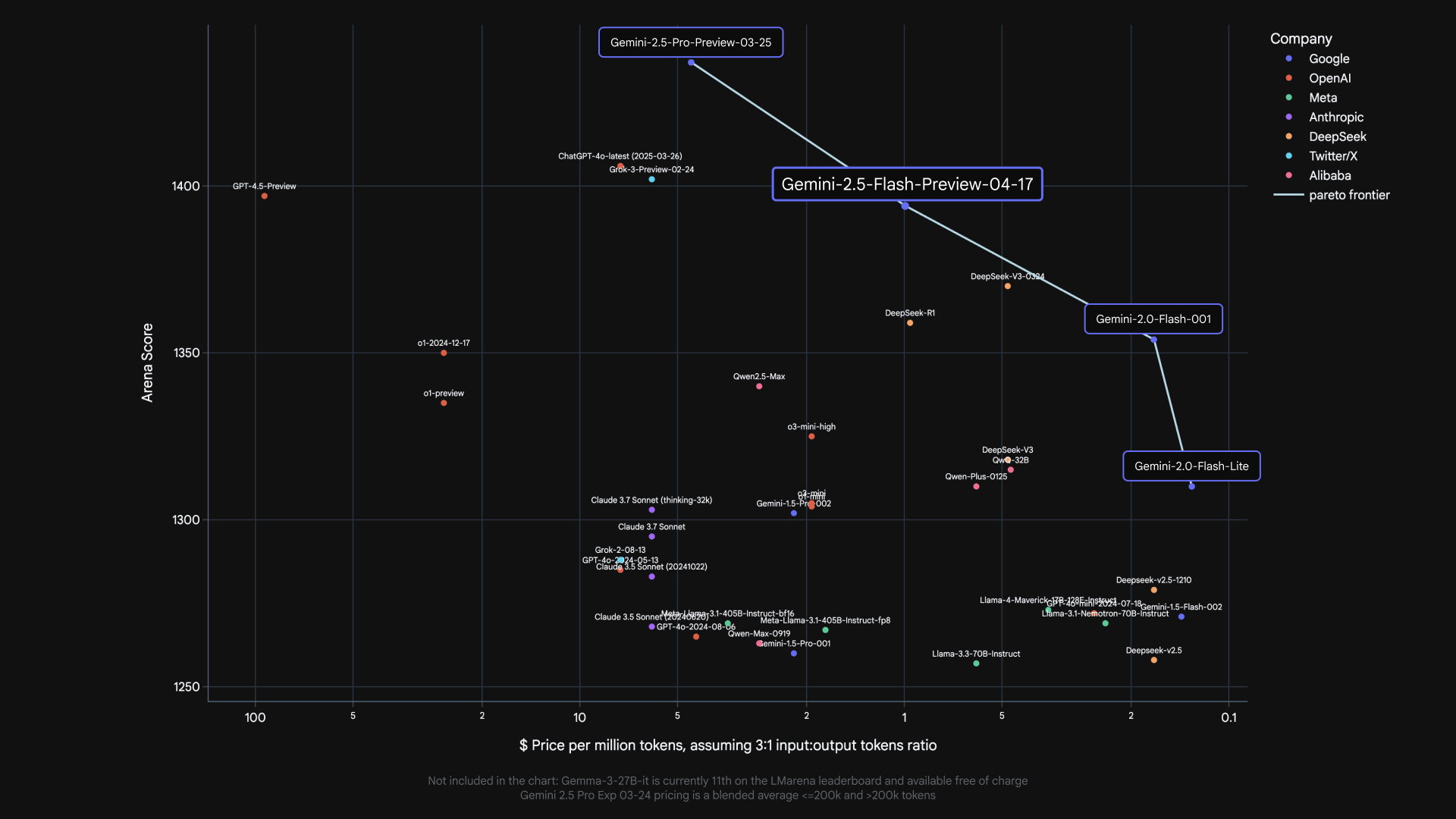
Gemini 2.5 Flash aggiunge un altro modello a Pareto Frontier di Google Costo alla qualità.*
Controlli a grana fine per gestire il pensiero
Sappiamo che diversi casi d'uso hanno diversi compromessi in termini di qualità, costi e latenza. Per offrire agli sviluppatori flessibilità, abbiamo abilitato l'impostazione a budget di pensiero Ciò offre un controllo a grana fine sul numero massimo di token che un modello può generare durante il pensiero. Un budget più elevato consente al modello di ragionare ulteriormente per migliorare la qualità. È importante sottolineare, tuttavia, che il budget imposta un limite su quanto 2,5 flash può pensare, ma il modello non utilizza il budget completo se il prompt non lo richiede.
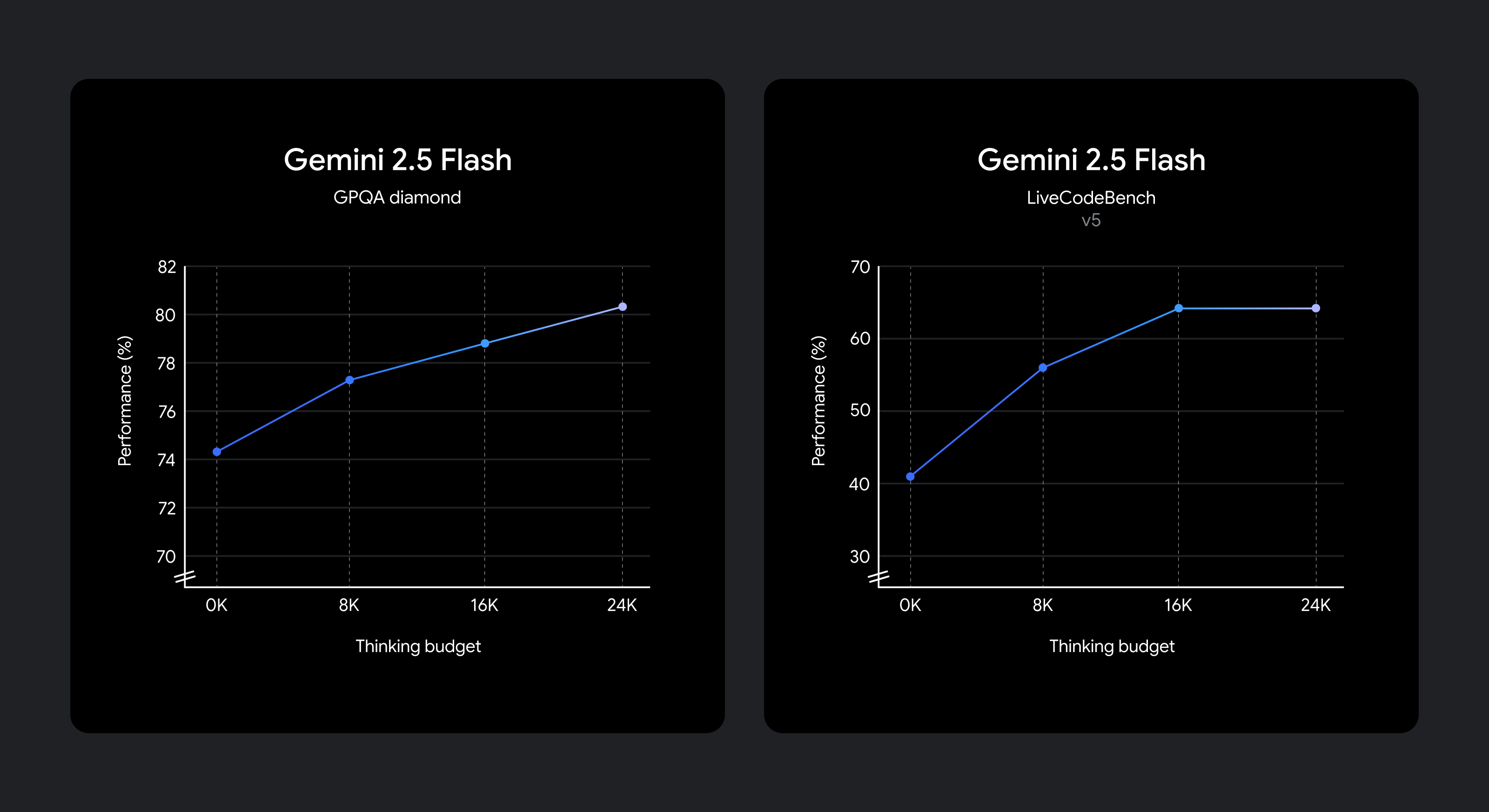
Miglioramenti nella qualità del ragionamento all'aumentare del budget di pensiero.
Il modello è addestrato a sapere per quanto tempo pensare per un determinato prompt e quindi decide automaticamente quanto pensare in base alla complessità delle attività percepite.
Se si desidera mantenere il costo e la latenza più basso, migliorando le prestazioni oltre 2,0 flash, Imposta il budget di pensiero su 0. Puoi anche scegliere di farlo Imposta un budget specifico del token Per la fase di pensiero utilizzando un parametro nell'API o nel cursore in Google AI Studio e in Vertex AI. Il budget può variare da 0 a 24576 token per 2,5 flash.
I seguenti istruzioni dimostrano quanto ragionamento può essere utilizzato nella modalità predefinita di 2.5 Flash.
Richiede un ragionamento basso:
Esempio 1: “Grazie” in spagnolo
Esempio 2: Quante province ha il Canada?
Richiede che richiedono un ragionamento medio:
Esempio 1: Tiri due dadi. Qual è la probabilità che aggiungono fino a 7?
Esempio 2: La mia palestra ha ore di raccolta per il basket tra le 21:00 alle 15:00 su MWF e tra le 14:00 di martedì e sabato. Se lavoro dalle 9 alle 18 5 giorni alla settimana e voglio giocare a 5 ore di basket nei giorni feriali, crea un programma per me per far funzionare tutto.
Richiede un ragionamento elevato:
Esempio 1: Un raggio a sbalzo di lunghezza l = 3M ha una sezione trasversale rettangolare (larghezza B = 0,1 m, altezza H = 0,2 m) ed è realizzato in acciaio (E = 200 GPa). È sottoposto a un carico uniformemente distribuito W = 5 kN/m lungo l'intera lunghezza e un carico punto p = 10 kN all'estremità libera. Calcola la massima sollecitazione di flessione (σ_max).
Esempio 2: Scrivi una funzione evaluate_cells(cells: Dict(str, str)) -> Dict(str, float) Ciò calcola i valori delle celle del foglio di calcolo.
Ogni cella contiene:
- O una formula come
"=A1 + B1 * 2"usando+,-,*,/e altre cellule.
Requisiti:
- Risolvi le dipendenze tra le cellule.
- La precedenza dell'operatore maneggevole (
*/Prima+-).
- Rileva i cicli e aumenta
ValueError("Cycle detected at.") |
- NO
eval(). Usa solo librerie integrate.
Inizia a costruire con Gemini 2.5 Flash oggi
Gemini 2.5 Flash con funzionalità di pensiero è ora disponibile in anteprima tramite il API GEMINI In Google per studiare e in Vertex aie in un discesa dedicato nel App Gemini. Ti incoraggiamo a sperimentare il thinking_budget Parametro ed esplorare come il ragionamento controllabile può aiutarti a risolvere problemi più complessi.
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.text)
Trova riferimenti API dettagliati e guide di pensiero nel nostro Documenti sviluppatori o iniziare con Esempi di codice da Libro di cucina Gemelli.
Continueremo a migliorare il flash Gemini 2.5, con altri in arrivo, prima di renderlo generalmente disponibile per l'uso completo della produzione.
*I prezzi del modello sono provenienti da analisi artificiale e documentazione aziendale
Fonte: deepmind.google

