
Nel 2016 abbiamo introdotto AlphaGoil primo programma di intelligenza artificiale (AI) per sconfiggere gli umani nell’antico gioco del Go. Due anni dopo, il suo successore… AlphaZero – imparato da zero a padroneggiare Go, scacchi e shogi. Ora, in un articolo sulla rivista Naturedescriviamo MuZero, un significativo passo avanti nella ricerca di algoritmi di uso generale. MuZero padroneggia Go, scacchi, shogi e Atari senza bisogno che gli vengano spiegate le regole, grazie alla sua capacità di pianificare strategie vincenti in ambienti sconosciuti.
Per molti anni, i ricercatori hanno cercato metodi che permettessero sia di apprendere un modello che spieghi il loro ambiente, sia di poter utilizzare quel modello per pianificare la migliore linea d’azione. Fino ad ora, la maggior parte degli approcci ha avuto difficoltà a pianificare in modo efficace in ambiti, come Atari, dove le regole o le dinamiche sono generalmente sconosciute e complesse.
MuZero, introdotto per la prima volta in a documento preliminare nel 2019risolve questo problema imparando un modello che si concentra solo sugli aspetti più importanti dell’ambiente per la pianificazione. Combinando questo modello con la potente ricerca ad albero lookahead di AlphaZero, MuZero ha stabilito un nuovo risultato all’avanguardia sul benchmark Atari, eguagliando contemporaneamente le prestazioni di AlphaZero nelle classiche sfide di pianificazione di Go, scacchi e shogi. In tal modo, MuZero dimostra un significativo passo avanti nelle capacità degli algoritmi di apprendimento per rinforzo.

Generalizzazione a modelli sconosciuti
La capacità di pianificare è una parte importante dell’intelligenza umana, poiché ci consente di risolvere problemi e prendere decisioni sul futuro. Ad esempio, se vediamo formarsi nuvole scure, potremmo prevedere che pioverà e decidere di portare con noi un ombrello prima di uscire. Gli esseri umani apprendono rapidamente questa capacità e possono generalizzare a nuovi scenari, una caratteristica che vorremmo che avessero anche i nostri algoritmi.
I ricercatori hanno cercato di affrontare questa importante sfida nel campo dell’intelligenza artificiale utilizzando due approcci principali: ricerca anticipata o pianificazione basata su modelli.
I sistemi che utilizzano la ricerca anticipata, come AlphaZero, hanno ottenuto un notevole successo in giochi classici come dama, scacchi e poker, ma fanno affidamento sulla conoscenza delle dinamiche del loro ambiente, come le regole del gioco o un simulatore accurato. Ciò rende difficile applicarli ai complicati problemi del mondo reale, che sono tipicamente complessi e difficili da sintetizzare in regole semplici.
I sistemi basati su modelli mirano ad affrontare questo problema apprendendo un modello accurato delle dinamiche di un ambiente e quindi utilizzandolo per pianificare. Tuttavia, la complessità della modellazione di ogni aspetto di un ambiente ha fatto sì che questi algoritmi non siano in grado di competere in domini visivamente ricchi, come Atari. Fino ad ora, i migliori risultati su Atari provengono da sistemi privi di modello, come DQN, R2D2 E Agente57. Come suggerisce il nome, gli algoritmi senza modello non utilizzano un modello appreso e stimano invece quale sia l’azione migliore da intraprendere successivamente.
MuZero utilizza un approccio diverso per superare i limiti degli approcci precedenti. Invece di provare a modellare l’intero ambiente, MuZero si limita a modellare gli aspetti importanti per il processo decisionale dell’agente. Dopotutto, sapere che un ombrello ti manterrà asciutto è più utile che modellare lo schema delle gocce di pioggia nell’aria.
Nello specifico, MuZero modella tre elementi dell’ambiente fondamentali per la pianificazione:
- IL valore: quanto è buona la posizione attuale?
- IL politica: quale azione è meglio intraprendere?
- IL ricompensa: quanto è stata bella l’ultima azione?
Questi vengono tutti appresi utilizzando una rete neurale profonda e sono tutto ciò che serve a MuZero per capire cosa succede quando intraprende una determinata azione e per pianificare di conseguenza.



Questo approccio comporta un altro importante vantaggio: MuZero può utilizzare ripetutamente il modello appreso per migliorare la propria pianificazione, anziché raccogliere nuovi dati dall’ambiente. Ad esempio, nei test sulla suite Atari, questa variante – nota come MuZero Reanalyze – ha utilizzato il modello appreso il 90% delle volte per riprogrammare ciò che avrebbe dovuto essere fatto negli episodi precedenti.
Prestazioni MuZero
Abbiamo scelto quattro domini diversi per testare le capacità di MuZeros. Go, scacchi e shogi sono stati utilizzati per valutare le sue prestazioni su problemi di pianificazione impegnativi, mentre abbiamo utilizzato la suite Atari come punto di riferimento per problemi visivamente più complessi. In tutti i casi, MuZero ha stabilito un nuovo stato dell’arte per gli algoritmi di apprendimento per rinforzo, superando tutti gli algoritmi precedenti sulla suite Atari e eguagliando le prestazioni sovrumane di AlphaZero su Go, scacchi e shogi.

Abbiamo anche testato in modo più dettagliato la capacità di MuZero di pianificare con il suo modello appreso. Abbiamo iniziato con la classica sfida di pianificazione di precisione di Go, dove una singola mossa può fare la differenza tra vincere e perdere. Per confermare l’intuizione secondo cui una maggiore pianificazione dovrebbe portare a risultati migliori, abbiamo misurato quanto più forte può diventare una versione completamente addestrata di MuZero quando viene concesso più tempo per pianificare ogni mossa (vedere il grafico a sinistra di seguito). I risultati hanno mostrato che la forza di gioco aumenta di oltre 1000 Elo (una misura dell’abilità relativa di un giocatore) aumentando il tempo per mossa da un decimo di secondo a 50 secondi. Questo è simile alla differenza tra un forte giocatore amatoriale e il più forte giocatore professionista.
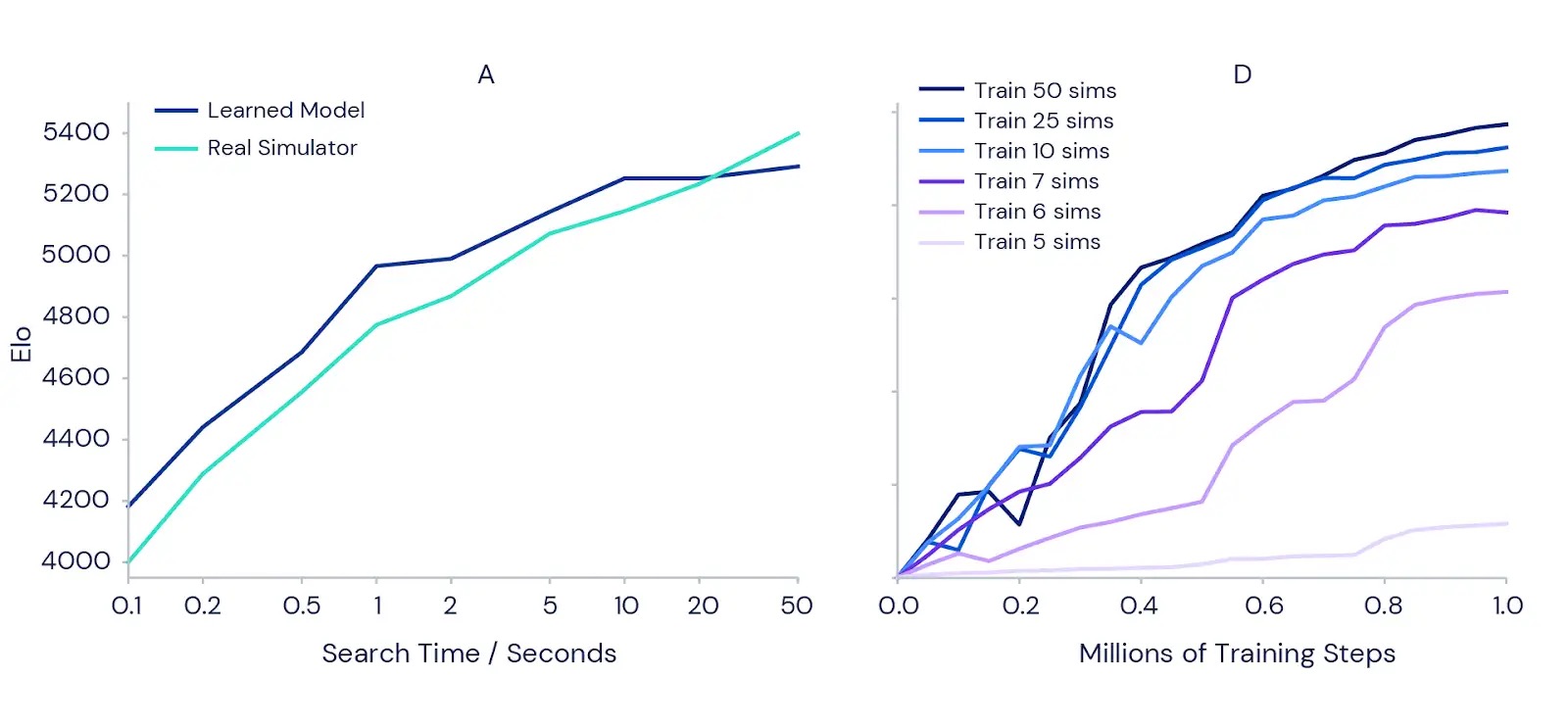
Per verificare se la pianificazione porta benefici anche durante la formazione, abbiamo eseguito una serie di esperimenti sul gioco Atari Ms Pac-Man (grafico a destra sopra) utilizzando istanze addestrate separate di MuZero. A ciascuno è stato consentito di considerare un numero diverso di simulazioni di pianificazione per mossa, da cinque a 50. I risultati hanno confermato che aumentare la quantità di pianificazione per ogni mossa consente a MuZero di apprendere più velocemente e di ottenere prestazioni finali migliori.
È interessante notare che, quando a MuZero è stato consentito di considerare solo sei o sette simulazioni per mossa – un numero troppo piccolo per coprire tutte le azioni disponibili in Ms Pac-Man – ha comunque ottenuto buone prestazioni. Ciò suggerisce che MuZero è in grado di generalizzare tra azioni e situazioni e non ha bisogno di cercare in modo esaustivo tutte le possibilità per apprendere in modo efficace.
Nuovi orizzonti
La capacità di MuZero sia di apprendere un modello del suo ambiente sia di utilizzarlo per pianificare con successo dimostra un progresso significativo nell’apprendimento per rinforzo e nella ricerca di algoritmi di uso generale. Il suo predecessore, AlphaZero, è già stato applicato a una serie di problemi complessi in chimica, fisica quantistica e oltre. Le idee alla base dei potenti algoritmi di apprendimento e pianificazione di MuZero possono aprire la strada per affrontare nuove sfide nella robotica, nei sistemi industriali e in altri ambienti caotici del mondo reale in cui le “regole del gioco” non sono note.
Link correlati:

