
DeepNash impara a giocare a Stratego da zero combinando la teoria dei giochi e il RL profondo senza modelli
I sistemi di intelligenza artificiale (AI) per il gioco sono avanzati verso una nuova frontiera. Stratego, il classico gioco da tavolo più complesso degli scacchi e del Go e più astuto del poker, è ora padroneggiato. Pubblicato in Scienzanoi presentiamo DeepNashun agente IA che ha imparato il gioco da zero fino a raggiungere il livello di un esperto umano giocando contro se stesso.
DeepNash utilizza un approccio innovativo, basato sulla teoria dei giochi e sull’apprendimento per rinforzo profondo senza modelli. Il suo stile di gioco converge verso un equilibrio di Nash, il che significa che il suo gioco è molto difficile da sfruttare per un avversario. Così difficile, infatti, che DeepNash ha raggiunto una delle prime tre posizioni di tutti i tempi tra gli esperti umani sulla più grande piattaforma online Stratego del mondo, Gravon.
I giochi da tavolo sono stati storicamente una misura del progresso nel campo dell’intelligenza artificiale, consentendoci di studiare come gli esseri umani e le macchine sviluppano ed eseguono strategie in un ambiente controllato. A differenza degli scacchi e del Go, Stratego è un gioco di informazioni imperfette: i giocatori non possono osservare direttamente l’identità dei pezzi dell’avversario.
Questa complessità ha fatto sì che altri sistemi Stratego basati sull’intelligenza artificiale abbiano faticato ad andare oltre il livello amatoriale. Ciò significa anche che una tecnica di intelligenza artificiale di grande successo chiamata “ricerca nell’albero del gioco”, precedentemente utilizzata per padroneggiare molti giochi a informazione perfetta, non è sufficientemente scalabile per Stratego. Per questo motivo, DeepNash va ben oltre la semplice ricerca nell’albero dei giochi.
Il valore di padroneggiare Stratego va oltre il gioco. Nel perseguire la nostra missione di risolvere l’intelligenza per far avanzare la scienza e avvantaggiare l’umanità, dobbiamo costruire sistemi di intelligenza artificiale avanzati in grado di operare in situazioni complesse del mondo reale con informazioni limitate su altri agenti e persone. Il nostro articolo mostra come DeepNash può essere applicato in situazioni di incertezza e bilanciare con successo i risultati per aiutare a risolvere problemi complessi.
Conoscere Stratego
Stratego è un gioco a turni cattura-bandiera. È un gioco di bluff e tattica, di raccolta di informazioni e manovre sottili. Ed è un gioco a somma zero, quindi qualsiasi guadagno di un giocatore rappresenta una perdita della stessa entità per il suo avversario.
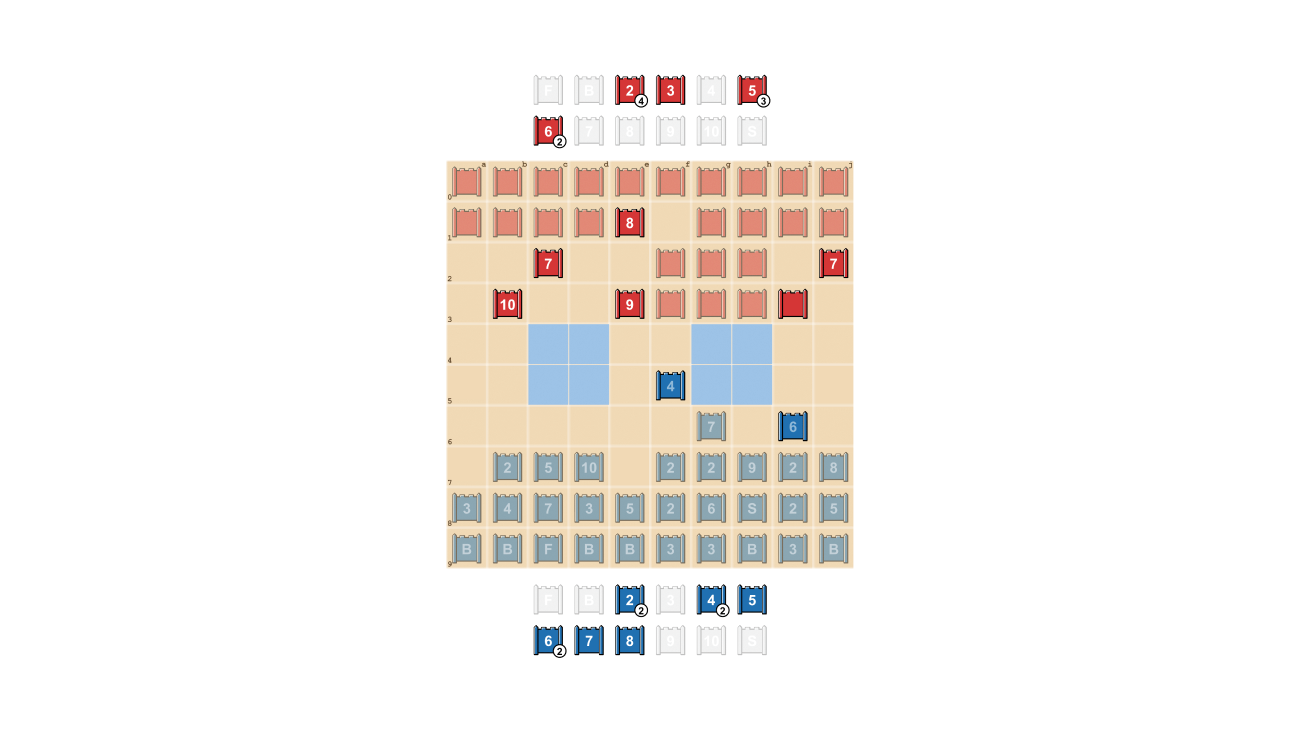
Stratego è impegnativo per l’intelligenza artificiale, in parte, perché è un gioco con informazioni imperfette. Entrambi i giocatori iniziano disponendo i loro 40 pezzi di gioco nella formazione iniziale che preferiscono, inizialmente nascosti l’uno all’altro all’inizio del gioco. Poiché entrambi i giocatori non hanno accesso alle stesse conoscenze, devono bilanciare tutti i possibili risultati quando prendono una decisione, fornendo un punto di riferimento impegnativo per studiare le interazioni strategiche. I tipi di pezzi e le loro classifiche sono mostrati di seguito.

Mezzo: Una possibile formazione titolare. Nota come la bandiera è nascosta al sicuro sul retro, fiancheggiata da bombe protettive. Le due aree azzurre sono “laghi” e non sono mai entrate.
Giusto: Un gioco in gioco, che mostra la Spia di Blu che cattura i 10 di Rosso.
L’informazione è una conquista difficile in Stratego. L’identità del pezzo di un avversario viene generalmente rivelata solo quando incontra l’altro giocatore sul campo di battaglia. Ciò è in netto contrasto con i giochi a informazione perfetta come gli scacchi o il Go, in cui la posizione e l’identità di ogni pezzo sono note a entrambi i giocatori.
Gli approcci di apprendimento automatico che funzionano così bene su giochi informativi perfetti, come quello di DeepMind AlphaZeronon sono facilmente trasferibili a Stratego. La necessità di prendere decisioni con informazioni imperfette e la possibilità di bluffare rendono Stratego più simile al poker Texas Hold’em e richiede una capacità simile a quella umana, come notato dallo scrittore americano Jack London: “La vita non è sempre una questione di tenere in mano buone carte, ma a volte giocare bene una mano povera.
Le tecniche di intelligenza artificiale che funzionano così bene in giochi come il Texas Hold’em, tuttavia, non vengono trasferite a Stratego, a causa della durata del gioco, spesso centinaia di mosse prima che un giocatore vinca. Il ragionamento in Stratego deve essere svolto su un gran numero di azioni sequenziali senza alcuna visione ovvia di come ciascuna azione contribuisca al risultato finale.
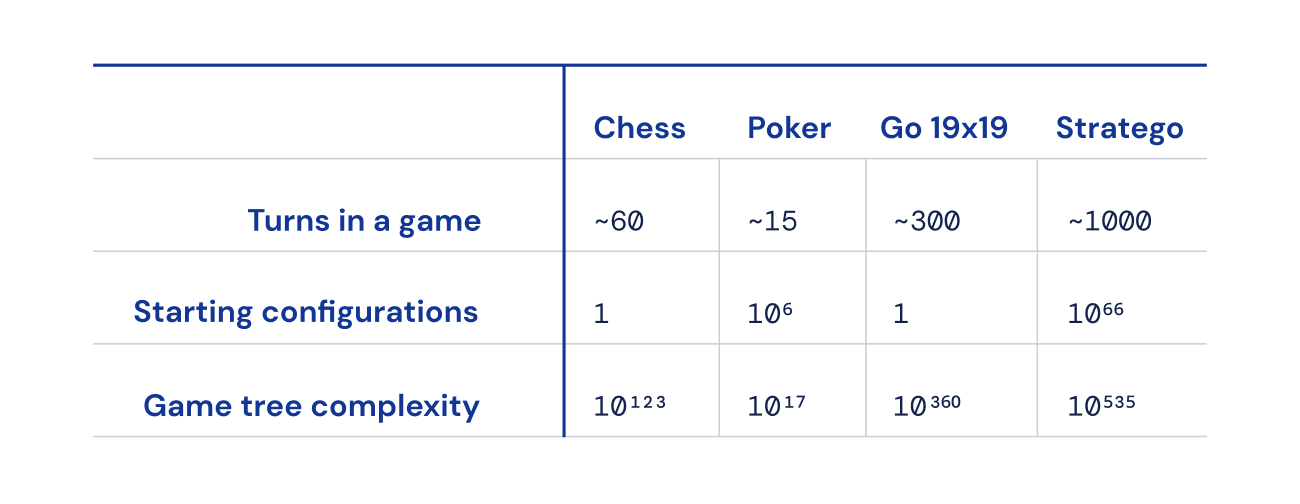
Infine, il numero di possibili stati del gioco (espressi come “complessità dell’albero di gioco”) è fuori scala rispetto a scacchi, Go e poker, rendendolo incredibilmente difficile da risolvere. Questo è ciò che ci ha entusiasmato di Stratego e il motivo per cui ha rappresentato una sfida decennale per la comunità dell’intelligenza artificiale.
Alla ricerca di un equilibrio
DeepNash utilizza un nuovo approccio basato su una combinazione di teoria dei giochi e apprendimento per rinforzo profondo senza modelli. “Senza modello” significa che DeepNash non sta tentando di modellare esplicitamente lo stato di gioco privato del suo avversario durante il gioco. Soprattutto nelle prime fasi del gioco, quando DeepNash conosce poco i pezzi del suo avversario, tale modellazione sarebbe inefficace, se non impossibile.
E poiché la complessità dell’albero di gioco di Stratego è così vasta, DeepNash non può impiegare un approccio fedele ai giochi basati sull’intelligenza artificiale: la ricerca degli alberi Monte Carlo. La ricerca degli alberi è stata un ingrediente chiave di molti traguardi raggiunti nell’intelligenza artificiale per giochi da tavolo meno complessi e poker.
Invece, DeepNash è alimentato da una nuova idea algoritmica di teoria dei giochi che chiamiamo Regularized Nash Dynamics (R-NaD). Lavorando su una scala senza precedenti, R-NaD guida il comportamento di apprendimento di DeepNash verso quello che è noto come equilibrio di Nash (tuffati nei dettagli tecnici in il nostro giornale).
Il comportamento di gioco che si traduce in un equilibrio di Nash non è sfruttabile nel tempo. Se una persona o una macchina giocasse a uno Stratego perfettamente inesplorabile, la peggiore percentuale di vincita che potrebbe ottenere sarebbe del 50%, e solo se affrontasse un avversario altrettanto perfetto.
Nelle partite contro i migliori robot Stratego, inclusi diversi vincitori del Computer Stratego World Championship, la percentuale di vittorie di DeepNash ha superato il 97% e spesso è stata del 100%. Contro i migliori giocatori umani esperti sulla piattaforma di giochi Gravon, DeepNash ha ottenuto un tasso di vincita dell’84%, guadagnandosi una delle prime tre posizioni di tutti i tempi.
Aspettare l’inaspettato
Per ottenere questi risultati, DeepNash ha dimostrato alcuni comportamenti notevoli sia durante la fase iniziale di schieramento dei pezzi che durante la fase di gioco. Per diventare difficile da sfruttare, DeepNash ha sviluppato una strategia imprevedibile. Ciò significa creare schieramenti iniziali sufficientemente vari da impedire al suo avversario di individuare schemi nel corso di una serie di giochi. E durante la fase di gioco, DeepNash randomizza tra azioni apparentemente equivalenti per prevenire tendenze sfruttabili.
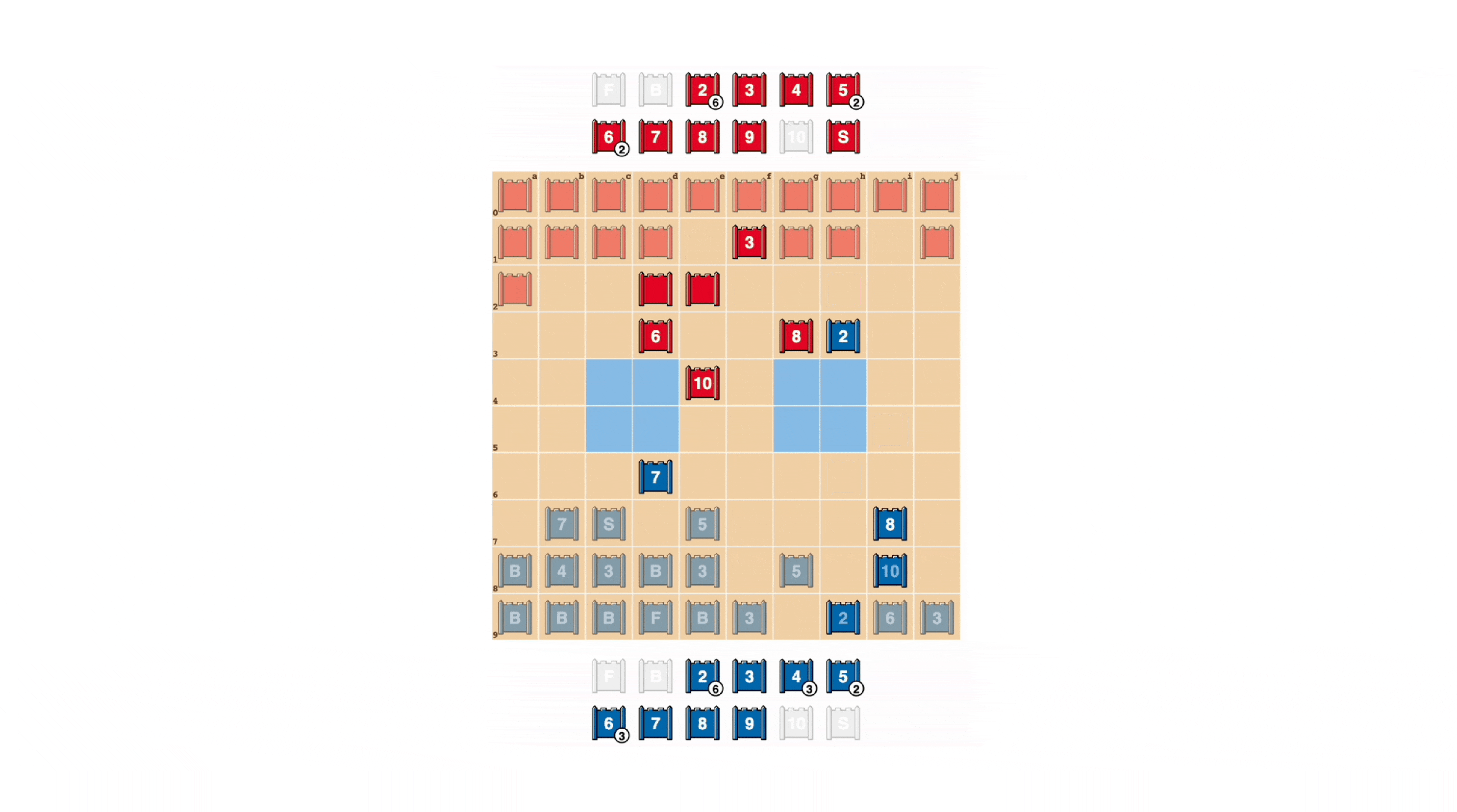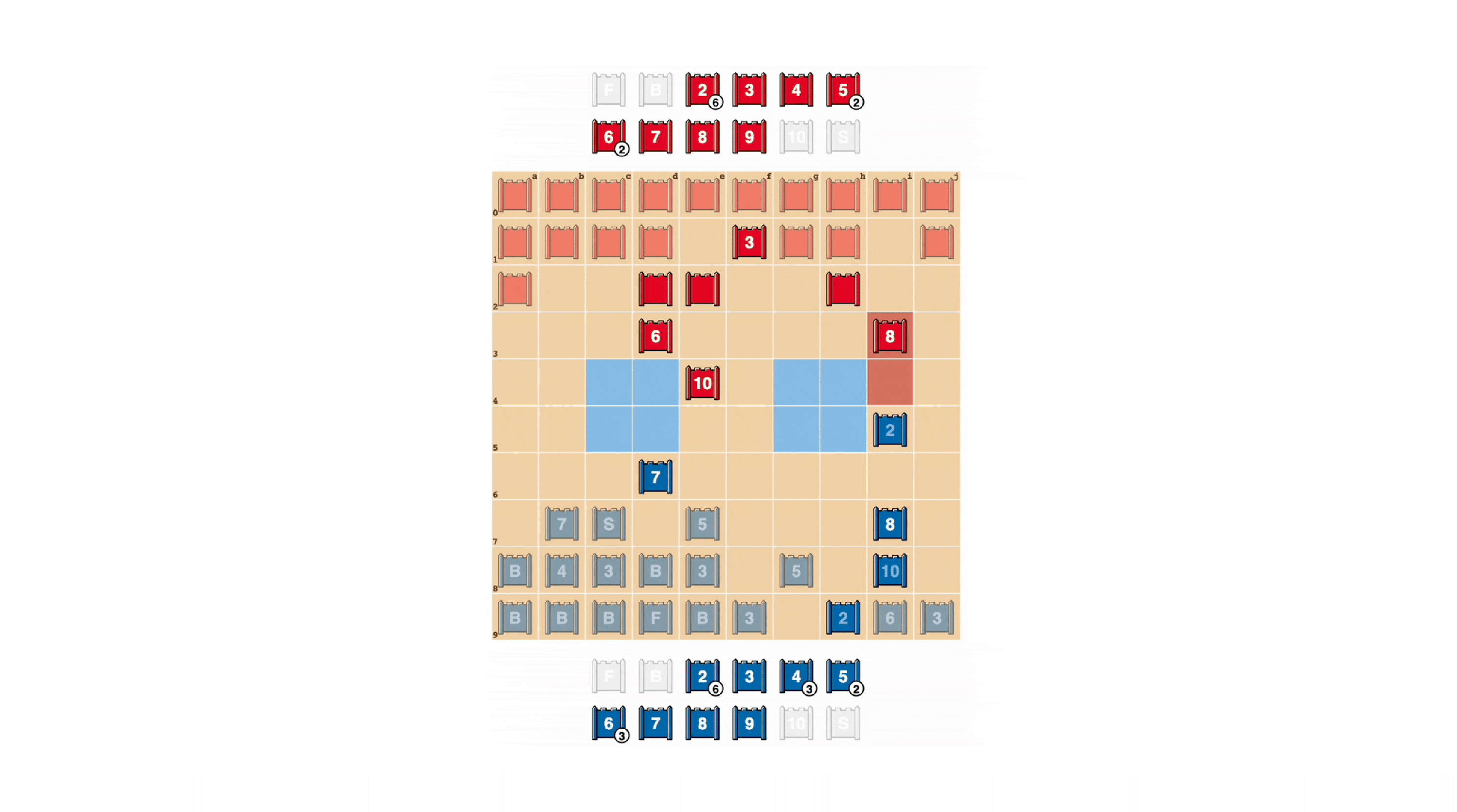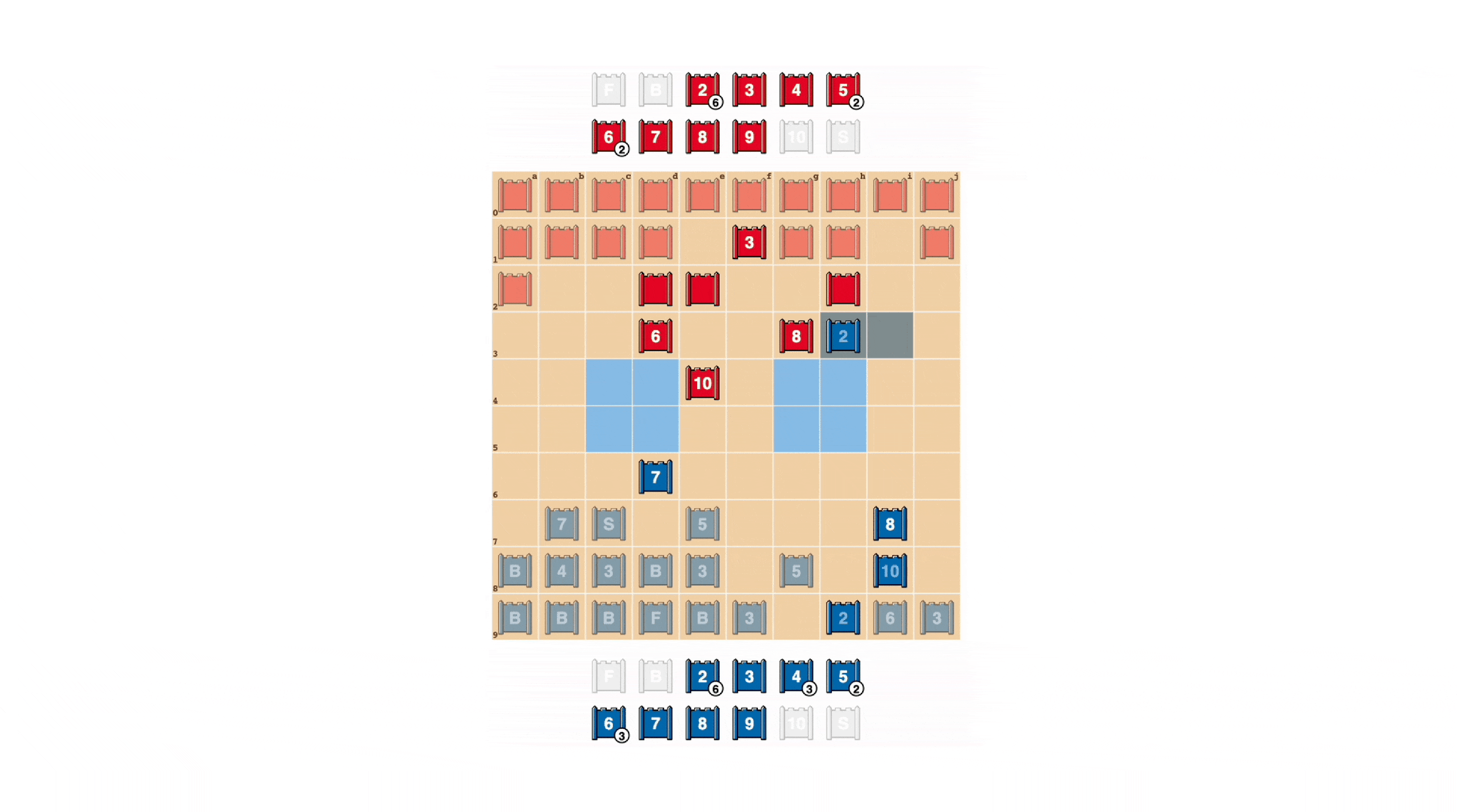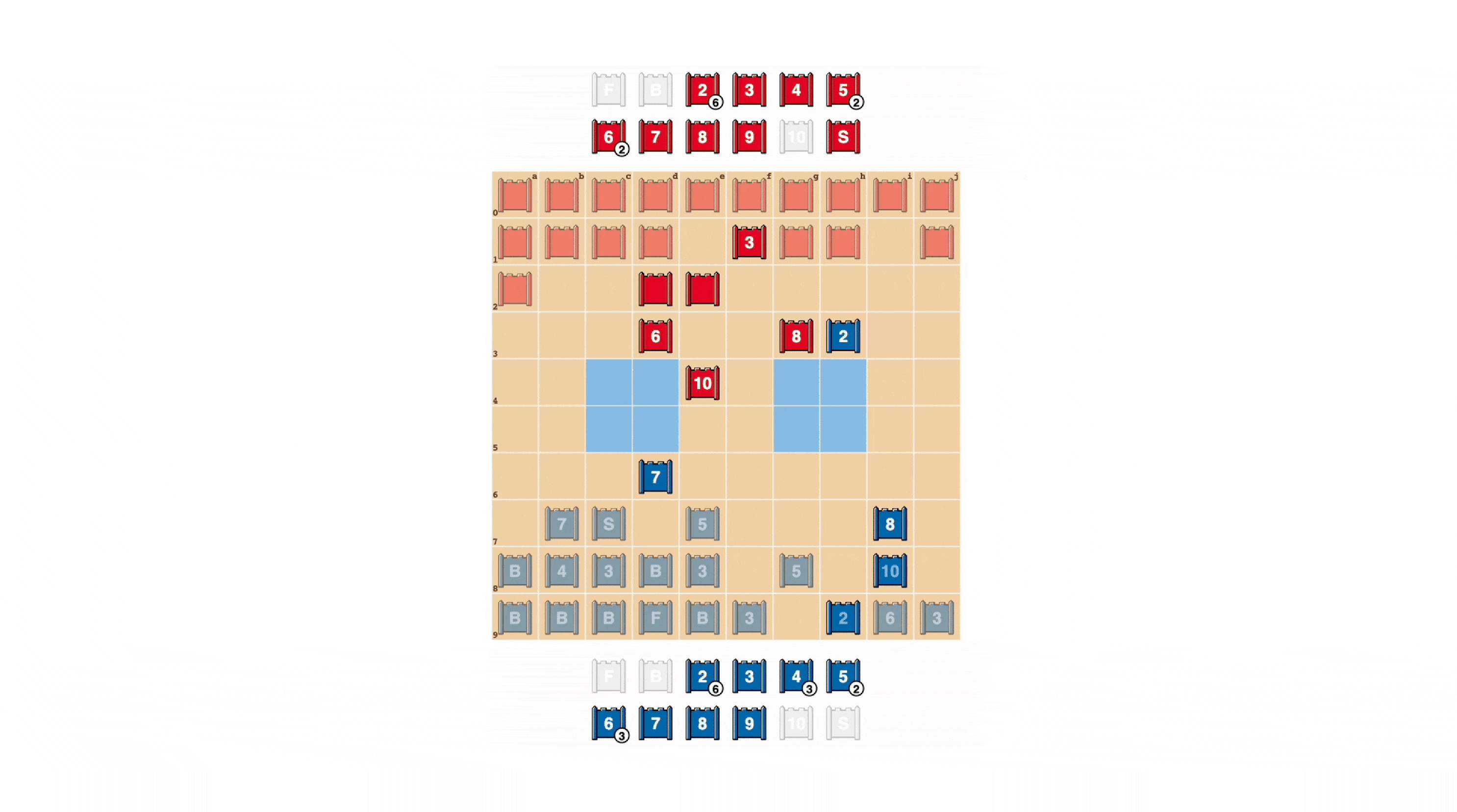
I giocatori di Stratego si sforzano di essere imprevedibili, quindi è utile mantenere nascoste le informazioni. DeepNash dimostra come valorizza le informazioni in modi piuttosto sorprendenti. Nell’esempio seguente, contro un giocatore umano, DeepNash (blu) ha sacrificato, tra gli altri pezzi, un 7 (Maggiore) e un 8 (Colonnello) all’inizio del gioco e di conseguenza è stato in grado di localizzare il 10 dell’avversario (Maresciallo), 9 (Generale), un 8 e due 7.
Questi sforzi hanno lasciato DeepNash in uno svantaggio materiale significativo; ha perso un 7 e un 8 mentre il suo avversario umano ha conservato tutti i suoi pezzi di valore 7 e superiore. Tuttavia, avendo informazioni solide sui pezzi grossi del suo avversario, DeepNash ha valutato le sue possibilità di vincita al 70% – e ha vinto.
L’arte del bluff
Come nel poker, un buon giocatore di Stratego a volte deve rappresentare la forza, anche quando è debole. DeepNash ha imparato una serie di tattiche di bluff di questo tipo. Nell’esempio seguente, DeepNash usa un 2 (uno Scout debole, sconosciuto al suo avversario) come se fosse un pezzo di alto rango, inseguendo l’8 conosciuto del suo avversario. L’avversario umano decide che l’inseguitore è molto probabilmente un 10, e quindi tenta per attirarlo in un’imboscata da parte della loro spia. Questa tattica di DeepNash, rischiando solo un pezzo minore, riesce a stanare ed eliminare la Spia del suo avversario, un pezzo critico.
Scopri di più guardando questi quattro video di partite integrali giocate da DeepNash contro esperti umani (anonimi): Gioco 1, Gioco 2, Gioco 3, Gioco 4.
“Il livello di gioco di DeepNash mi ha sorpreso. Non avevo mai sentito parlare di un giocatore Stratego artificiale che si avvicinasse al livello necessario per vincere una partita contro un giocatore umano esperto. Ma dopo aver giocato io stesso contro DeepNash, non sono rimasto sorpreso dal piazzamento tra i primi 3 che ha poi ottenuto sulla piattaforma Gravon. Mi aspetto che andrebbe molto bene se gli fosse permesso di partecipare ai Campionati del mondo umani.
– Vincent de Boer, coautore dell’articolo ed ex campione del mondo di Stratego
Direzioni future
Mentre abbiamo sviluppato DeepNash per il mondo altamente definito di Stratego, il nostro nuovo metodo R-NaD può essere applicato direttamente ad altri giochi a somma zero per due giocatori con informazioni sia perfette che imperfette. R-NaD ha il potenziale per generalizzare ben oltre le impostazioni di gioco a due giocatori per affrontare problemi del mondo reale su larga scala, che sono spesso caratterizzati da informazioni imperfette e spazi di stato astronomici.
Ci auguriamo inoltre che R-NaD possa aiutare a sbloccare nuove applicazioni dell’intelligenza artificiale in domini che presentano un gran numero di partecipanti umani o di intelligenza artificiale con obiettivi diversi che potrebbero non avere informazioni sulle intenzioni degli altri o su ciò che sta accadendo nel loro ambiente, come nel grande -ottimizzazione su vasta scala della gestione del traffico per ridurre i tempi di percorrenza degli autisti e le emissioni dei veicoli ad essi associati.
Nel creare un sistema di intelligenza artificiale generalizzabile che sia robusto di fronte all’incertezza, speriamo di portare ulteriormente le capacità di risoluzione dei problemi dell’intelligenza artificiale nel nostro mondo intrinsecamente imprevedibile.
Scopri di più su DeepNash leggendo il nostro articolo su Science.
Per i ricercatori interessati a provare R-NaD o a lavorare con il nostro metodo appena proposto, lo abbiamo reso open source il nostro codice.

