
Presentazione di un framework per creare agenti IA in grado di comprendere le istruzioni umane ed eseguire azioni in contesti aperti
Il comportamento umano è straordinariamente complesso. Anche una semplice richiesta come “Metti la palla vicino all’area di rigore” richiede ancora una profonda comprensione dell’intento situato e del linguaggio. Può essere difficile definire il significato di una parola come “vicino” – piazzare la palla dentro la casella potrebbe tecnicamente essere la più vicina, ma è probabile che chi parla voglia posizionare la palla accanto a la scatola. Affinché una persona possa agire correttamente in base alla richiesta, deve essere in grado di comprendere e giudicare la situazione e il contesto circostante.
La maggior parte dei ricercatori di intelligenza artificiale (AI) ora crede che scrivere codice informatico in grado di catturare le sfumature delle interazioni situate sia impossibile. In alternativa, i moderni ricercatori di machine learning (ML) si sono concentrati sull’apprendimento di questi tipi di interazioni dai dati. Per esplorare questi approcci basati sull’apprendimento e creare rapidamente agenti in grado di dare un senso alle istruzioni umane ed eseguire azioni in sicurezza in condizioni aperte, abbiamo creato un quadro di ricerca all’interno di un ambiente di videogioco.
Oggi lo siamo pubblicare un articolo E raccolta di videomostrando i nostri primi passi nella creazione di IA per videogiochi in grado di comprendere concetti umani confusi e, quindi, di iniziare a interagire con le persone alle loro condizioni.
Gran parte dei recenti progressi nell’addestramento dell’IA dei videogiochi si basa sull’ottimizzazione del punteggio di un gioco. Potenti agenti IA per Astronave E Dota sono stati addestrati utilizzando le vincite/perdite precise calcolate dal codice del computer. Invece di ottimizzare il punteggio di un gioco, chiediamo alle persone di inventare compiti e giudicare da soli i progressi.
Utilizzando questo approccio, abbiamo sviluppato un paradigma di ricerca che ci consente di migliorare il comportamento degli agenti attraverso un’interazione fondata e aperta con gli esseri umani. Sebbene sia ancora agli inizi, questo paradigma crea agenti in grado di ascoltare, parlare, porre domande, navigare, cercare e recuperare, manipolare oggetti ed eseguire molte altre attività in tempo reale.
Questa raccolta mostra i comportamenti degli agenti che seguono i compiti posti dai partecipanti umani:

Imparare nel “teatro”
La nostra struttura inizia con le persone che interagiscono con altre persone nel mondo dei videogiochi. Utilizzando l’apprendimento per imitazione, abbiamo dotato gli agenti di un insieme ampio ma non raffinato di comportamenti. Questo “comportamento a priori” è fondamentale per consentire interazioni che possono essere giudicate dagli esseri umani. Senza questa fase iniziale di imitazione, gli agenti sono del tutto casuali e praticamente impossibile interagire con loro. Un ulteriore giudizio umano sul comportamento dell’agente e l’ottimizzazione di questi giudizi mediante l’apprendimento per rinforzo (RL) producono agenti migliori, che possono poi essere nuovamente migliorati.
Per prima cosa abbiamo costruito un semplice mondo di videogioco basato sul concetto di “casetta dei giochi” per bambini. Questo ambiente ha fornito un ambiente sicuro in cui esseri umani e agenti potevano interagire e ha reso semplice la raccolta rapida di grandi volumi di dati di interazione. La casa presentava una varietà di stanze, mobili e oggetti configurati in nuove disposizioni per ogni interazione. Abbiamo anche creato un’interfaccia per l’interazione.
Sia l’umano che l’agente hanno un avatar nel gioco che consente loro di muoversi all’interno e manipolare l’ambiente. Possono anche chattare tra loro in tempo reale e collaborare ad attività, come trasportare oggetti e consegnarseli a vicenda, costruire una torre di blocchi o pulire una stanza insieme. I partecipanti umani stabiliscono i contesti per le interazioni navigando nel mondo, fissando obiettivi e ponendo domande agli agenti. In totale, il progetto ha raccolto più di 25 anni di interazioni in tempo reale tra agenti e centinaia di partecipanti (umani).
Osservare i comportamenti che emergono
Gli agenti che abbiamo addestrato sono capaci di svolgere una vasta gamma di compiti, alcuni dei quali non erano stati previsti dai ricercatori che li hanno realizzati. Ad esempio, abbiamo scoperto che questi agenti possono costruire file di oggetti utilizzando due colori alternati o recuperare da una casa un oggetto simile a un altro oggetto che l’utente ha in mano.
Queste sorprese emergono perché il linguaggio consente una serie quasi infinita di compiti e domande attraverso la composizione di significati semplici. Inoltre, come ricercatori, non specifichiamo i dettagli del comportamento degli agenti. Invece, le centinaia di esseri umani coinvolti nelle interazioni hanno formulato compiti e domande nel corso di queste interazioni.
Costruire il framework per la creazione di questi agenti
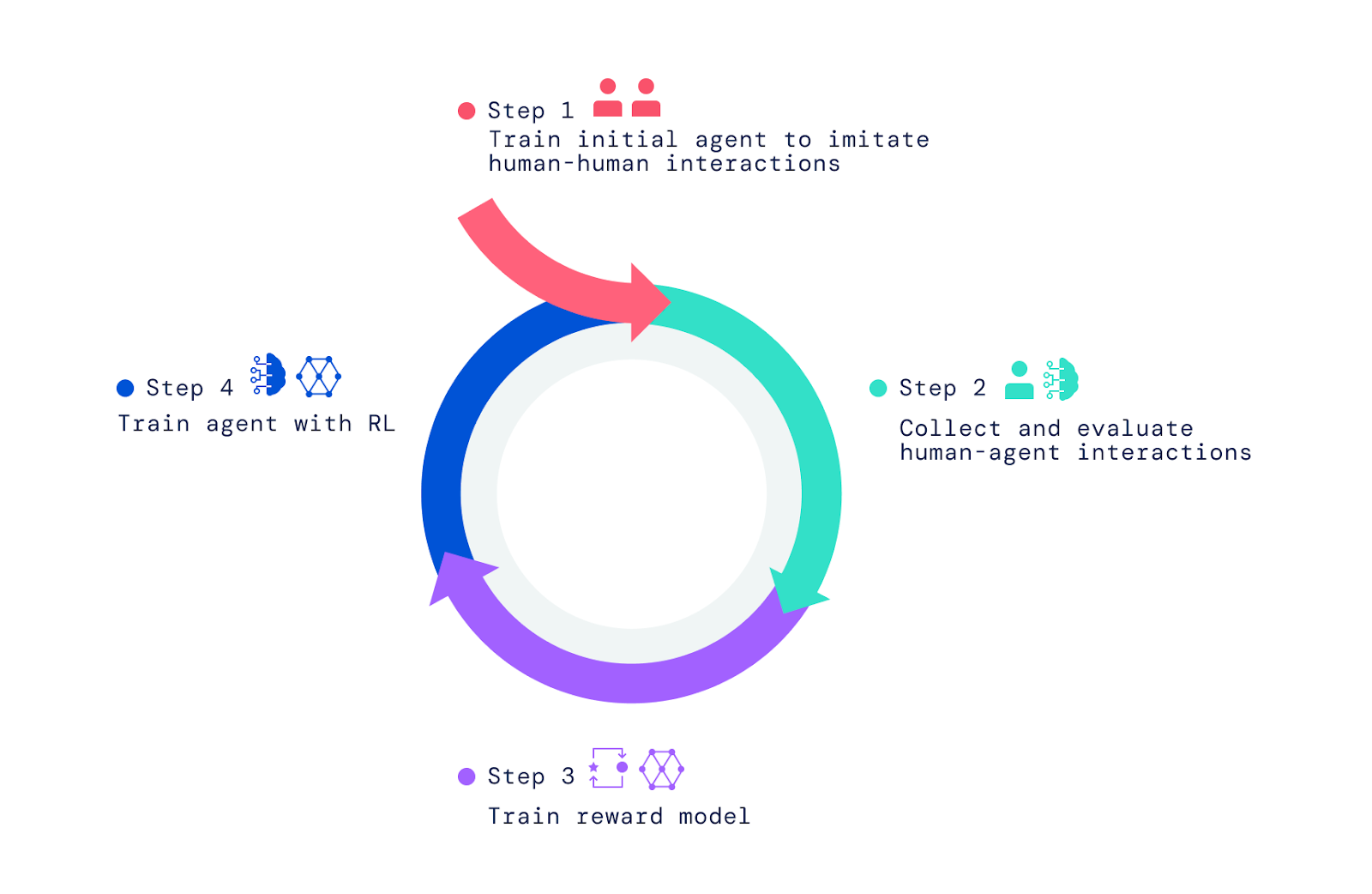
Per creare i nostri agenti AI, abbiamo applicato tre passaggi. Abbiamo iniziato addestrando gli agenti a imitare gli elementi base delle semplici interazioni umane in cui una persona chiede a un’altra di fare qualcosa o di rispondere a una domanda. Ci riferiamo a questa fase come alla creazione di un comportamento precedente che consente agli agenti di avere interazioni significative con un essere umano con alta frequenza. Senza questa fase imitativa, gli agenti si muovono in modo casuale e dicono sciocchezze. È quasi impossibile interagire con loro in modo ragionevole e dare loro un feedback è ancora più difficile. Questa fase è stata trattata in due dei nostri articoli precedenti, Imitare l’intelligenza interattivaE Creazione di agenti interattivi multimodali con imitazione e apprendimento autosupervisionatoche ha esplorato la costruzione di agenti basati sull’imitazione.
Andare oltre l’apprendimento per imitazione
Sebbene l’apprendimento per imitazione porti a interazioni interessanti, considera ogni momento dell’interazione altrettanto importante. Per apprendere un comportamento efficiente e diretto allo scopo, un agente deve perseguire un obiettivo e padroneggiare particolari movimenti e decisioni nei momenti chiave. Ad esempio, gli agenti basati sull’imitazione non prendono scorciatoie in modo affidabile o eseguono compiti con maggiore destrezza rispetto a un giocatore umano medio.
Qui mostriamo un agente basato sull’apprendimento per imitazione e un agente basato su RL che seguono la stessa istruzione umana:
Per dotare i nostri agenti di uno scopo, superando ciò che è possibile attraverso l’imitazione, ci siamo affidati a RL, che utilizza tentativi ed errori combinati con una misura delle prestazioni per il miglioramento iterativo. Man mano che i nostri agenti provavano azioni diverse, quelle che miglioravano le prestazioni venivano rinforzate, mentre quelle che le diminuivano venivano penalizzate.
In giochi come Atari, Dota, Go e StarCraft, il punteggio fornisce una misura delle prestazioni da migliorare. Invece di utilizzare un punteggio, abbiamo chiesto agli esseri umani di valutare le situazioni e fornire feedback, cosa che ha aiutato i nostri agenti Imparare un modello di ricompensa.
Formazione del modello di ricompensa e ottimizzazione degli agenti
Per addestrare un modello di ricompensa, abbiamo chiesto agli esseri umani di giudicare se osservavano eventi che indicavano progressi evidenti verso l’obiettivo corrente indicato o errori o sbagli evidenti. Abbiamo quindi tracciato una corrispondenza tra questi eventi positivi e negativi e le preferenze positive e negative. Poiché hanno luogo nel tempo, chiamiamo questi giudizi “intertemporali”. Abbiamo addestrato una rete neurale a prevedere queste preferenze umane e ottenuto come risultato un modello di ricompensa (o utilità/punteggio) che riflette il feedback umano.
Una volta addestrato il modello di ricompensa utilizzando le preferenze umane, lo abbiamo utilizzato per ottimizzare gli agenti. Abbiamo inserito i nostri agenti nel simulatore e li abbiamo invitati a rispondere alle domande e a seguire le istruzioni. Mentre agivano e parlavano nell’ambiente, il nostro modello di ricompensa addestrato ha valutato il loro comportamento e abbiamo utilizzato un algoritmo RL per ottimizzare le prestazioni degli agenti.
Allora da dove vengono le istruzioni e le domande sui compiti? Abbiamo esplorato due approcci per questo. Innanzitutto, abbiamo riciclato i compiti e le domande poste nel nostro set di dati umani. In secondo luogo, abbiamo addestrato gli agenti a imitare il modo in cui gli esseri umani impostano i compiti e pongono le domande, come mostrato in questo video, in cui due agenti, uno addestrato a imitare gli esseri umani che impostano compiti e pongono domande (blu) e uno addestrato a seguire le istruzioni e rispondere alle domande (giallo) , interagiscono tra loro:
Valutazione e iterazione per continuare a migliorare gli agenti
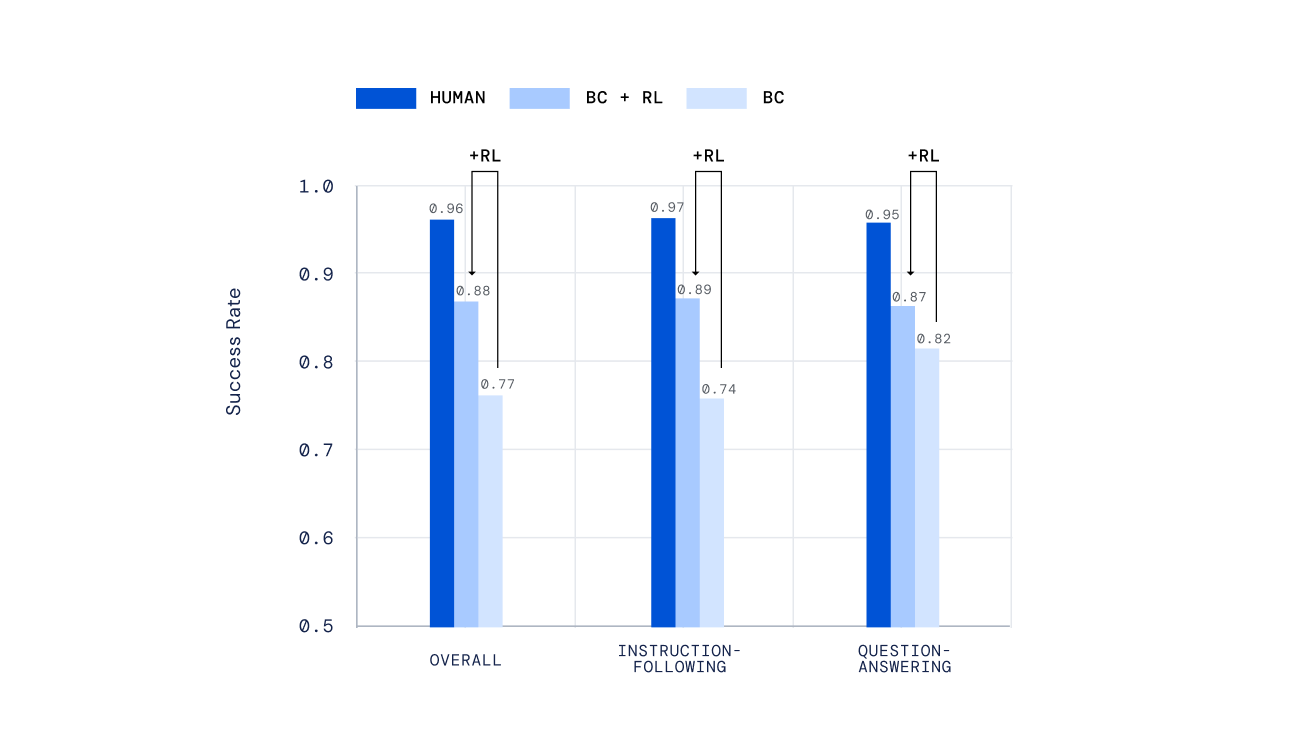
Abbiamo utilizzato una varietà di meccanismi indipendenti per valutare i nostri agenti, dai test scritti manualmente a un nuovo meccanismo per il punteggio umano offline di attività aperte create da persone, sviluppato nel nostro lavoro precedente Valutazione degli agenti interattivi multimodali. È importante sottolineare che abbiamo chiesto alle persone di interagire con i nostri agenti in tempo reale e di giudicare le loro prestazioni. I nostri agenti formati mediante RL hanno ottenuto risultati molto migliori rispetto a quelli formati mediante il solo apprendimento per imitazione.
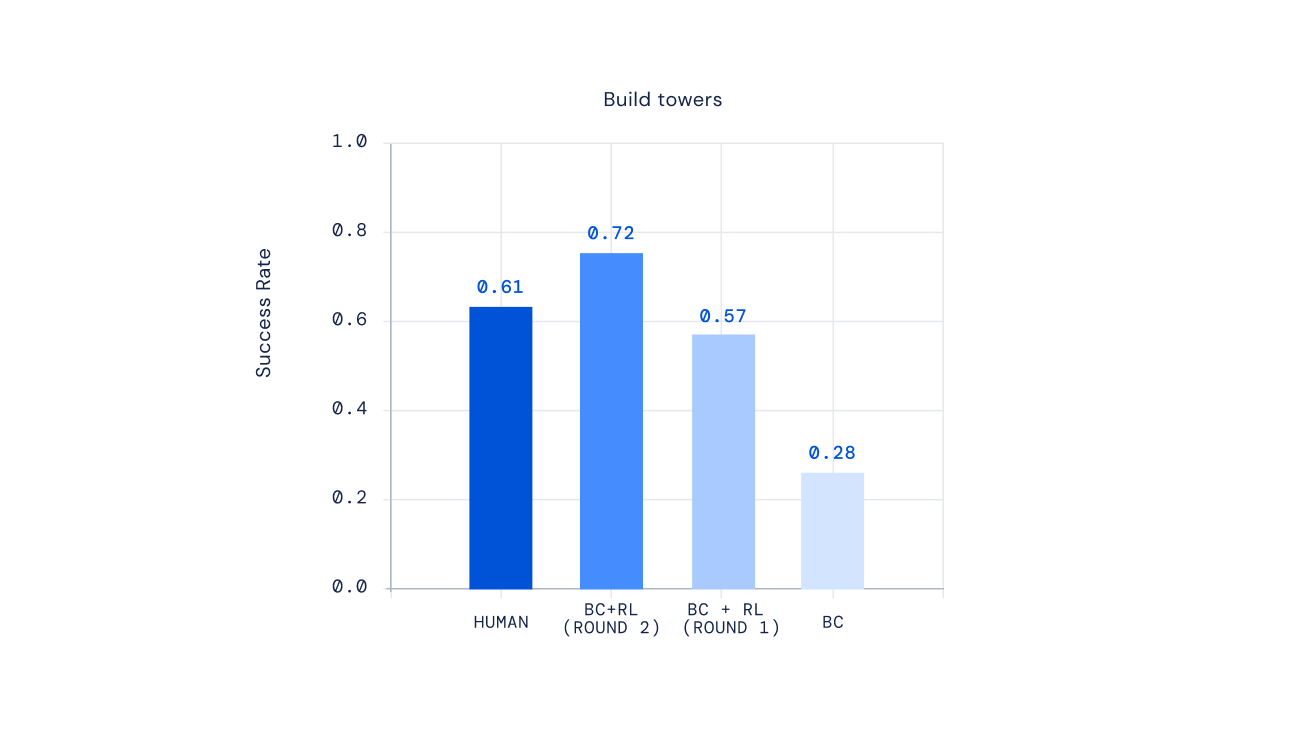
Infine, recenti esperimenti mostrano che possiamo iterare il processo RL per migliorare ripetutamente il comportamento dell’agente. Una volta che un agente è stato addestrato tramite RL, abbiamo chiesto alle persone di interagire con questo nuovo agente, annotarne il comportamento, aggiornare il nostro modello di ricompensa e quindi eseguire un’altra iterazione di RL. Il risultato di questo approccio furono agenti sempre più competenti. Per alcuni tipi di istruzioni complesse, potremmo persino creare agenti che in media abbiano prestazioni migliori dei giocatori umani.
Il futuro dell’addestramento dell’intelligenza artificiale alle preferenze umane situate
L’idea di addestrare l’intelligenza artificiale utilizzando le preferenze umane come ricompensa esiste da molto tempo. In Apprendimento profondo per rinforzo dalle preferenze umanei ricercatori sono stati pionieri di approcci recenti per allineare gli agenti basati sulla rete neurale con le preferenze umane. Un recente lavoro per sviluppare agenti di dialogo a turni ha esplorato idee simili per assistenti di formazione con RL dal feedback umano. La nostra ricerca ha adattato e ampliato queste idee per costruire IA flessibili in grado di gestire un’ampia gamma di interazioni multimodali, incarnate e in tempo reale con le persone.
Ci auguriamo che la nostra struttura possa un giorno portare alla creazione di IA di gioco in grado di rispondere ai nostri significati espressi naturalmente, piuttosto che fare affidamento su piani comportamentali scritti manualmente. Il nostro framework potrebbe anche essere utile per costruire assistenti digitali e robotici con cui le persone possano interagire ogni giorno. Non vediamo l’ora di esplorare la possibilità di applicare elementi di questo framework per creare un’IA sicura che sia veramente utile.
Vuoi saperne di più? Guardare il nostro ultimo articolo. Feedback e commenti sono benvenuti.

