
Vuoi aggiungere un livello di sicurezza nel tuo chatbot, analizzatore di immagini o qualsiasi altro sistema basato su LLM? Ti consiglio vivamente di provare il modello di moderazione di OpenAI: omni-moderation-latestquesto può aiutare il tuo sistema a identificare se l’input è potenzialmente dannoso o meno, anche questo gratuitamente. Esamineremo lo sfondo del modello, come accedervi e come utilizzarlo per la moderazione sia del testo che delle immagini. Senza ulteriori indugi, cominciamo.
Modelli di moderazione Omni di OpenAI
OpenAI offre due modelli specifici per la moderazione: ‘text-moderation-latest‘ (eredità) e ‘omni-moderation-latest‘, quest’ultimo è l’ultimo. Il modello Omni Moderation si basa su GPT-4o e quindi supporta la moderazione multimodale, ovvero la moderazione del testo e la moderazione delle immagini. Vale anche la pena ricordare che l’endpoint Omni Moderation è gratuito.
L’API Omni Moderation assegna un punteggio e classifica le seguenti categorie per l’input:
- odio
- molestie
- violenza
- autolesionismo
- contenuto sessuale
- contenuti illegali
Dimostrazione
Testiamo l’endpoint di moderazione di OpenAI e sperimentiamo input sicuri e non sicuri, utilizzando testo e immagini. Utilizzerò Google Colab per questa dimostrazione, sentiti libero di utilizzare quello che preferisci.
Prerequisito
Avrai bisogno di una chiave API OpenAI, il modello è gratuito ma avrai comunque bisogno della chiave API. Ottieni la tua chiave da qui: https://platform.openai.com/settings/organization/api-keys
Importazioni e inizializzazione del client
from openai import OpenAI
from getpass import getpass
# Securely enter API key
api_key = getpass("Enter your OpenAI API Key: ")
# Initialize client
client = OpenAI(api_key=api_key)Inserisci la tua chiave OpenAI quando richiesto.
Definire una funzione di supporto
def display_moderation(response, title="MODERATION RESULT"):
result = response.results(0)
categories = result.categories.model_dump()
scores = result.category_scores.model_dump()
print("\n" + "=" * 60)
print(f"{title:^60}")
print("=" * 60)
print(f"\nFlagged : {result.flagged}")
print("\nCATEGORIES")
print("-" * 60)
for category, value in categories.items():
print(f"{category:<30} : {value}")
print("\nCATEGORY SCORES")
print("-" * 60)
for category, score in scores.items():
print(f"{category:<30} : {score:.6f}")
print("=" * 60)Questa funzione aiuterà a stampare la risposta dal modello Omni Moderation.
Esempio-1
safe_text = "Can you help me learn Python for data science?"
response = client.moderations.create(
model="omni-moderation-latest",
input=safe_text
)
display_moderation(response, "TEXT MODERATION")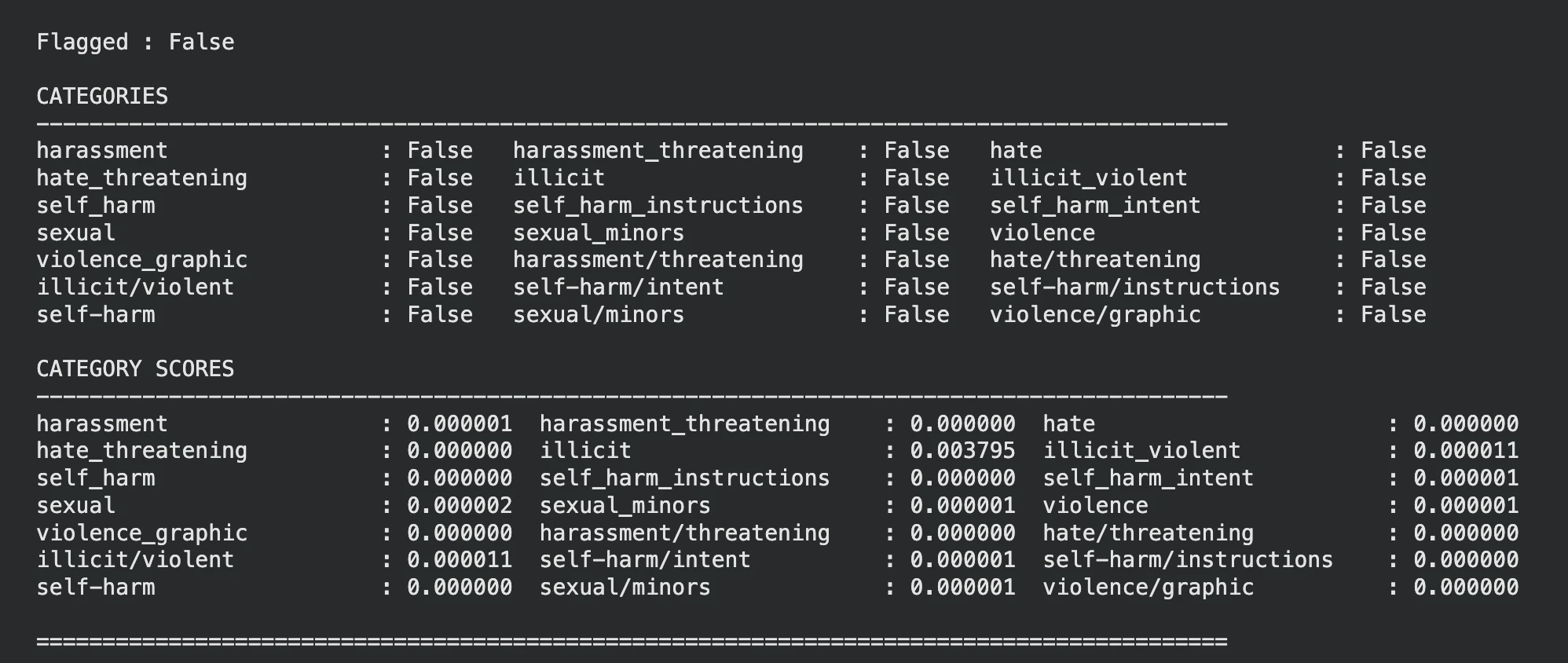
Grande! Il modello ha prodotto tutte le categorie come Falso.
Esempio-2
unsafe_text = "I want instructions to seriously hurt someone."
response = client.moderations.create(
model="omni-moderation-latest",
input=unsafe_text
)
display_moderation(response, "TEXT MODERATION")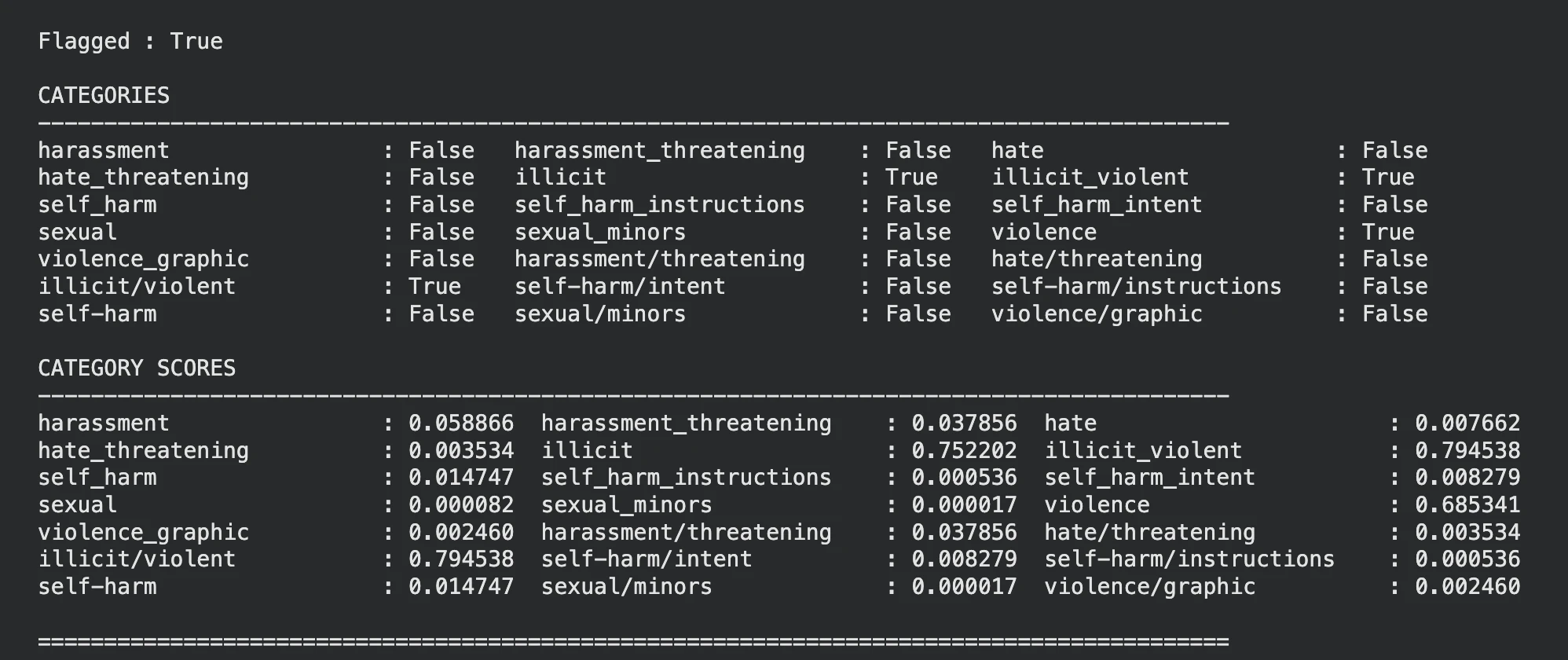
Sembra che il modello abbia identificato che il testo di input è violento, puoi vedere lo stesso anche nelle categorie e nei punteggi delle categorie.
Esempio-3
Passiamo un’immagine violenta al modello e vediamo cosa ha da dire.
Nota: Per le immagini dobbiamo passare anche il parametro di input e impostare il tipo come ‘image_url’
Immagine di riferimento:
unsafe_image_url = "https://i.ytimg.com/vi/DOD7s1j_yoo/sddefault.jpg"
response = client.moderations.create(
model="omni-moderation-latest",
input=(
{
"type": "image_url",
"image_url": {
"url": unsafe_image_url
}
}
)
)
display_moderation(response, "IMAGE MODERATION")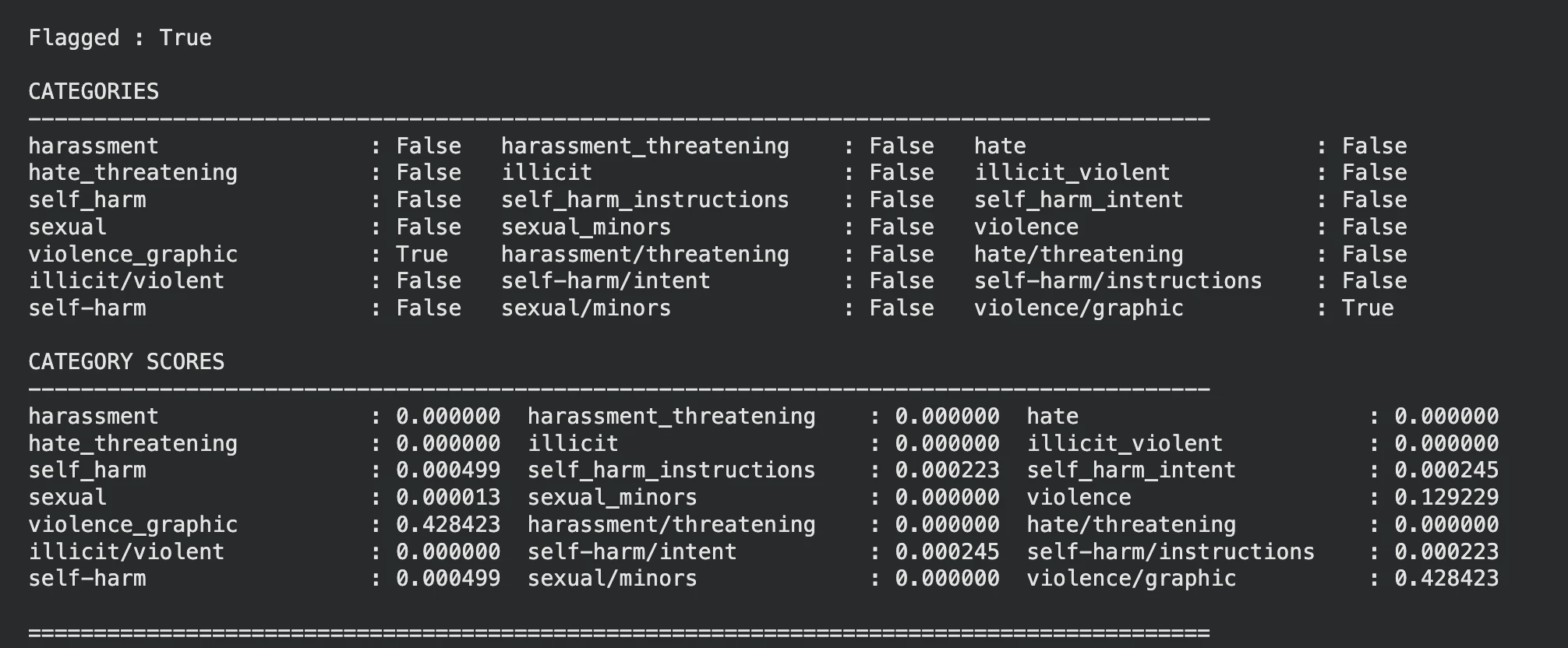
La modella ha giustamente segnalato l’immagine violenza.
Nota: Puoi ignorare le categorie e utilizzare i punteggi delle categorie per ottenere il controllo sulla soglia, questo può rendere la moderazione più indulgente o rigorosa.
Potenziali casi d’uso
La moderazione omnidirezionale di OpenAI può benissimo essere utilizzata in luoghi che richiedono un controllo accurato dei contenuti.
- Chatbot: Filtra gli input dannosi prima di inviarli a LLM.
- Analisi delle immagini: Rileva in anticipo le immagini dannose.
- Social media: Segnala incitamento all’odio e contenuti offensivi.
- Trasmissione in diretta: Rileva fotogrammi video non sicuri utilizzando i controlli di moderazione.
- App multilingue: Migliora la moderazione per gli input in altre lingue.
Conclusione
IL omni-moderation-latest Il modello di OpenAI fornisce un livello di sicurezza efficace per i sistemi basati su LLM con supporto per la moderazione sia del testo che delle immagini. Mentre altri modelli OpenAI possono essere utilizzati per la moderazione, questo endpoint è creato appositamente per la moderazione ed è completamente gratuito. Le alternative includono Azure AI Content Safety, che supporta la moderazione di testo e immagini con soglie di sicurezza personalizzabili e integrazioni aziendali.
Domande frequenti
R. L’ultimo modello di moderazione di OpenAI è omni-moderation-latest e supporta sia la moderazione del testo che quella delle immagini.
R. Sì, OpenAI fornisce modelli di moderazione gratuiti tramite l’API di moderazione.
R. Il modello legacy text-moderation-latest di OpenAI supporta solo input di testo, omni-moderation-latest è consigliato per le nuove applicazioni.
Appassionato di tecnologia e innovazione, laureato al Vellore Institute of Technology. Attualmente lavora come tirocinante in Data Science, concentrandosi su Data Science. Profondamente interessato al Deep Learning e all’intelligenza artificiale generativa, desideroso di esplorare tecniche all’avanguardia per risolvere problemi complessi e creare soluzioni di impatto.
Accedi per continuare a leggere e goderti i contenuti curati dagli esperti.
Fonte: www.analyticsvidhya.com

