
Un recente Documento DeepMind sui rischi etici e sociali dei modelli linguistici ha individuato grandi modelli linguistici fuga di informazioni sensibili sui dati di formazione come un rischio potenziale che le organizzazioni che lavorano su questi modelli hanno la responsabilità di affrontare. Un altro documento recente mostra che simili rischi per la privacy possono sorgere anche nei modelli standard di classificazione delle immagini: un’impronta digitale di ogni singola immagine di addestramento può essere trovata incorporata nei parametri del modello e i malintenzionati potrebbero sfruttare tali impronte digitali per ricostruire i dati di addestramento dal modello.
Le tecnologie di miglioramento della privacy come la privacy differenziale (DP) possono essere implementate in fase di formazione per mitigare questi rischi, ma spesso comportano una riduzione significativa delle prestazioni del modello. In questo lavoro, facciamo progressi sostanziali verso lo sblocco dell’addestramento ad alta precisione dei modelli di classificazione delle immagini in condizioni di privacy differenziale.

La privacy differenziale era proposto come quadro matematico per catturare l’esigenza di proteggere i record individuali nel corso dell’analisi statistica dei dati (compreso l’addestramento di modelli di apprendimento automatico). Gli algoritmi DP proteggono gli individui da qualsiasi inferenza sulle caratteristiche che li rendono unici (inclusa la ricostruzione completa o parziale) iniettando rumore attentamente calibrato durante il calcolo della statistica o del modello desiderato. L’uso degli algoritmi DP fornisce garanzie di privacy robuste e rigorose sia in teoria che in pratica, ed è diventato di fatto uno standard di riferimento adottato da numerosi pubblico E privato organizzazioni.
L’algoritmo DP più popolare per il deep learning è la discesa del gradiente stocastico differenzialmente privato (DP-SGD), una modifica dell’SGD standard ottenuta ritagliando i gradienti dei singoli esempi e aggiungendo abbastanza rumore per mascherare il contributo di qualsiasi individuo a ciascun aggiornamento del modello:
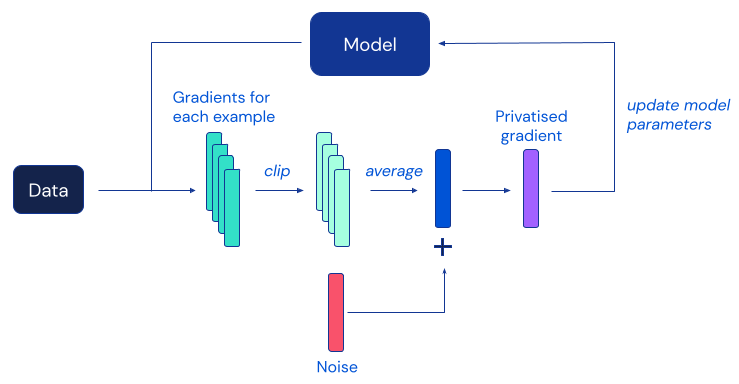
Sfortunatamente, lavori precedenti hanno scoperto che, nella pratica, la protezione della privacy fornita da DP-SGD spesso avviene a scapito di modelli significativamente meno accurati, il che rappresenta un grosso ostacolo all’adozione diffusa della privacy differenziale nella comunità del machine learning. Secondo prove empiriche di lavori precedenti, questo degrado dell’utilità in DP-SGD diventa più grave su modelli di rete neurale più grandi, compresi quelli utilizzati regolarmente per ottenere le migliori prestazioni su benchmark impegnativi di classificazione delle immagini.
Il nostro lavoro indaga questo fenomeno e propone una serie di semplici modifiche sia alla procedura di addestramento che all’architettura del modello, ottenendo un miglioramento significativo sull’accuratezza dell’addestramento DP sui parametri di classificazione standard delle immagini. L’osservazione più sorprendente emersa dalla nostra ricerca è che DP-SGD può essere utilizzato per addestrare in modo efficiente modelli molto più profondi di quanto si pensasse in precedenza, purché si garantisca che i gradienti del modello si comportino bene. Riteniamo che il sostanziale salto di prestazioni ottenuto dalla nostra ricerca abbia il potenziale per sbloccare applicazioni pratiche di modelli di classificazione delle immagini addestrati con garanzie formali di privacy.
La figura seguente riassume due dei nostri risultati principali: un miglioramento di circa il 10% su CIFAR-10 rispetto al lavoro precedente durante la formazione privata senza dati aggiuntivi e una precisione top-1 dell’86,7% su ImageNet durante la messa a punto privata di un modello pre- addestrato su un set di dati diverso, colmando quasi il divario con le migliori prestazioni non private.

Questi risultati sono raggiunti a 𝜺=8, un’impostazione standard per calibrare la forza della protezione offerta dalla privacy differenziale nelle applicazioni di machine learning. Facciamo riferimento al documento per una discussione di questo parametro, nonché per ulteriori risultati sperimentali ad altri valori di 𝜺 e anche su altri set di dati. Insieme al documento, stiamo anche rendendo open source la nostra implementazione per consentire ad altri ricercatori di verificare i nostri risultati e basarsi su di essi. Ci auguriamo che questo contributo possa aiutare altri interessati a trasformare in realtà la formazione pratica DP.
Scarica la nostra implementazione JAX su GitHub.

