
Una nuova definizione formale di agenzia fornisce principi chiari per la modellazione causale degli agenti di intelligenza artificiale e gli incentivi a cui devono far fronte
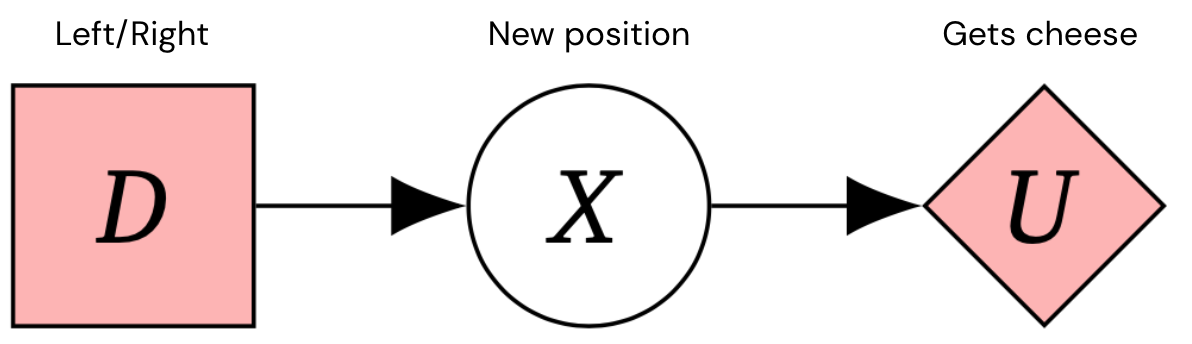
Vogliamo costruire sistemi di intelligenza generale artificiale (AGI) sicuri e allineati che perseguano gli obiettivi previsti dai suoi progettisti. Diagrammi di influenza causale (CID) sono un modo per modellare situazioni decisionali che ci consentono di ragionare incentivi per gli agenti. Ad esempio, ecco un CID per un processo decisionale di Markov in 1 fase, un quadro tipico per i problemi decisionali.

Mettendo in relazione le impostazioni di formazione con gli incentivi che modellano il comportamento degli agenti, i CID aiutano a evidenziare i rischi potenziali prima di formare un agente e possono ispirare progettazioni migliori degli agenti. Ma come facciamo a sapere se un CID è un modello accurato di una configurazione di addestramento?
Il nostro nuovo giornale, Alla scoperta degli agentiintroduce nuovi modi per affrontare questi problemi, tra cui:
- La prima definizione causale formale di agenti: Gli agenti sono sistemi che adatterebbero la loro politica se le loro azioni influenzassero il mondo in modo diverso
- Un algoritmo per scoprire agenti da dati empirici
- Una traduzione tra modelli causali e CID
- Risolvere le confusioni precedenti dovute a modelli causali errati degli agenti
Combinati, questi risultati forniscono un ulteriore livello di garanzia che non sia stato commesso un errore di modellazione, il che significa che i CID possono essere utilizzati per analizzare gli incentivi e le proprietà di sicurezza di un agente con maggiore sicurezza.
Esempio: modellare un mouse come agente
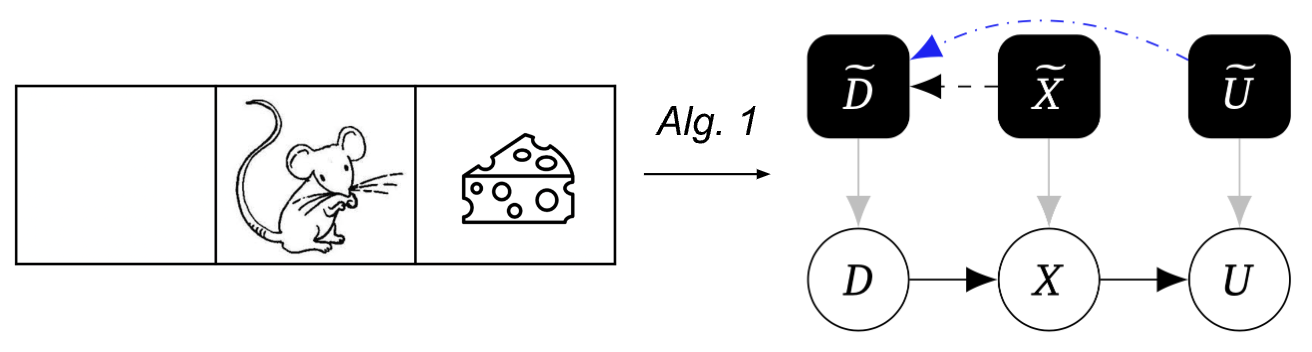
Per illustrare meglio il nostro metodo, consideriamo il seguente esempio costituito da un mondo contenente tre quadrati, con un mouse che parte dal quadrato centrale scegliendo di andare a sinistra o a destra, arrivando alla posizione successiva e quindi potenzialmente prendendo del formaggio. Il pavimento è ghiacciato, quindi il mouse potrebbe scivolare. A volte il formaggio è a destra, a volte a sinistra.

Questo può essere rappresentato dal seguente CID:
L’intuizione che il topo sceglierebbe un comportamento diverso per diverse impostazioni ambientali (gelidezza, distribuzione del formaggio) può essere catturata da un grafo causale meccanizzato, che per ciascuna variabile (a livello di oggetto) include anche una variabile di meccanismo che governa il modo in cui la variabile dipende dai suoi genitori. Fondamentalmente, consentiamo collegamenti tra variabili del meccanismo.
Questo grafico contiene nodi di meccanismi aggiuntivi in nero, che rappresentano la politica del topo e la distribuzione del ghiaccio e del formaggio.
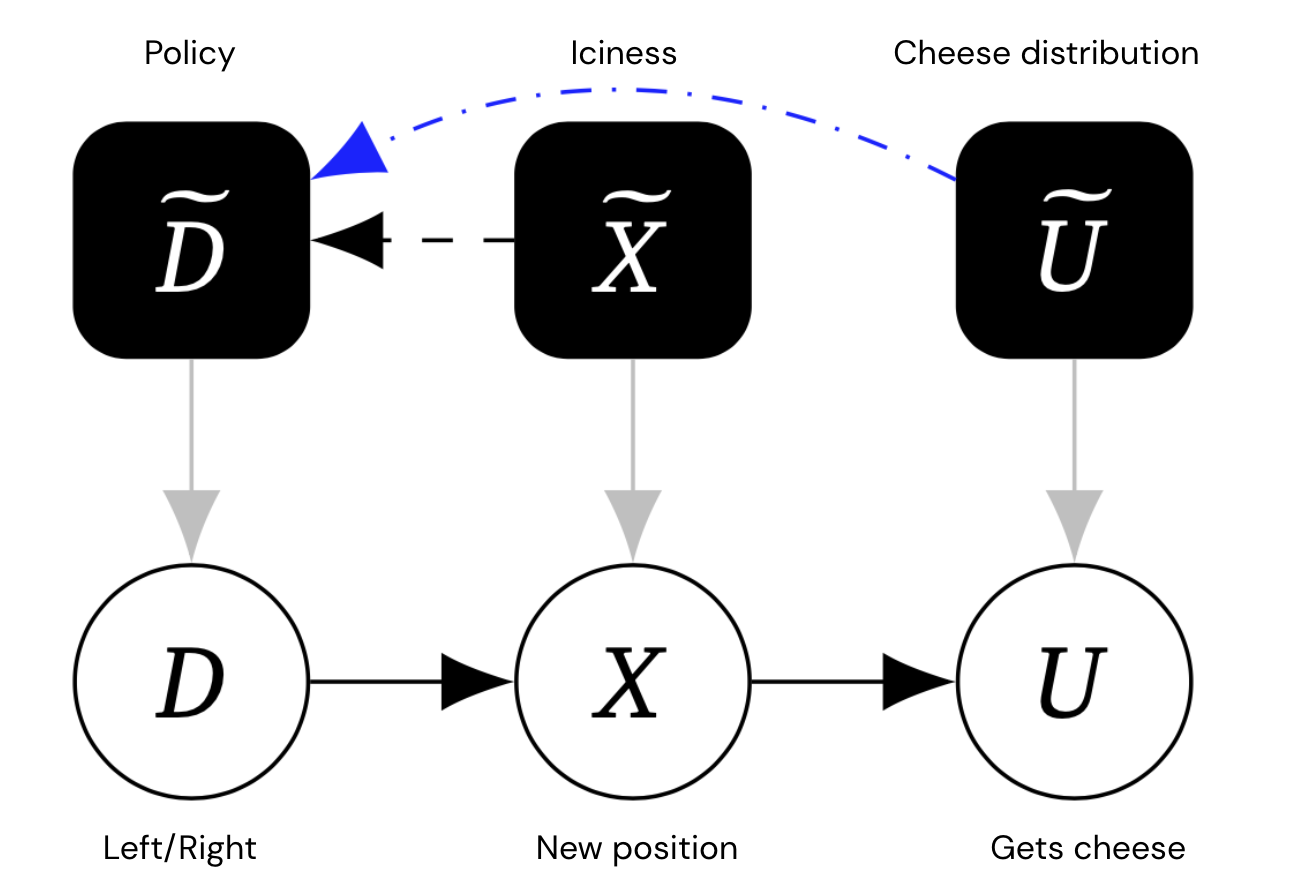
I confini tra i meccanismi rappresentano un’influenza causale diretta. I bordi blu sono speciali terminale bordi – più o meno, bordi del meccanismo A~ → B~ che sarebbero ancora lì, anche se la variabile a livello di oggetto A fosse stata modificata in modo che non avesse bordi in uscita.
Nell’esempio sopra, poiché U non ha figli, il suo bordo del meccanismo deve essere terminale. Ma il meccanismo bordo X~ → D~ non è terminale, perché se tagliamo X dal suo figlio U, il topo non adatterà più la sua decisione (perché la sua posizione non influenzerà se riceverà il formaggio).
Scoperta causale degli agenti
La scoperta causale deduce un grafico causale da esperimenti che coinvolgono interventi. In particolare, si può scoprire una freccia da una variabile A ad una variabile B intervenendo sperimentalmente su A e controllando se B risponde, anche se tutte le altre variabili sono mantenute fisse.
Il nostro primo algoritmo utilizza questa tecnica per scoprire il grafo causale meccanizzato:
Il nostro secondo algoritmo trasforma questo grafo causale meccanizzato in un grafo di gioco:
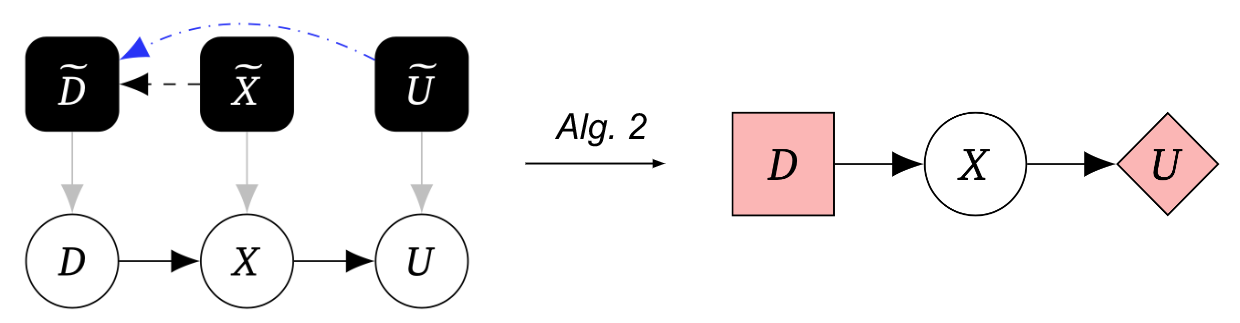
Nel loro insieme, l’Algoritmo 1 seguito dall’Algoritmo 2 ci consente di scoprire agenti da esperimenti causali, rappresentandoli utilizzando CID.
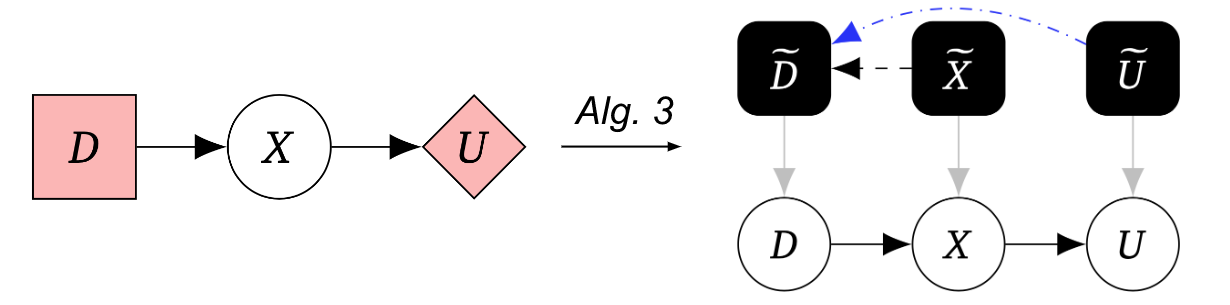
Il nostro terzo algoritmo trasforma il grafico del gioco in un grafico causale meccanizzato, permettendoci di tradurre tra le rappresentazioni del gioco e quelle del grafico causale meccanizzato sotto alcuni presupposti aggiuntivi:
Migliori strumenti di sicurezza per modellare gli agenti IA
Abbiamo proposto la prima definizione causale formale di agenti. Basandosi sulla scoperta causale, la nostra intuizione chiave è che gli agenti sono sistemi che adattano il loro comportamento in risposta ai cambiamenti nel modo in cui le loro azioni influenzano il mondo. In effetti, i nostri algoritmi 1 e 2 descrivono un preciso processo sperimentale che può aiutare a valutare se un sistema contiene un agente.
L’interesse per la modellizzazione causale dei sistemi di intelligenza artificiale è in rapida crescita e la nostra ricerca fonda questa modellizzazione su esperimenti di scoperta causale. Il nostro articolo dimostra il potenziale del nostro approccio migliorando l’analisi della sicurezza di diversi sistemi di intelligenza artificiale di esempio e mostra che la causalità è un quadro utile per scoprire se esiste un agente in un sistema – una preoccupazione chiave per valutare i rischi dell’AGI.
Vuoi saperne di più? Dai un’occhiata al nostro carta. Feedback e commenti sono i benvenuti.

