
Una nuova ricerca propone un quadro per la valutazione di modelli generici contro nuove minacce
Per essere pionieri in modo responsabile e all’avanguardia nella ricerca sull’intelligenza artificiale (AI), dobbiamo identificare le nuove capacità e i nuovi rischi nei nostri sistemi di intelligenza artificiale il prima possibile.
I ricercatori sull’intelligenza artificiale utilizzano già una serie di parametri di valutazione per identificare comportamenti indesiderati nei sistemi di intelligenza artificiale, come sistemi di intelligenza artificiale che rilasciano dichiarazioni fuorvianti, decisioni distorte o ripetono contenuti protetti da copyright. Ora, mentre la comunità dell’intelligenza artificiale costruisce e distribuisce un’intelligenza artificiale sempre più potente, dobbiamo espandere il portafoglio di valutazioni per includere la possibilità di farlo rischi estremi da modelli di IA generici che hanno forti capacità di manipolazione, inganno, attacco informatico o altre capacità pericolose.
Nel nostro ultimo documentopresentiamo un quadro per la valutazione di queste nuove minacce, scritto in collaborazione con colleghi dell’Università di Cambridge, Università di Oxford, Università di Toronto, Université de Montréal, OpenAI, Anthropic, Alignment Research Center, Centre for Long-Term Resilience e Centre for la governance dell’IA.
Le valutazioni della sicurezza dei modelli, comprese quelle che valutano i rischi estremi, saranno una componente fondamentale dello sviluppo e della diffusione sicura dell’IA.
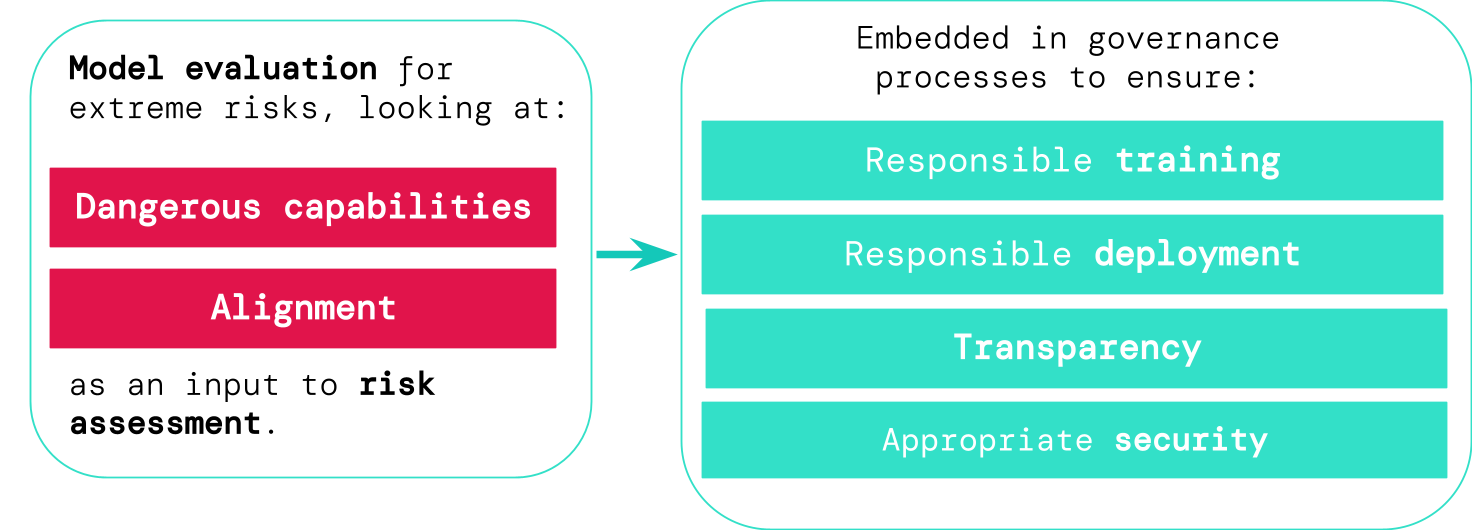
Valutazione dei rischi estremi
I modelli generici in genere apprendono le proprie capacità e comportamenti durante l’addestramento. Tuttavia, i metodi esistenti per guidare il processo di apprendimento sono imperfetti. Per esempio, ricerca precedente presso Google DeepMind ha esplorato come i sistemi di intelligenza artificiale possono imparare a perseguire obiettivi indesiderati anche quando li premiamo correttamente per un buon comportamento.
Gli sviluppatori responsabili di IA devono guardare avanti e anticipare i possibili sviluppi futuri e i nuovi rischi. Dopo i continui progressi, i futuri modelli generici potrebbero apprendere una serie di funzionalità pericolose per impostazione predefinita. Ad esempio, è plausibile (anche se incerto) che i futuri sistemi di intelligenza artificiale saranno in grado di condurre operazioni informatiche offensive, ingannare abilmente gli esseri umani nel dialogo, manipolare gli esseri umani inducendoli a compiere azioni dannose, progettare o acquisire armi (ad esempio biologiche, chimiche), mettere a punto e gestire altri sistemi di intelligenza artificiale ad alto rischio su piattaforme di cloud computing o assistere gli esseri umani in una qualsiasi di queste attività.
Le persone con intenzioni dannose che accedono a tali modelli potrebbero farlo misus le loro capacità. Oppure, a causa di fallimenti di allineamento, questi modelli di intelligenza artificiale potrebbero intraprendere azioni dannose anche senza che nessuno lo intenda.
La valutazione del modello ci aiuta a identificare questi rischi in anticipo. Nel nostro quadro, gli sviluppatori di intelligenza artificiale utilizzerebbero la valutazione del modello per scoprire:
- In che misura un modello ha determinate “capacità pericolose” che potrebbero essere utilizzati per minacciare la sicurezza, esercitare influenza o eludere la supervisione.
- In che misura il modello è incline ad applicare le sue capacità per causare danni (ovvero l’allineamento del modello). Le valutazioni di allineamento dovrebbero confermare che il modello si comporta come previsto anche in una gamma molto ampia di scenari e, ove possibile, dovrebbero esaminare il funzionamento interno del modello.
I risultati di queste valutazioni aiuteranno gli sviluppatori di intelligenza artificiale a capire se sono presenti gli ingredienti sufficienti per un rischio estremo. I casi più ad alto rischio coinvolgeranno molteplici capacità pericolose combinate insieme. Non è necessario che il sistema AI fornisca tutti gli ingredienti, come mostrato in questo diagramma:
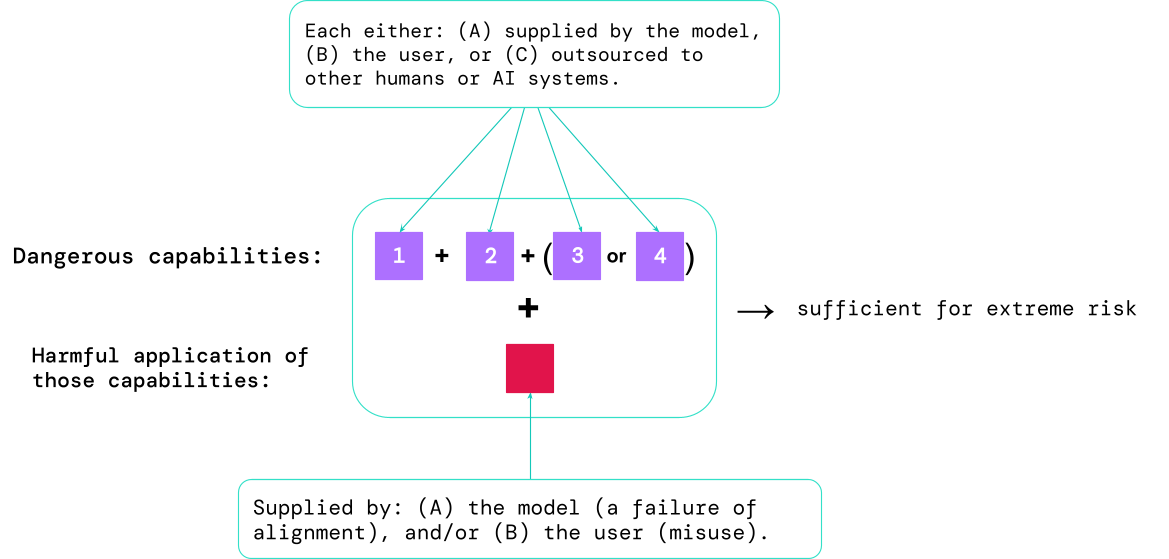
Una regola pratica: la comunità dell’intelligenza artificiale dovrebbe considerare un sistema di intelligenza artificiale come altamente pericoloso se ha un profilo di capacità sufficiente a causare danni estremi, assumendo è abusato o mal allineato. Per implementare un sistema del genere nel mondo reale, uno sviluppatore di intelligenza artificiale dovrebbe dimostrare uno standard di sicurezza insolitamente elevato.
Valutazione del modello come infrastruttura critica di governance
Se disponiamo di strumenti migliori per identificare quali modelli sono rischiosi, le aziende e le autorità di regolamentazione possono garantire meglio:
- Formazione responsabile: Vengono prese decisioni responsabili su se e come addestrare un nuovo modello che mostri i primi segnali di rischio.
- Distribuzione responsabile: Vengono prese decisioni responsabili su se, quando e come implementare modelli potenzialmente rischiosi.
- Trasparenza: Le informazioni utili e utilizzabili vengono comunicate alle parti interessate, per aiutarle a prepararsi o a mitigare i potenziali rischi.
- Sicurezza adeguata: Forti controlli e sistemi di sicurezza delle informazioni vengono applicati a modelli che potrebbero comportare rischi estremi.
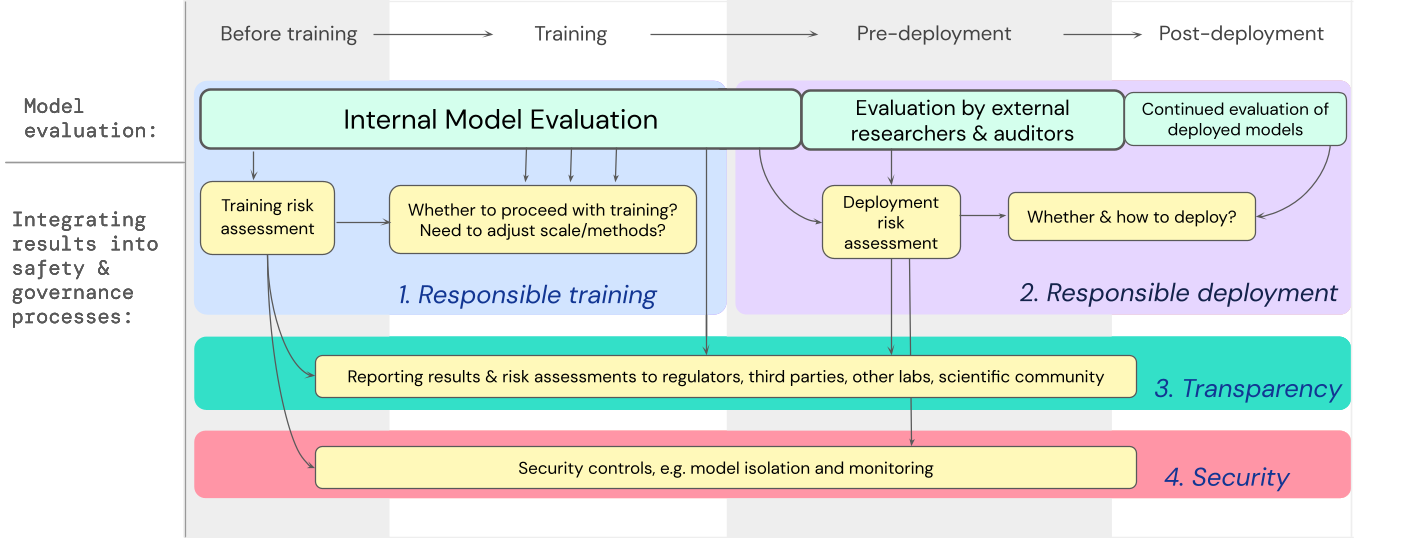
Abbiamo sviluppato un modello su come le valutazioni dei modelli per i rischi estremi dovrebbero alimentare decisioni importanti sulla formazione e l’implementazione di un modello generale altamente capace. Lo sviluppatore conduce valutazioni e sovvenzioni accesso al modello strutturato a ricercatori esterni sulla sicurezza e revisori modello quindi possono condurre valutazioni aggiuntive I risultati della valutazione possono quindi informare le valutazioni del rischio prima della formazione e dell’implementazione del modello.
Guardando avanti
Importante Presto lavoro sulla valutazione dei modelli per i rischi estremi è già in corso presso Google DeepMind e altrove. Ma sono necessari molti più progressi – sia tecnici che istituzionali – per costruire un processo di valutazione che cogli tutti i possibili rischi e aiuti a salvaguardarsi dalle sfide future ed emergenti.
La valutazione del modello non è una panacea; alcuni rischi potrebbero sfuggire, ad esempio, perché dipendono troppo da fattori esterni al modello, come ad es complesse forze sociali, politiche ed economiche nella società. La valutazione del modello deve essere combinata con altri strumenti di valutazione del rischio e con una più ampia dedizione alla sicurezza da parte dell’industria, del governo e della società civile.
Il recente blog di Google sull’intelligenza artificiale responsabile afferma che “pratiche individuali, standard di settore condivisi e solide politiche governative sarebbero essenziali per ottenere l’intelligenza artificiale nel modo giusto”. Ci auguriamo che molti altri che lavorano nel campo dell’intelligenza artificiale e nei settori interessati da questa tecnologia si uniscano per creare approcci e standard per lo sviluppo e l’implementazione sicura dell’intelligenza artificiale a beneficio di tutti.
Riteniamo che disporre di processi per monitorare l’emergere di proprietà rischiose nei modelli e per rispondere adeguatamente ai risultati preoccupanti sia una parte fondamentale dell’essere uno sviluppatore responsabile che opera alla frontiera delle capacità dell’intelligenza artificiale.

