
IL primo modello Gemma lanciato all’inizio dello scorso anno e da allora è diventato un fiorente Versetto di Gemma di oltre 160 milioni di download collettivi. Questo ecosistema include la nostra famiglia di oltre una dozzina di modelli specializzati per qualsiasi cosa, dalla protezione alle applicazioni mediche e, cosa più stimolante, le innumerevoli innovazioni della comunità. Da innovatori come Roboflusso costruire la visione artificiale aziendale per Istituto delle Scienze di Tokio creando varianti Gemma giapponesi altamente capaci, il tuo lavoro ci ha mostrato la strada da seguire.
Forte di questo incredibile slancio, siamo entusiasti di annunciare il rilascio completo di Gemma 3n. Mentre anteprima del mese scorso offerto uno sguardo, oggi sblocca tutta la potenza di questa architettura mobile-first. Gemma 3n è progettato per la comunità di sviluppatori che ha contribuito a plasmare Gemma. È supportato dai tuoi strumenti preferiti, tra cui Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX e molti altri, consentendoti di ottimizzare e distribuire con facilità le tue applicazioni specifiche sul dispositivo. Questo post è l’approfondimento degli sviluppatori: esploreremo alcune delle innovazioni dietro Gemma 3n, condivideremo nuovi risultati di benchmark e ti mostreremo come iniziare a costruire oggi.
Cosa c’è di nuovo in Gemma 3n?
Gemma 3n rappresenta un importante progresso per l’intelligenza artificiale on-device, portando potenti capacità multimodali ai dispositivi edge con prestazioni precedentemente viste solo nei modelli di frontiera basati sul cloud dello scorso anno.
Per ottenere questo salto di qualità nelle prestazioni sul dispositivo è stato necessario ripensare il modello da zero. La base è l’esclusiva architettura mobile-first di Gemma 3n e tutto inizia con MatFormer.
MatFormer: un modello, tante dimensioni
Al centro di Gemma 3n c’è il Forme alimentari (🪆Trasformatore Matrioska) architetturaun nuovo trasformatore annidato costruito per l’inferenza elastica. Pensatela come le bambole Matrioska: un modello più grande contiene versioni più piccole e perfettamente funzionanti di se stesso. Questo approccio estende il concetto di Apprendimento della rappresentazione della matrioska dai semplici inglobamenti a tutti i componenti del trasformatore.
Durante l’addestramento MatFormer del modello con parametri effettivi 4B (E4B), un sottomodello con parametri effettivi 2B (E2B) viene contemporaneamente ottimizzato al suo interno, come mostrato nella figura sopra. Ciò offre agli sviluppatori due potenti funzionalità e casi d’uso attuali:
1: Modelli preestratti: Puoi scaricare e utilizzare direttamente il modello E4B principale per le massime funzionalità o il sottomodello E2B autonomo che abbiamo già estratto per te, offrendo un’inferenza fino a 2 volte più veloce.
2: Formati personalizzati con Mix-n-Match: Per un controllo più granulare su misura per vincoli hardware specifici, puoi creare uno spettro di modelli di dimensioni personalizzate tra E2B ed E4B utilizzando un metodo che chiamiamo Mix-n-Match. Questa tecnica consente di suddividere in modo preciso i parametri del modello E4B, principalmente regolando la dimensione nascosta della rete feed forward per livello (da 8192 a 16384) e saltando selettivamente alcuni livelli. Stiamo rilasciando il FoodEx Labuno strumento che mostra come recuperare questi modelli ottimali, che sono stati identificati valutando varie impostazioni su benchmark come MMLU.
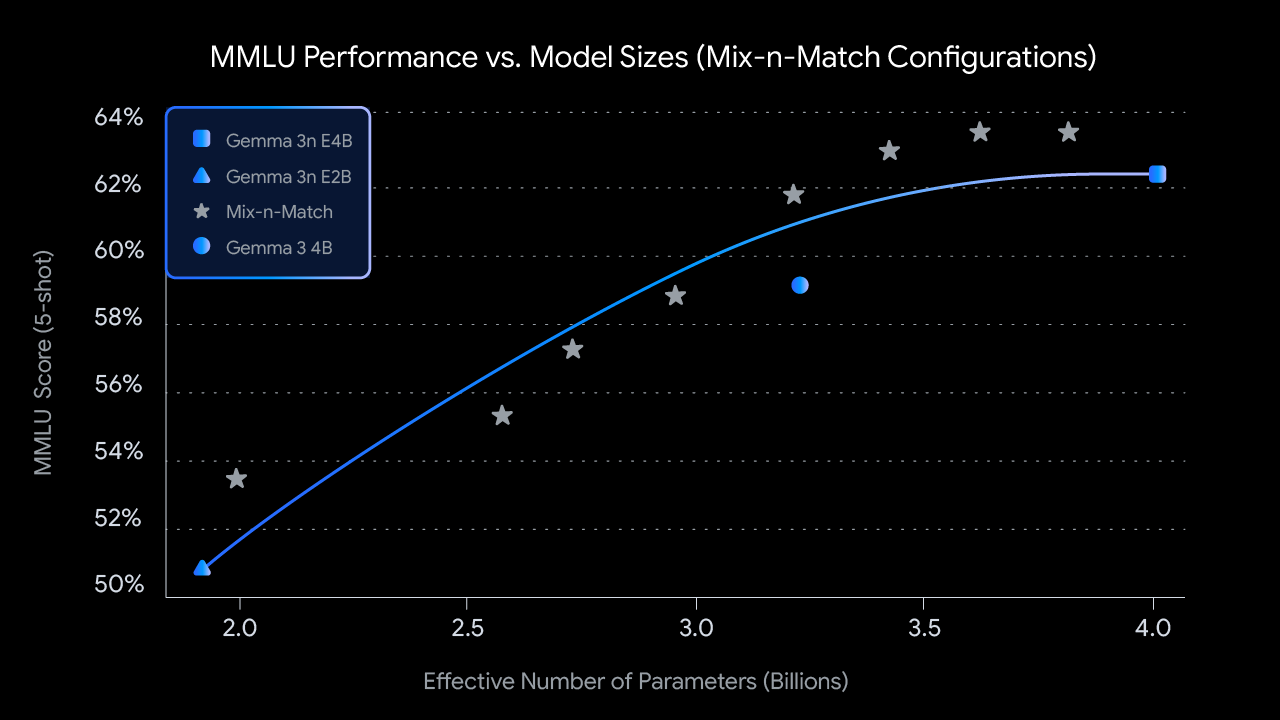
Punteggi MMLU per i checkpoint Gemma 3n preaddestrati a diverse dimensioni del modello (utilizzando Mix-n-Match)
Guardando al futuro, anche l’architettura MatFormer apre la strada a esecuzione elastica. Sebbene non faccia parte delle implementazioni lanciate oggi, questa funzionalità consente a un singolo modello E4B distribuito di passare dinamicamente tra percorsi di inferenza E4B ed E2B al volo, consentendo l’ottimizzazione in tempo reale delle prestazioni e dell’utilizzo della memoria in base all’attività corrente e al carico del dispositivo.
Per-Layer Embedding (PLE): sblocco di una maggiore efficienza della memoria
I modelli Gemma 3n incorporano Incorporamenti per livello (PLE). Questa innovazione è studiata su misura per l’implementazione sul dispositivo poiché migliora notevolmente la qualità del modello senza aumentare l’impronta di memoria ad alta velocità richiesta sull’acceleratore del dispositivo (GPU/TPU).
Mentre i modelli Gemma 3n E2B ed E4B hanno un conteggio totale dei parametri rispettivamente di 5B e 8B, PLE consente di caricare e calcolare in modo efficiente sulla CPU una parte significativa di questi parametri (gli incorporamenti associati a ciascun livello). Ciò significa che solo i pesi del nucleo del trasformatore (circa 2B per E2B e 4B per E4B) devono essere collocati nella memoria dell’acceleratore (VRAM), solitamente più limitata.

Con gli incorporamenti per livello, puoi utilizzare Gemma 3n E2B avendo solo parametri ~2B caricati nell’acceleratore.
Condivisione della cache KV: elaborazione più rapida di contesti lunghi
L’elaborazione di input lunghi, come le sequenze derivate da flussi audio e video, è essenziale per molte applicazioni multimodali avanzate sul dispositivo. Gemma 3n introduce KV Cache Sharing, una funzionalità progettata per accelerare in modo significativo il time-to-first-token per le applicazioni di risposta in streaming.
KV Cache Sharing ottimizza il modo in cui il modello gestisce la fase iniziale di elaborazione dell’input (spesso chiamata fase di “preriempimento”). Le chiavi e i valori dello strato intermedio provenienti dall’attenzione locale e globale sono direttamente condivisi con tutti gli strati superiori, offrendo un notevole miglioramento di 2 volte sulle prestazioni di precompilazione rispetto a Gemma 3 4B. Ciò significa che il modello può acquisire e comprendere lunghe sequenze di prompt molto più velocemente di prima.
Comprensione dell’audio: introduzione del parlato al testo e alla traduzione
Gemma 3n utilizza un codificatore audio avanzato basato su Modello vocale universale (USM). Il codificatore genera un token ogni 160 ms di audio (circa 6 token al secondo), che vengono poi integrati come input al modello linguistico, fornendo una rappresentazione granulare del contesto sonoro.
Questa funzionalità audio integrata sblocca funzionalità chiave per lo sviluppo sul dispositivo, tra cui:
- Riconoscimento vocale automatico (ASR): Abilita la trascrizione vocale in testo di alta qualità direttamente sul dispositivo.
- Traduzione vocale automatica (AST): Traduci la lingua parlata in testo in un’altra lingua.
Abbiamo osservato risultati AST particolarmente positivi per la traduzione tra inglese e spagnolo, francese, italiano e portoghese, che offrono un grande potenziale per gli sviluppatori che si rivolgono ad applicazioni in queste lingue. Per attività come la traduzione vocale, sfruttare i suggerimenti della catena di pensiero può migliorare significativamente i risultati. Ecco un esempio:
user
Transcribe the following speech segment in Spanish, then translate it into English:
model Testo semplice
Al momento del lancio, l’encoder Gemma 3n è implementato per elaborare clip audio fino a 30 secondi. Tuttavia, questa non è una limitazione fondamentale. Il codificatore audio sottostante è un codificatore di streaming, in grado di elaborare audio arbitrariamente lunghi con ulteriore addestramento audio di lunga durata. Le implementazioni successive sbloccheranno applicazioni di streaming lunghe e a bassa latenza.
MobileNet-V5: nuovo codificatore di visione all’avanguardia
Oltre alle funzionalità audio integrate, Gemma 3n è dotato di un nuovo codificatore di visione altamente efficiente, MobileNet-V5-300Moffrendo prestazioni all’avanguardia per attività multimodali su dispositivi edge.
Progettato per garantire flessibilità e potenza su hardware limitato, MobileNet-V5 offre agli sviluppatori:
- Molteplici risoluzioni di input: supporta nativamente risoluzioni di 256×256, 512×512 e 768×768 pixel, consentendoti di bilanciare prestazioni e dettagli per le tue applicazioni specifiche.
- Ampia comprensione visiva: Co-addestrato su estesi set di dati multimodali, eccelle in un’ampia gamma di attività di comprensione di immagini e video.
- Elevata produttività: elabora fino a 60 fotogrammi al secondo su un Google Pixel, consentendo analisi video in tempo reale sul dispositivo ed esperienze interattive.
Questo livello di prestazioni è raggiunto con molteplici innovazioni architetturali, tra cui:
- Una base avanzata di blocchi MobileNet-V4 (compresi i colli di bottiglia invertiti universali e MQA mobile).
- Un’architettura notevolmente ampliata, caratterizzata da un modello ibrido e piramidale profondo 10 volte più grande della più grande variante MobileNet-V4.
- Un nuovo adattatore VLM Fusion multiscala che migliora la qualità dei token per una migliore precisione ed efficienza.
Beneficiando di nuovi progetti architettonici e di tecniche di distillazione avanzate, MobileNet-V5-300M supera sostanzialmente il SoViT di base in Gemma 3 (addestrato con SigLip, senza distillazione). Su un Google Pixel Edge TPU, esso offre una velocità 13x con quantizzazione (6,5x senza), richiede il 46% di parametri in meno e ha un ingombro di memoria 4 volte più piccoloil tutto fornendo allo stesso tempo una precisione significativamente più elevata nei compiti di linguaggio visivo
Siamo entusiasti di condividere di più sul lavoro dietro questo modello. Tieni d’occhio il nostro prossimo rapporto tecnico MobileNet-V5, che approfondirà l’architettura del modello, le strategie di ridimensionamento dei dati e le tecniche di distillazione avanzate.
Rendere Gemma 3n accessibile fin dal primo giorno è stata una priorità. Siamo orgogliosi di collaborare con molti incredibili sviluppatori open source per garantire un ampio supporto attraverso strumenti e piattaforme popolari, compresi i contributi dei team dietro AMD, Axolotl, DockerVolto che abbraccia, llama.cpp, LMStudio, MLX, NVIDIAOllama, RedHat, SGLang, Unsloth e vLLM.
Ma questo ecosistema è solo l’inizio. Il vero potere di questa tecnologia sta in ciò che costruirai con essa. Ecco perché stiamo lanciando il Gemma 3n Impact Challenge. La tua missione: utilizzare le esclusive funzionalità su dispositivo, offline e multimodali di Gemma 3n per creare un prodotto per un mondo migliore. Con $ 150.000 in premi, stiamo cercando una storia video avvincente e una demo che faccia “wow” che mostri l’impatto nel mondo reale. Partecipa alla sfida e contribuire a costruire un futuro migliore.
Inizia oggi stesso con Gemma 3n
Pronti ad esplorare oggi le potenzialità di Gemma 3n? Ecco come:
- Sperimenta direttamente: Utilizzo Studio sull’intelligenza artificiale di Google per provare Gemma 3n in pochi click. I modelli Gemma possono anche essere distribuiti direttamente su Cloud Run da AI Studio.
- Impara e integra: Tuffati nel nostro documentazione completa per integrare rapidamente Gemma nei tuoi progetti o iniziare con le nostre guide di inferenza e messa a punto.
Fonte: deepmind.google

