

L’esplorazione guidata dalla curiosità è il processo attivo di ricerca di nuove informazioni per migliorare la comprensione dell’agente del suo ambiente. Supponiamo che l’agente abbia appreso un modello del mondo in grado di prevedere eventi futuri data la storia degli eventi passati. L’agente guidato dalla curiosità può quindi utilizzare la mancata corrispondenza delle previsioni del modello mondiale come ricompensa intrinseca per indirizzare la sua politica di esplorazione verso la ricerca di nuove informazioni. Di seguito, l’agente può quindi utilizzare queste nuove informazioni per migliorare il modello mondiale stesso in modo da poter fare previsioni migliori. Questo processo iterativo può consentire all’agente di esplorare eventualmente ogni novità nel mondo e utilizzare queste informazioni per costruire un modello mondiale accurato.
Ispirato dai successi di bootstrap il tuo latente (BYOL) – che è stato applicato visione computerizzata, apprendimento della rappresentazione graficaE apprendimento della rappresentazione in RL – proponiamo BYOL-Explore: un agente AI concettualmente semplice ma generale, guidato dalla curiosità per risolvere compiti di esplorazione difficile. BYOL-Explore apprende una rappresentazione del mondo prevedendo la propria rappresentazione futura. Quindi, utilizza l’errore di previsione a livello di rappresentazione come ricompensa intrinseca per addestrare una politica guidata dalla curiosità. Pertanto, BYOL-Explore apprende una rappresentazione del mondo, le dinamiche del mondo e una politica di esplorazione guidata dalla curiosità nel loro insieme, semplicemente ottimizzando l’errore di previsione a livello di rappresentazione.
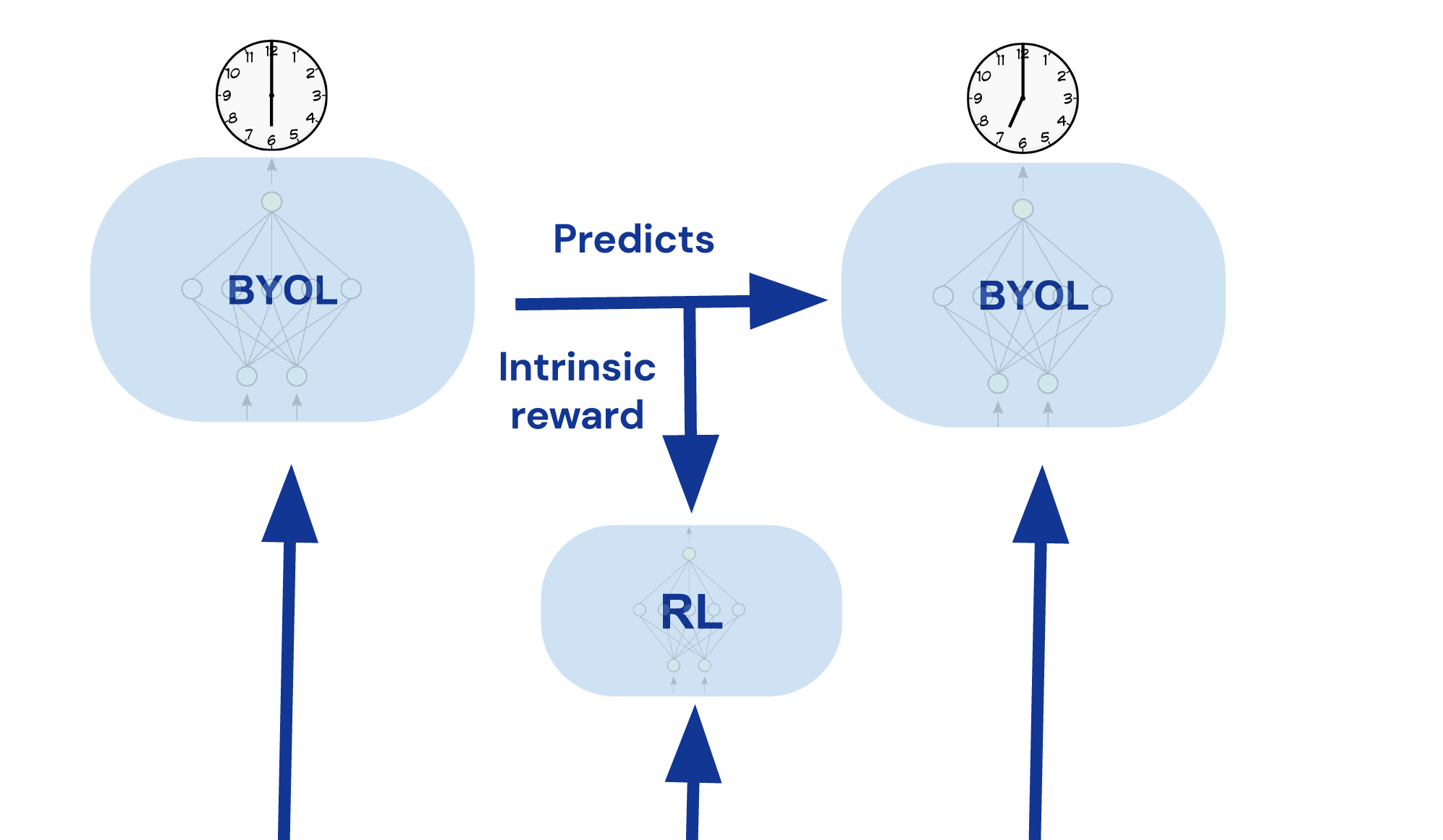

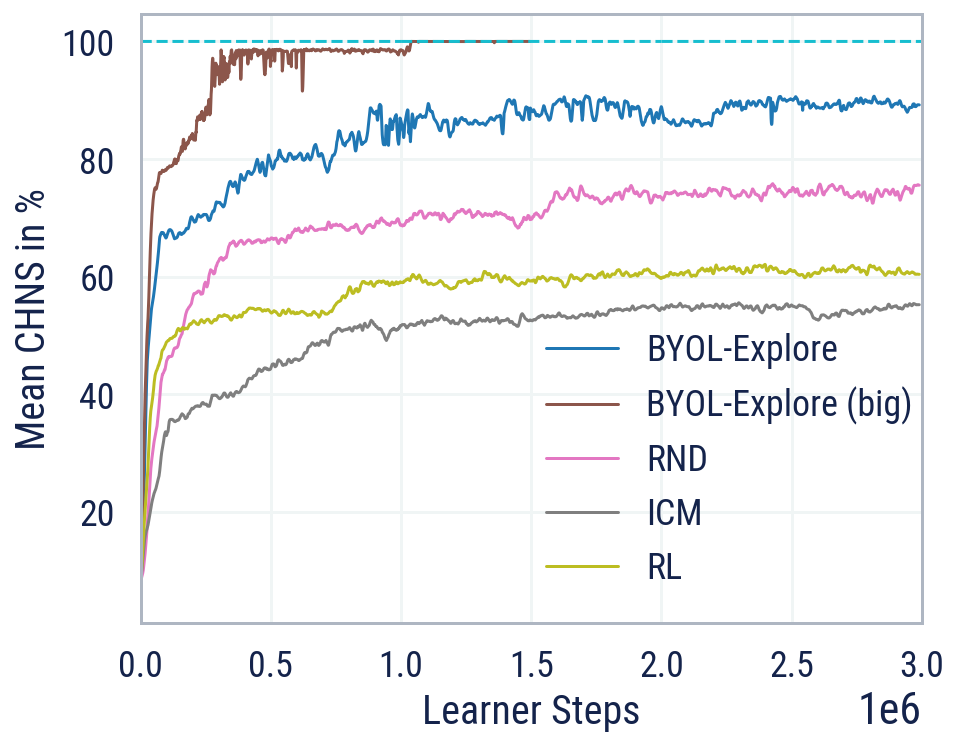
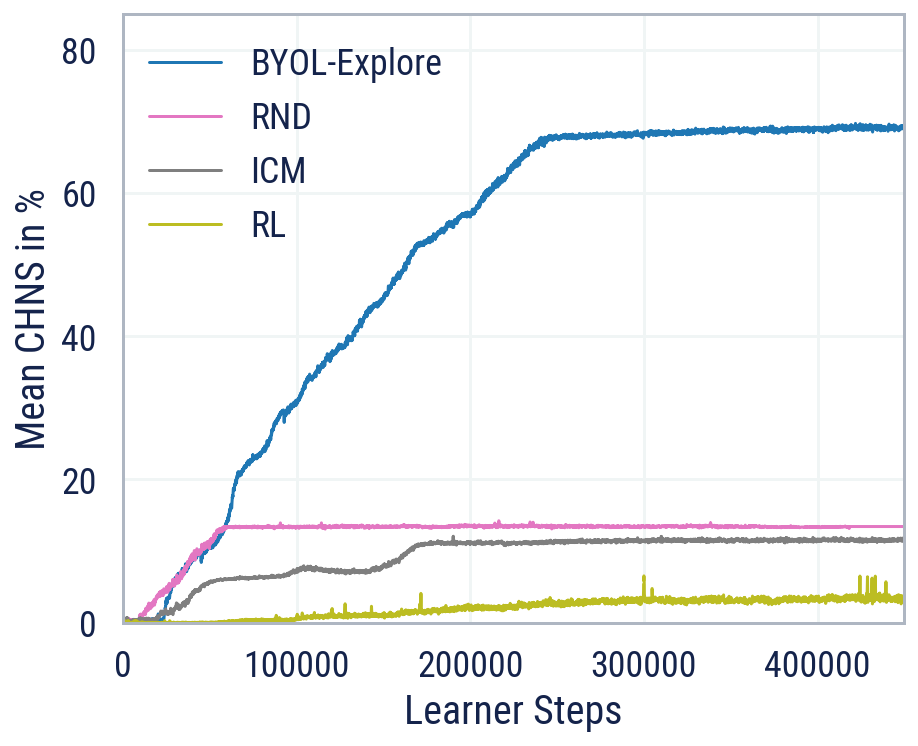
Nonostante la semplicità del suo design, quando applicato al DM-HARD-8 suite di impegnativi compiti di esplorazione 3D, visivamente complessi e difficili, BYOL-Explore supera i metodi di esplorazione standard guidati dalla curiosità come Distillazione in rete casuale (RND) e Modulo Curiosità Intrinseca (ICM), in termini di punteggio medio normalizzato umano (CHNS), misurato in tutte le attività. Sorprendentemente, BYOL-Explore ha ottenuto queste prestazioni utilizzando solo una singola rete addestrata contemporaneamente per tutte le attività, mentre il lavoro precedente era limitato all’impostazione di un’attività singola e poteva fare progressi significativi su queste attività solo se fornito con dimostrazioni da parte di esperti umani.
A ulteriore prova della sua generalità, BYOL-Explore raggiunge prestazioni sovrumane nelle dieci esplorazioni più difficili Giochi Ataripur avendo un design più semplice rispetto ad altri agenti concorrenti, come Agente57 E Vai-Esplora.
Andando avanti, possiamo generalizzare BYOL-Explore ad ambienti altamente stocastici apprendendo un modello mondiale probabilistico che potrebbe essere utilizzato per generare traiettorie di eventi futuri. Ciò potrebbe consentire all’agente di modellare la possibile stocasticità dell’ambiente, evitare trappole stocastiche e pianificare l’esplorazione.

