
L’apprendimento per rinforzo (RL) ha fatto enormi progressi negli ultimi anni nell’affrontare i problemi della vita reale – e l’RL offline lo ha reso ancora più pratico. Invece di interazioni dirette con l’ambiente, ora possiamo addestrare molti algoritmi da un singolo set di dati preregistrato. Tuttavia, perdiamo i vantaggi pratici in termini di efficienza dei dati della RL offline quando valutiamo le politiche in questione.
Ad esempio, quando si addestrano manipolatori robotici, le risorse del robot sono generalmente limitate e l’addestramento di molte politiche tramite RL offline su un singolo set di dati ci offre un grande vantaggio in termini di efficienza dei dati rispetto al RL online. Valutare ciascuna policy è un processo costoso, che richiede l’interazione con il robot migliaia di volte. Quando scegliamo l’algoritmo, gli iperparametri e una serie di passaggi di training migliori, il problema diventa rapidamente intrattabile.
Per rendere RL più applicabile alle applicazioni del mondo reale come la robotica, proponiamo di utilizzare una procedura di valutazione intelligente per selezionare la policy da implementare, chiamata selezione di policy offline attiva (A-OPS). In A-OPS utilizziamo il set di dati preregistrati e consentiamo interazioni limitate con l’ambiente reale per migliorare la qualità della selezione.
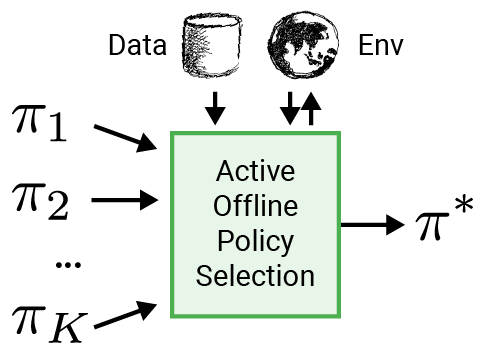
Per ridurre al minimo le interazioni con l’ambiente reale, implementiamo tre funzionalità chiave:
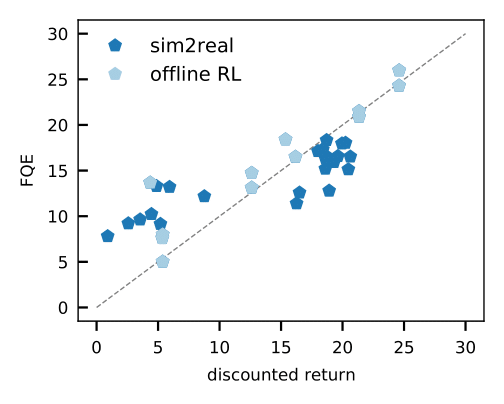
- La valutazione delle politiche fuori politica, come la valutazione Q adattata (FQE), ci consente di fare un’ipotesi iniziale sulle prestazioni di ciascuna politica sulla base di un set di dati offline. Si correla bene con le prestazioni reali in molti ambienti, inclusa la robotica del mondo reale dove viene applicata per la prima volta.
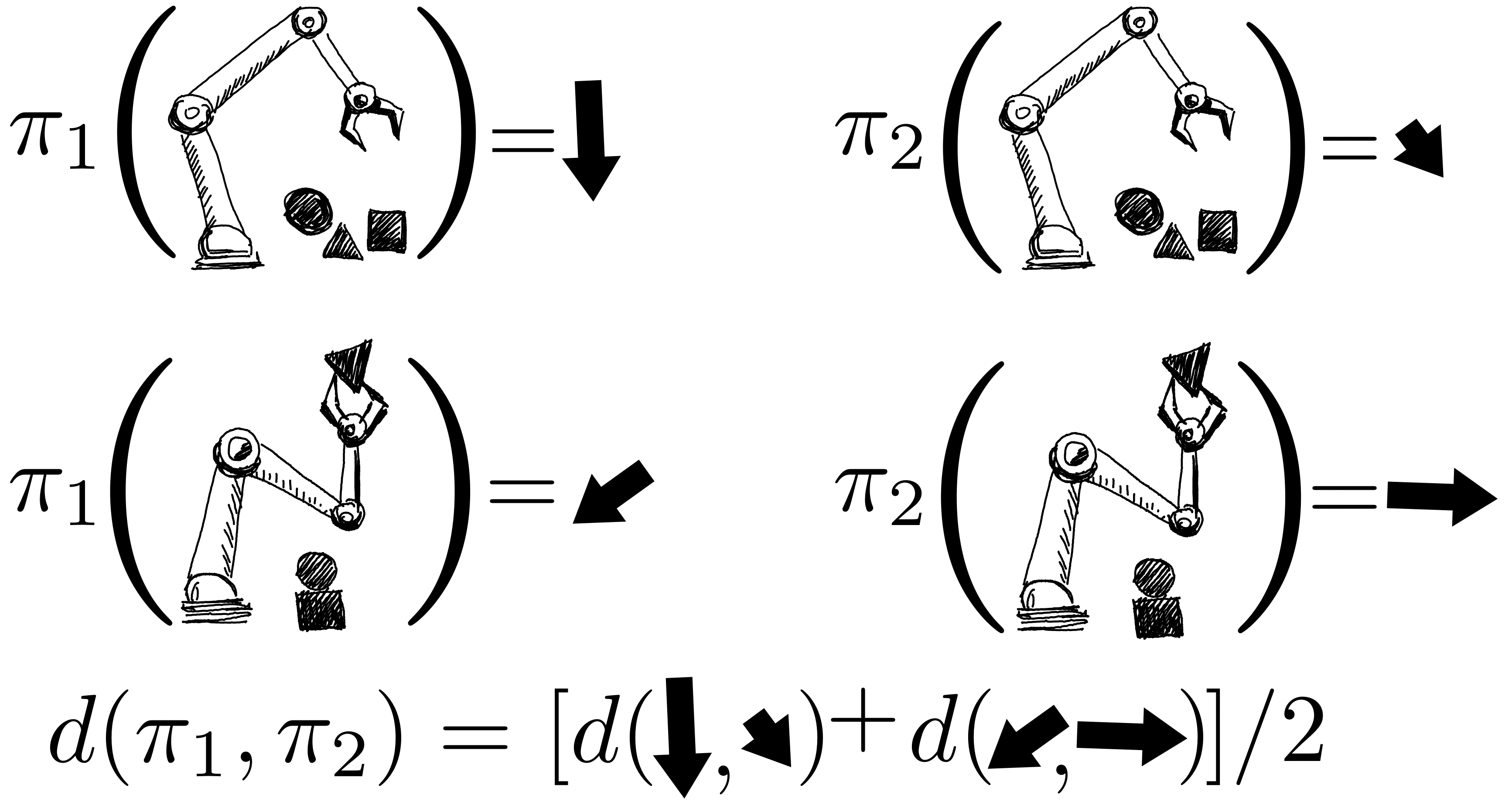
I rendimenti delle politiche sono modellati congiuntamente utilizzando un processo gaussiano, in cui le osservazioni includono i punteggi FQE e un piccolo numero di rendimenti episodici appena raccolti dal robot. Dopo aver valutato una policy, acquisiamo conoscenza di tutte le policy perché le loro distribuzioni sono correlate attraverso il kernel tra coppie di policy. Il nucleo presuppone che se le politiche intraprendono azioni simili – come spostare la pinza robotica in una direzione simile – tendono ad avere rendimenti simili.
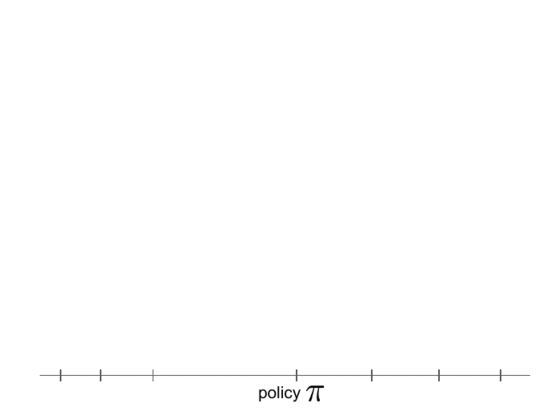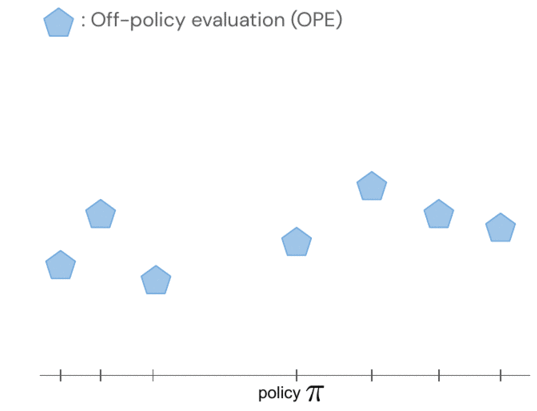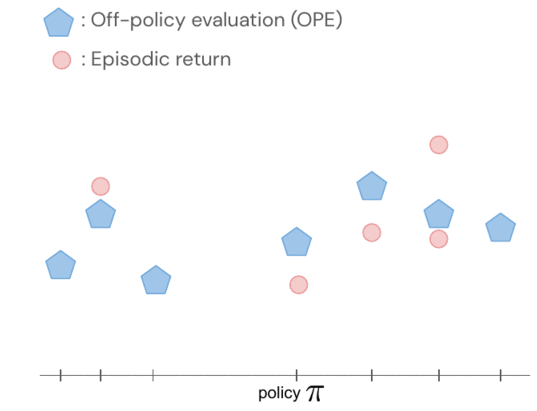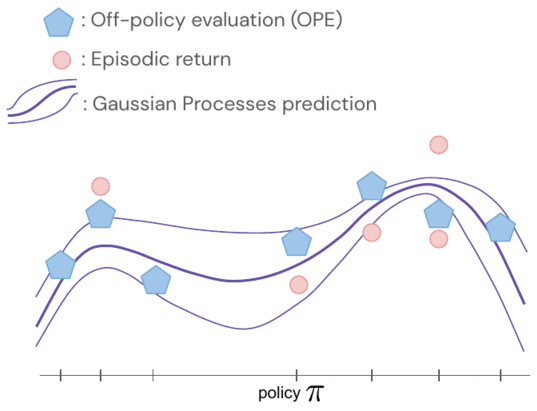
- Per essere più efficienti in termini di dati, applichiamo l’ottimizzazione bayesiana e diamo priorità alle politiche più promettenti da valutare successivamente, vale a dire quelle che hanno prestazioni previste elevate e ampia varianza.
Abbiamo dimostrato questa procedura in numerosi ambienti in diversi domini: dm-control, Atari, robotica simulata e reale. L’uso dell’A-OPS riduce rapidamente il rammarico e, con un numero moderato di valutazioni politiche, identifichiamo la politica migliore.
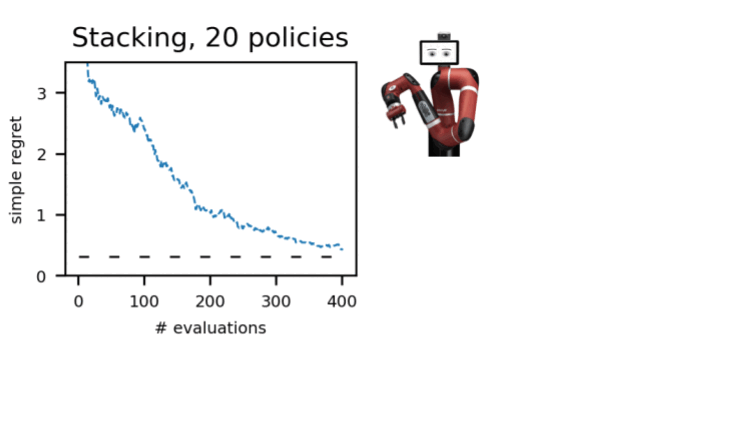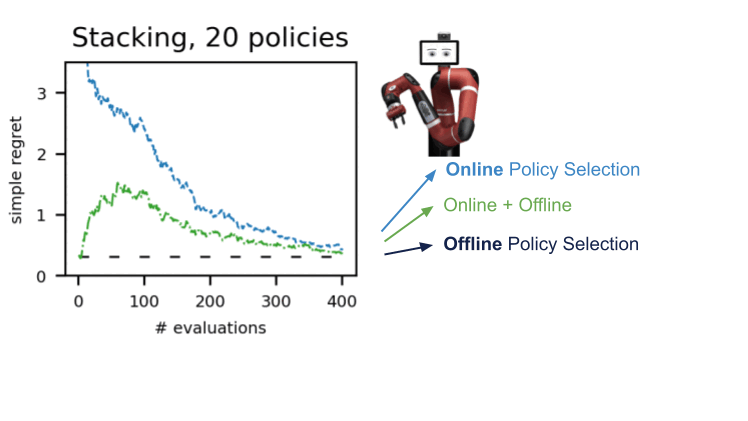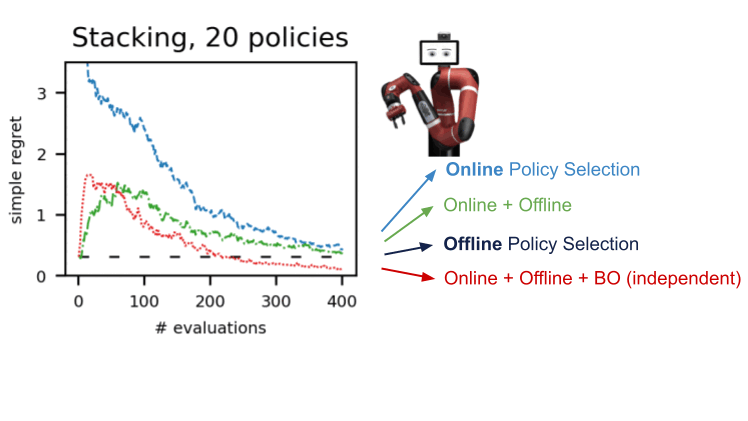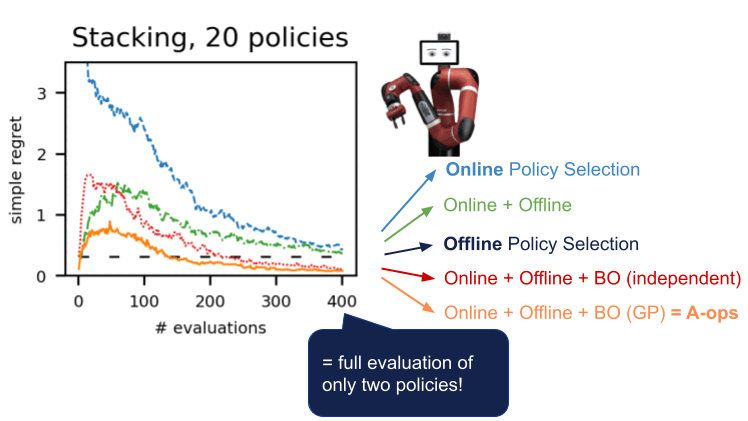
I nostri risultati suggeriscono che è possibile effettuare una selezione efficace delle policy offline con solo un numero limitato di interazioni ambientali utilizzando i dati offline, il kernel speciale e l’ottimizzazione bayesiana. Il codice per A-OPS è open source e disponibile su GitHub con un set di dati di esempio da provare.

