
Nel panorama in rapida evoluzione dei modelli linguistici di grandi dimensioni (LLM), i riflettori si sono concentrati in gran parte sull’architettura basata solo sul decodificatore. Sebbene questi modelli abbiano mostrato capacità impressionanti in un’ampia gamma di attività di generazione, la classica architettura codificatore-decodificatore, come T5 (The Text-to-Text Transfer Transformer), rimane una scelta popolare per molte applicazioni del mondo reale. I modelli codificatore-decodificatore spesso eccellono nel riepilogo, nella traduzione, nel QA e altro ancora grazie alla loro elevata efficienza di inferenza, flessibilità di progettazione e rappresentazione del codificatore più ricca per la comprensione dell’input. Tuttavia, la potente architettura codificatore-decodificatore ha ricevuto poca attenzione relativa.
Oggi rivisitiamo questa architettura e la introduciamo T5Gemmauna nuova raccolta di LLM codificatore-decodificatore sviluppata convertendo modelli di solo decodificatore preaddestrati nell’architettura codificatore-decodificatore attraverso una tecnica chiamata adattamento. T5Gemma si basa sul framework Gemma 2, inclusi i modelli Gemma 2 2B e 9B adattati, nonché una serie di modelli di dimensioni T5 appena addestrati (Small, Base, Large e XL). Siamo entusiasti di rilasciare alla comunità modelli T5Gemma preaddestrati e ottimizzati per le istruzioni per sbloccare nuove opportunità di ricerca e sviluppo.
Dal solo decoder all’encoder-decoder
In T5Gemma, poniamo la seguente domanda: possiamo creare modelli di codificatore-decodificatore di alto livello basati su modelli di soli decodificatori preaddestrati? Rispondiamo a questa domanda esplorando una tecnica chiamata adattamento del modello. L’idea principale è inizializzare i parametri di un modello di codificatore-decodificatore utilizzando i pesi di un modello di solo decodificatore già preaddestrato e quindi adattarli ulteriormente tramite pre-addestramento basato su UL2 o PrefixLM.
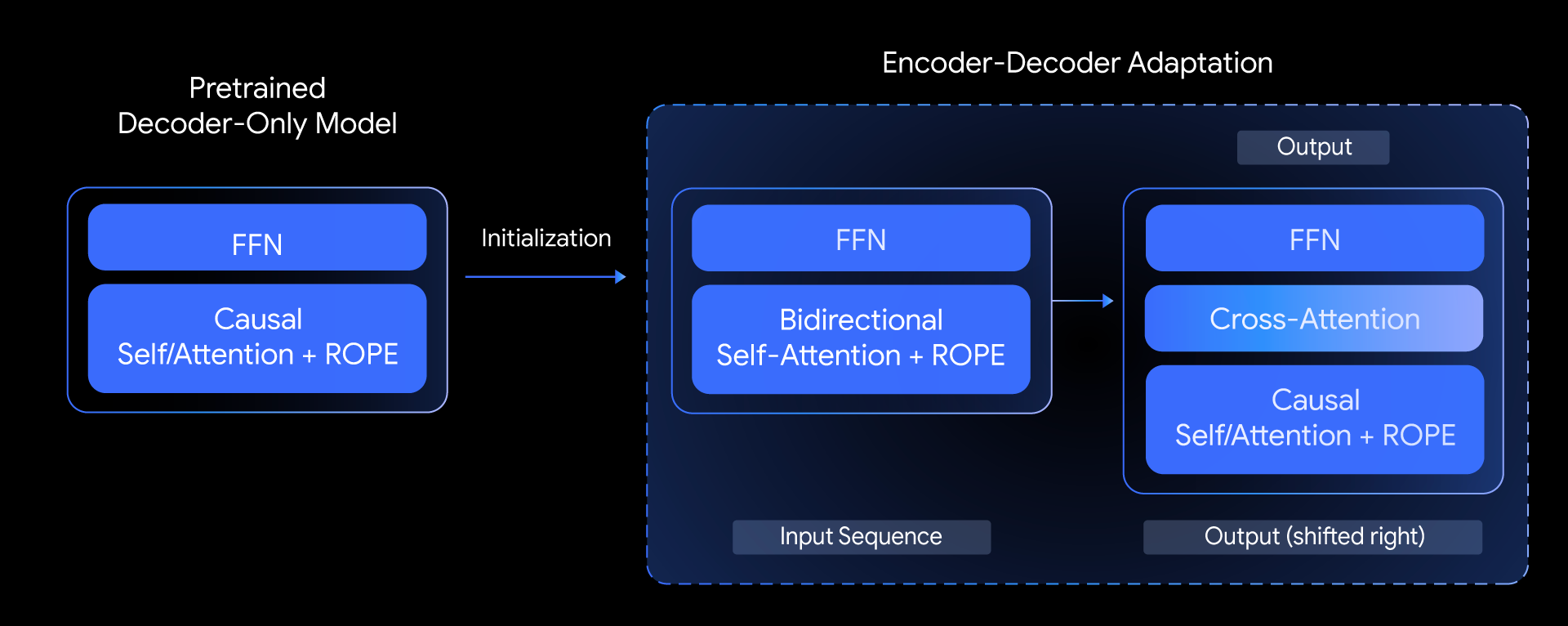
Una panoramica del nostro approccio, che mostra come inizializziamo un nuovo modello di codificatore-decodificatore utilizzando i parametri di un modello preaddestrato di solo decodificatore.
Questo metodo di adattamento è altamente flessibile e consente combinazioni creative di dimensioni del modello. Ad esempio, possiamo accoppiare un codificatore grande con un decoder piccolo (ad esempio, un codificatore 9B con un decoder 2B) per creare un modello “sbilanciato”. Ciò ci consente di ottimizzare il compromesso qualità-efficienza per attività specifiche, come il riepilogo, dove una comprensione approfondita dell’input è più critica della complessità dell’output generato.
Verso un migliore compromesso qualità-efficienza
Come si comporta T5Gemma?
Nei nostri esperimenti, i modelli T5Gemma raggiungono prestazioni paragonabili o migliori rispetto alle loro controparti Gemma solo decodificatore, quasi dominando la frontiera pareto dell’efficienza dell’inferenza della qualità attraverso diversi benchmark, come SuperGLUE che misura la qualità della rappresentazione appresa.
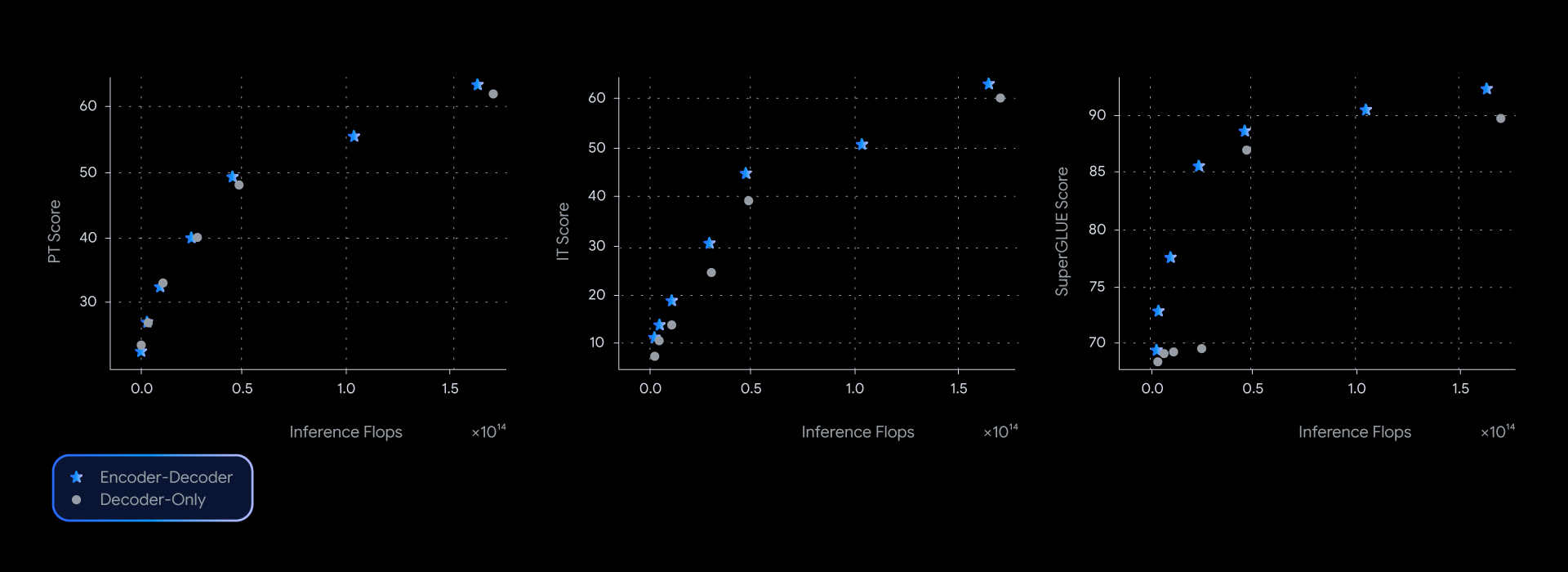
I modelli codificatore-decodificatore offrono costantemente prestazioni migliori per un dato livello di calcolo di inferenza, guidando la frontiera dell’efficienza della qualità in una serie di parametri di riferimento.
Questo vantaggio prestazionale non è solo teorico; si traduce anche in qualità e velocità nel mondo reale. Misurando la latenza effettiva per GSM8K (ragionamento matematico), T5Gemma ha fornito una chiara vittoria. Ad esempio, T5Gemma 9B-9B raggiunge una precisione maggiore rispetto a Gemma 2 9B ma con una latenza simile. Ancora più impressionante, T5Gemma 9B-2B offre un significativo incremento di precisione rispetto al modello 2B-2B, ma la sua latenza è quasi identica al modello Gemma 2 2B molto più piccolo. In definitiva, questi esperimenti dimostrano che l’adattamento codificatore-decodificatore offre un modo flessibile e potente per bilanciare qualità e velocità di inferenza.
Sbloccare funzionalità fondamentali e ottimizzate
Gli LLM codificatore-decodificatore potrebbero avere funzionalità simili ai modelli solo decodificatore?
Sì, T5Gemma mostra capacità promettenti sia prima che dopo la messa a punto delle istruzioni.
Dopo il pre-addestramento, T5Gemma ottiene risultati impressionanti su compiti complessi che richiedono ragionamento. Ad esempio, T5Gemma 9B-9B ottiene punteggi più alti di oltre 9 punti su GSM8K (ragionamento matematico) e 4 punti più alti su DROP (comprensione della lettura) rispetto al modello originale Gemma 2 9B. Questo modello dimostra che l’architettura codificatore-decodificatore, una volta inizializzata tramite adattamento, ha il potenziale per creare un modello fondamentale più capace e performante.
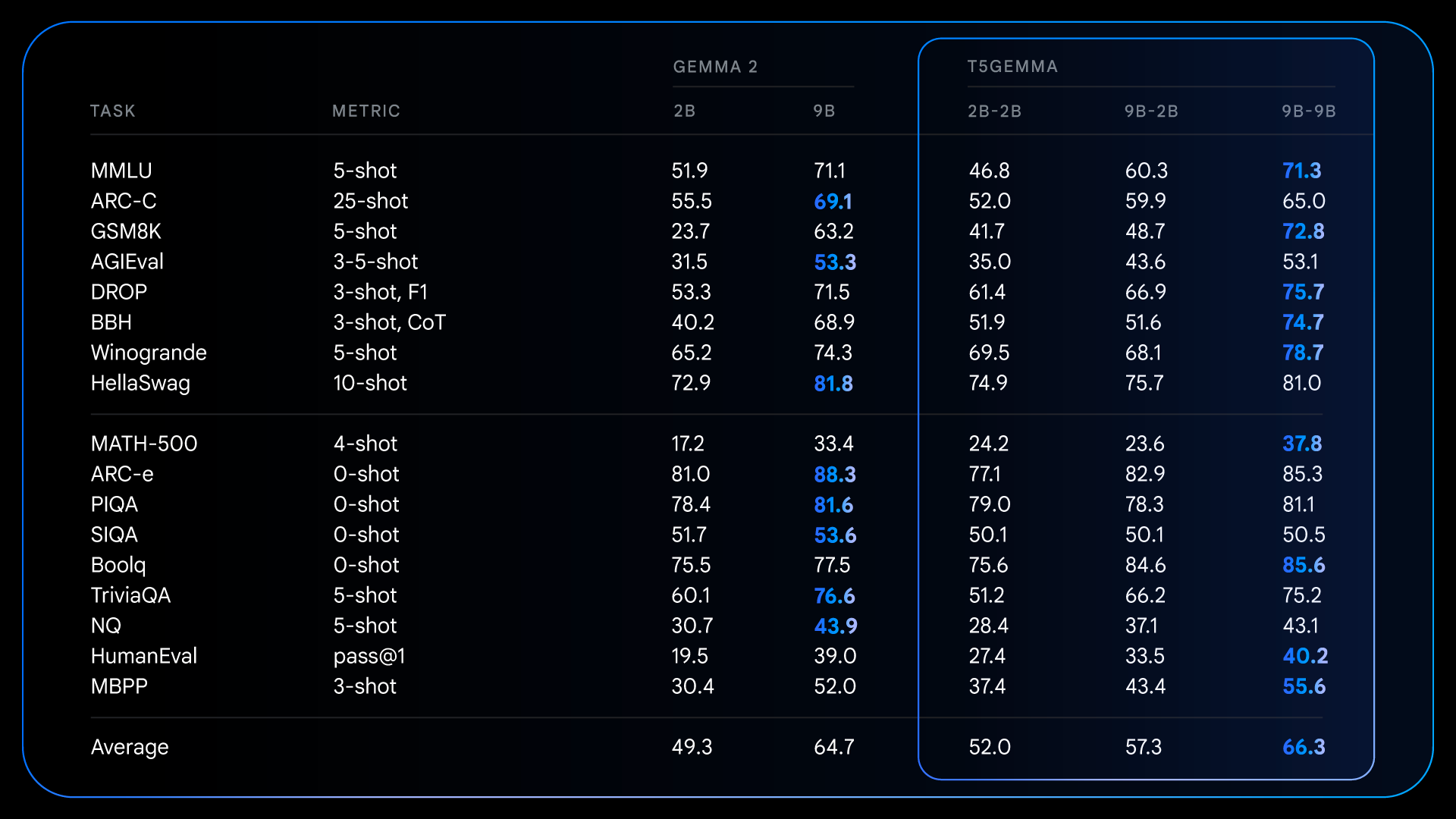
Risultati dettagliati per modelli preaddestrati, che illustrano come i modelli adattati apportano vantaggi significativi su diversi benchmark ad alta intensità di ragionamento rispetto a Gemma 2 con solo decodificatore.
Questi miglioramenti fondamentali apportati prima della formazione preparano il terreno per guadagni ancora più notevoli dopo la messa a punto delle istruzioni. Ad esempio, confrontando Gemma 2 IT con T5Gemma IT, il divario prestazionale si allarga significativamente su tutta la linea. T5Gemma 2B-2B IT vede il suo punteggio MMLU balzare di quasi 12 punti rispetto al Gemma 2 2B, e il suo punteggio GSM8K aumenta dal 58,0% al 70,7%. L’architettura adattata non solo fornisce potenzialmente un punto di partenza migliore, ma risponde anche in modo più efficace alla messa a punto delle istruzioni, portando in definitiva a un modello finale sostanzialmente più capace e utile.
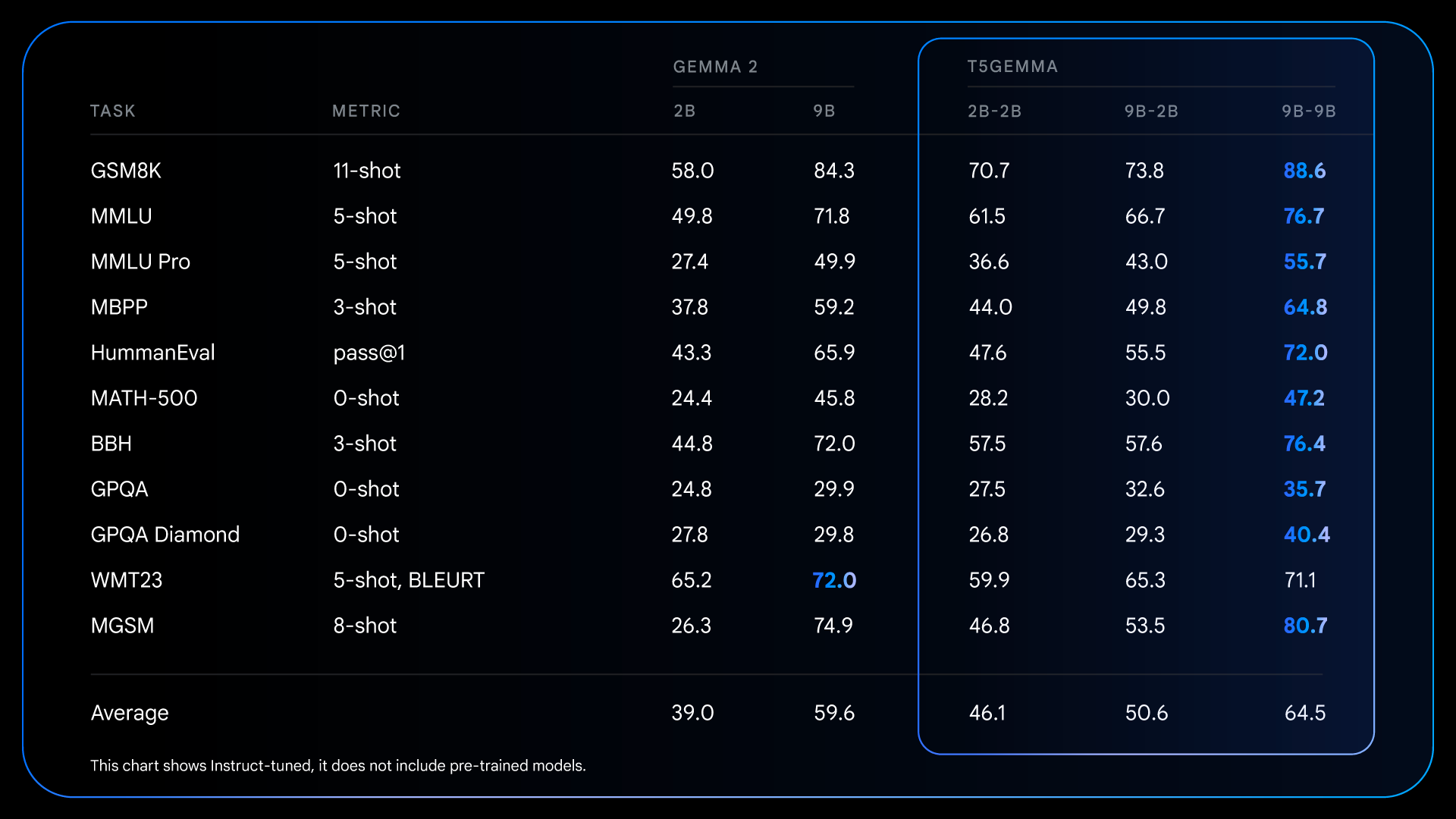
Risultati dettagliati per modelli ottimizzati + RLHF, che illustrano le capacità del post-addestramento per amplificare in modo significativo i vantaggi prestazionali dell’architettura codificatore-decodificatore.
Esplora i nostri modelli: rilascio dei checkpoint T5Gemma
Siamo molto entusiasti di presentare questo nuovo metodo per creare modelli di codificatore-decodificatore potenti e generici adattandoci da LLM preaddestrati solo per decodificatore come Gemma 2. Per contribuire ad accelerare ulteriori ricerche e consentire alla comunità di sviluppare questo lavoro, siamo entusiasti di rilasciare una suite dei nostri checkpoint T5Gemma.
Il rilascio include:
- Dimensioni multiple: Checkpoint per i modelli di dimensione T5 (Small, Base, Large e XL), i modelli basati su Gemma 2 (2B e 9B), nonché un modello aggiuntivo tra T5 Large e T5 XL.
- Molteplici varianti: Modelli preaddestrati e ottimizzati per le istruzioni.
- Configurazioni flessibili: Un checkpoint 9B-2B sbilanciato potente ed efficiente per esplorare i compromessi tra dimensioni del codificatore e del decodificatore.
- Diversi obiettivi formativi: Modelli addestrati con obiettivi PrefixLM o UL2 per fornire prestazioni generative o qualità di rappresentazione all’avanguardia.
Ci auguriamo che questi checkpoint forniscano una risorsa preziosa per studiare l’architettura, l’efficienza e le prestazioni del modello.
Iniziare con T5Gemma
Non vediamo l’ora di vedere cosa costruirai con T5Gemma. Per ulteriori informazioni, consultare i seguenti collegamenti:
- Scopri la ricerca alla base di questo progetto leggendo la carta.
- Esplora le funzionalità dei modelli o ottimizzali per i tuoi casi d’uso con Taccuino di Colab.
Fonte: deepmind.google

