
Molti recenti successi nei modelli linguistici (LM) sono stati ottenuti all’interno di un “paradigma statico”, in cui l’attenzione è posta sul miglioramento delle prestazioni sui parametri di riferimento creati senza considerare l’aspetto temporale dei dati. Ad esempio, rispondendo a domande su eventi di cui il modello potrebbe apprendere durante l’addestramento o valutando un testo sottocampionato dello stesso periodo dei dati di addestramento. Tuttavia, il nostro linguaggio e la nostra conoscenza sono dinamici e in continua evoluzione. Pertanto, per consentire una valutazione più realistica dei modelli di risposta alle domande per il prossimo salto di performance, è essenziale garantire che siano flessibili e robusti quando si incontrano dati nuovi e invisibili.
Nel 2021 abbiamo rilasciato Mind the Gap: valutazione della generalizzazione temporale nei modelli del linguaggio neurale e il benchmark di modellazione dinamica del linguaggio per WMT e arXiv per facilitare la valutazione del modello linguistico che tiene conto delle dinamiche temporali. In questo articolo, abbiamo evidenziato i problemi che gli attuali grandi LM all’avanguardia affrontano con la generalizzazione temporale e abbiamo scoperto che i token ad alta intensità di conoscenza subiscono un notevole calo delle prestazioni.
Oggi pubblichiamo due articoli e un nuovo benchmark che fanno avanzare ulteriormente la ricerca su questo argomento. In StreamingQA: un punto di riferimento per l’adattamento alle nuove conoscenze nel tempo nei modelli di risposta alle domandestudiamo il compito a valle di rispondere alle domande sul nostro benchmark appena proposto, Controllo qualità sullo streaming: vogliamo capire come i modelli parametrici e semi-parametrici di risposta alle domande aumentati dal recupero si adattano alle nuove informazioni, al fine di rispondere a domande su nuovi eventi. In Modelli linguistici potenziati da Internet attraverso la richiesta di poche inquadrature per la risposta a domande su dominio apertoesploriamo il potere di combinare un modello linguistico di grandi dimensioni con pochi scatti insieme alla Ricerca Google come componente di recupero. In tal modo, miriamo a migliorare la fattualità del modello, assicurandoci al tempo stesso che abbia accesso a informazioni aggiornate per rispondere a una serie diversificata di domande.
StreamingQA: un punto di riferimento per l’adattamento alle nuove conoscenze nel tempo nei modelli di risposta alle domande
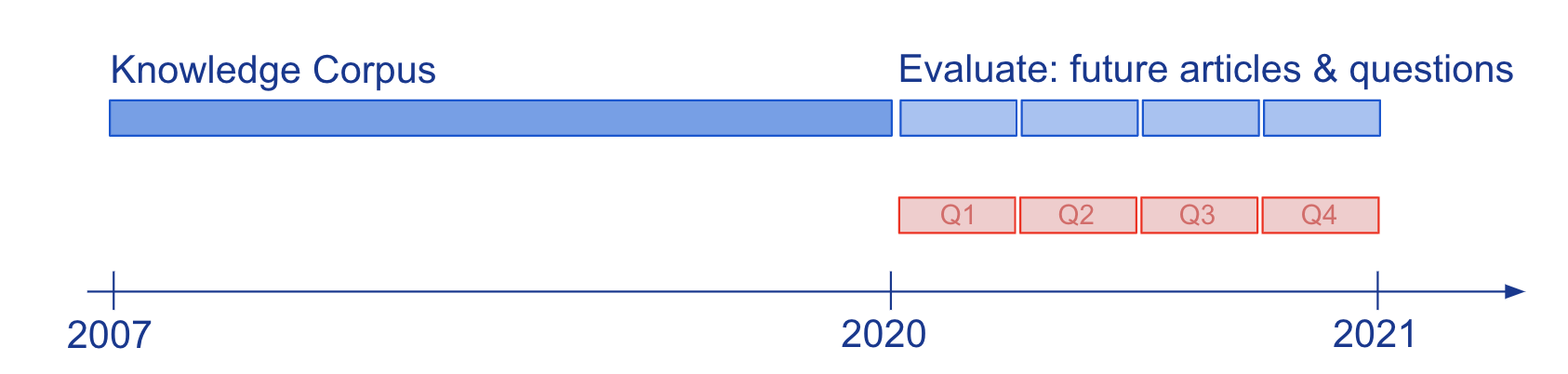
La conoscenza e la comprensione linguistica dei modelli valutati attraverso la risposta alle domande (QA) sono state comunemente studiate su istantanee statiche della conoscenza, come Wikipedia. Per studiare come i modelli di QA semi-parametrici e i loro LM parametrici sottostanti si adattano all’evoluzione della conoscenza, abbiamo costruito il nuovo benchmark su larga scala, StreamingQA, con domande scritte da esseri umani e generate automaticamente poste in una determinata data, a cui rispondere dopo 14 anni di esperienza. articoli di notizie con timestamp (vedere Figura 2). Mostriamo che i modelli parametrici possono essere aggiornati senza una riqualificazione completa, evitando al tempo stesso un catastrofico oblio. Per i modelli semiparametrici, l’aggiunta di nuovi articoli nello spazio di ricerca consente un rapido adattamento, tuttavia, i modelli con un LM sottostante obsoleto hanno prestazioni inferiori a quelli con un LM riqualificato.

Modelli linguistici potenziati da Internet attraverso la richiesta di poche inquadrature per la risposta a domande in dominio aperto
Il nostro obiettivo è sfruttare le capacità uniche di pochi scatti offerte dai modelli linguistici su larga scala per superare alcune delle loro sfide, rispetto al radicamento su informazioni fattuali e aggiornate. Motivati da LM semi-parametrici, che basano le loro decisioni su prove recuperate esternamente, utilizziamo suggerimenti di pochi colpi per imparare a condizionare i LM sulle informazioni restituite dal web utilizzando Ricerca Google, una fonte di conoscenza ampia e costantemente aggiornata. Il nostro approccio non prevede la messa a punto o l’apprendimento di parametri aggiuntivi, rendendolo quindi applicabile praticamente a qualsiasi modello linguistico. E in effetti, scopriamo che i LM condizionati sul web superano le prestazioni dei modelli a libro chiuso di dimensioni simili, o addirittura maggiori, nella risposta alle domande su dominio aperto.

