
Perceiver e Perceiver IO funzionano come strumenti multiuso per l’intelligenza artificiale
La maggior parte delle architetture utilizzate oggi dai sistemi di intelligenza artificiale sono specialistiche. Una rete residua 2D può essere una buona scelta per l’elaborazione delle immagini, ma nella migliore delle ipotesi si adatta liberamente ad altri tipi di dati, come i segnali Lidar utilizzati nelle auto a guida autonoma o le coppie utilizzate nella robotica. Inoltre, le architetture standard sono spesso progettate con un solo compito in mente, spesso portando gli ingegneri a fare in quattro per rimodellare, distorcere o modificare in altro modo i propri input e output nella speranza che un’architettura standard possa imparare a gestire correttamente il problema. Gestire più di un tipo di dati, come i suoni e le immagini che compongono i video, è ancora più complicato e di solito coinvolge sistemi complessi e sintonizzati manualmente, costituiti da molte parti diverse, anche per compiti semplici. Nell’ambito della missione di DeepMind di risolvere l’intelligenza per far avanzare la scienza e l’umanità, vogliamo costruire sistemi in grado di risolvere problemi che utilizzano molti tipi di input e output, quindi abbiamo iniziato a esplorare un’architettura più generale e versatile in grado di gestire tutti i tipi di dati .

In un documento presentato a ICML 2021 (la Conferenza Internazionale sull’Apprendimento Automatico) e pubblicato come prestampa su arXivabbiamo introdotto Perceiver, un’architettura generica in grado di elaborare dati tra cui immagini, nuvole di punti, audio, video e le loro combinazioni. Sebbene il Perceiver potesse gestire molte varietà di dati di input, era limitato a compiti con output semplici, come la classificazione. UN nuova prestampa su arXiv descrive Perceiver IO, una versione più generale dell’architettura Perceiver. Perceiver IO può produrre un’ampia varietà di output da molti input diversi, rendendolo applicabile a domini del mondo reale come linguaggio, visione e comprensione multimodale, nonché a giochi impegnativi come StarCraft II. Per aiutare i ricercatori e la comunità dell’apprendimento automatico in generale, abbiamo ora open source il codice.

I percettori si basano su Trasformatoreun’architettura che utilizza un’operazione chiamata “attenzione” per mappare gli input in output. Confrontando tutti gli elementi dell’input, i Transformers elaborano gli input in base alle loro relazioni tra loro e all’attività. L’attenzione è semplice e ampiamente applicabile, ma i Transformers utilizzano l’attenzione in un modo che può diventare rapidamente costoso man mano che cresce il numero di input. Ciò significa che i Transformer funzionano bene per input con al massimo poche migliaia di elementi, ma forme comuni di dati come immagini, video e libri possono facilmente contenere milioni di elementi. Con il Perceiver originale, abbiamo risolto un grosso problema per un’architettura generalista: adattare l’operazione di attenzione del Transformer a input molto ampi senza introdurre ipotesi specifiche del dominio. Il Percettore lo fa utilizzando l’attenzione per codificare prima gli input in un piccolo array latente. Questo array latente può quindi essere ulteriormente elaborato a un costo indipendente dalla dimensione dell’input, consentendo alla memoria del Percettore e alle esigenze computazionali di crescere con grazia man mano che l’input diventa più grande, anche per modelli particolarmente profondi.

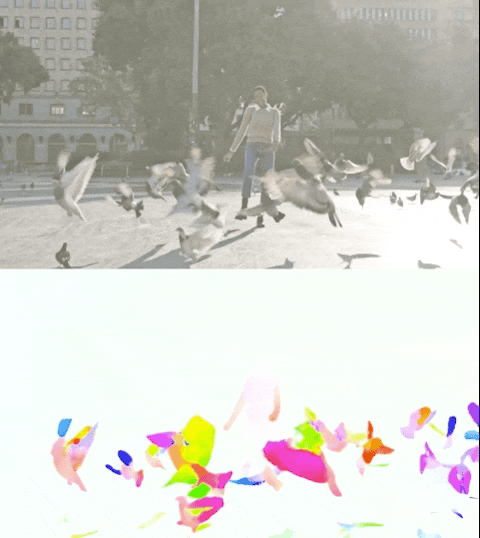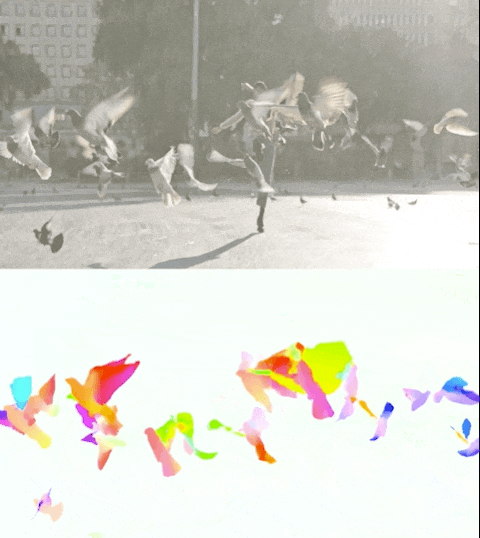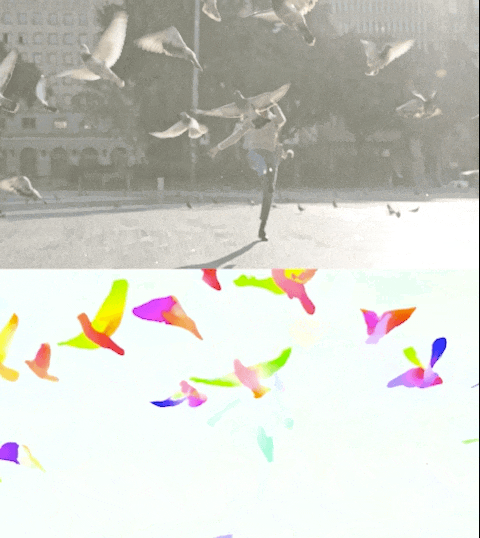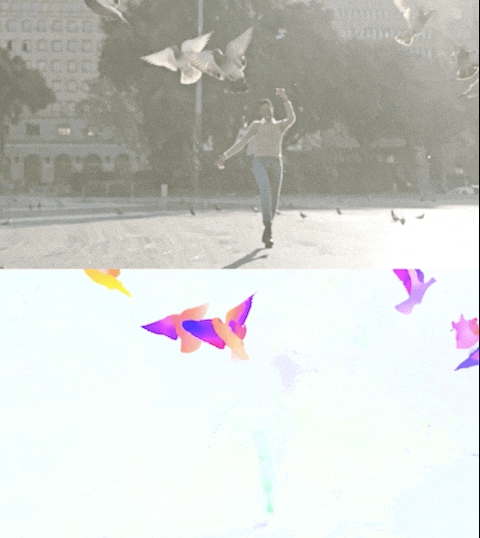


Figura 3. Perceiver IO produce risultati all’avanguardia nell’impegnativo compito di stima del flusso ottico o di tracciamento del movimento di tutti i pixel in un’immagine. Il colore di ciascun pixel mostra la direzione e la velocità del movimento stimate da Perceiver IO, come indicato nella legenda sopra.
Questa “crescita aggraziata” consente al Percettore di raggiungere un livello di generalità senza precedenti: è competitivo con modelli specifici del dominio su benchmark basati su immagini, nuvole di punti 3D, audio e immagini insieme. Ma poiché il Perceiver originale produceva un solo output per input, non era così versatile come avevano bisogno i ricercatori. Perceiver IO risolve questo problema prestando attenzione non solo alla codifica su un array latente ma anche alla decodifica da esso, il che conferisce alla rete una grande flessibilità. Perceiver IO ora si adatta a input ampi e diversificati E output e può anche gestire più attività o tipi di dati contemporaneamente. Ciò apre le porte a tutti i tipi di applicazioni, come comprendere il significato di un testo da ciascuno dei suoi caratteri, seguire il movimento di tutti i punti in un’immagine, elaborare il suono, le immagini e le etichette che compongono un video e persino riprodurre giochi, il tutto utilizzando un’unica architettura più semplice delle alternative.
Nei nostri esperimenti, abbiamo visto Perceiver IO funzionare in un’ampia gamma di domini di riferimento, come linguaggio, visione, dati multimodali e giochi, per fornire un modo standard per gestire molti tipi di dati. Speriamo la nostra ultima prestampa e il codice disponibile su Github aiutare ricercatori e professionisti ad affrontare i problemi senza dover investire tempo e sforzi per creare soluzioni personalizzate utilizzando sistemi specializzati. Mentre continuiamo a imparare dall’esplorazione di nuovi tipi di dati, non vediamo l’ora di migliorare ulteriormente questa architettura di uso generale e di rendere più rapida e semplice la risoluzione dei problemi nel campo della scienza e dell’apprendimento automatico.

