
La tecnologia utilizzata nel mondo reale deve inevitabilmente affrontare sfide impreviste. Queste sfide sorgono perché l’ambiente in cui la tecnologia è stata sviluppata è diverso dall’ambiente in cui verrà utilizzata. Quando una tecnologia si trasferisce con successo diciamo che generalizza. In un sistema multiagentecome la tecnologia dei veicoli autonomi, ci sono due possibili fonti di difficoltà di generalizzazione: (1) variazione dell’ambiente fisico come cambiamenti del tempo o dell’illuminazione e (2) variazione dell’ambiente sociale: cambiamenti nel comportamento di altri individui interagenti. Gestire la variazione dell’ambiente sociale è importante almeno quanto gestire la variazione dell’ambiente fisico, tuttavia è stato molto meno studiato.
Come esempio di ambiente sociale, considera come le auto a guida autonoma interagiscono sulla strada con altre auto. Ogni vettura ha un incentivo a trasportare il proprio passeggero il più rapidamente possibile. Tuttavia, questa competizione può portare ad uno scarso coordinamento (congestione stradale) che si ripercuote negativamente su tutti. Se le auto funzionassero in modo cooperativo, più passeggeri potrebbero arrivare a destinazione più rapidamente. Questo conflitto è chiamato a dilemma sociale.
Tuttavia, non tutte le interazioni sono dilemmi sociali. Ad esempio, ci sono sinergico interazioni nel software open source, ci sono a somma zero interazioni nello sport e problemi di coordinazione sono al centro delle catene di fornitura. Affrontare ciascuna di queste situazioni richiede un approccio molto diverso.
L’apprendimento per rinforzo multi-agente fornisce strumenti che ci consentono di esplorare come gli agenti artificiali possono interagire tra loro e con individui non familiari (come gli utenti umani). Si prevede che questa classe di algoritmi funzioni meglio se testata per le loro capacità di generalizzazione sociale rispetto ad altre. Tuttavia, fino ad ora, non esisteva un punto di riferimento sistematico per valutare questo aspetto.
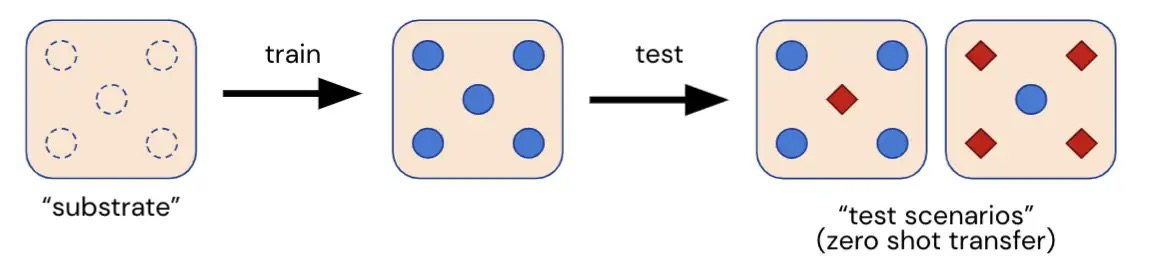
Qui presentiamo Melting Pot, una suite di valutazione scalabile per l’apprendimento di rinforzo multi-agente. Melting Pot valuta la generalizzazione a nuove situazioni sociali che coinvolgono individui familiari e non familiari ed è stato progettato per testare un’ampia gamma di interazioni sociali come: cooperazione, competizione, inganno, reciprocità, fiducia, testardaggine e così via. Melting Pot offre ai ricercatori una serie di 21 “substrati” MARL (giochi multi-agente) su cui addestrare gli agenti e oltre 85 scenari di test unici su cui valutare questi agenti addestrati. Le prestazioni degli agenti in questi scenari di test prolungati quantificano se gli agenti:
- Ottenere buoni risultati in una serie di situazioni sociali in cui gli individui sono interdipendenti,
- Interagire in modo efficace con persone sconosciute non viste durante l’allenamento,
- Superare un test di universalizzazione: rispondere positivamente alla domanda “e se tutti si comportassero così?”
Il punteggio risultante può quindi essere utilizzato per classificare diversi algoritmi RL multi-agente in base alla loro capacità di farlo generalizzare a nuove situazioni sociali.
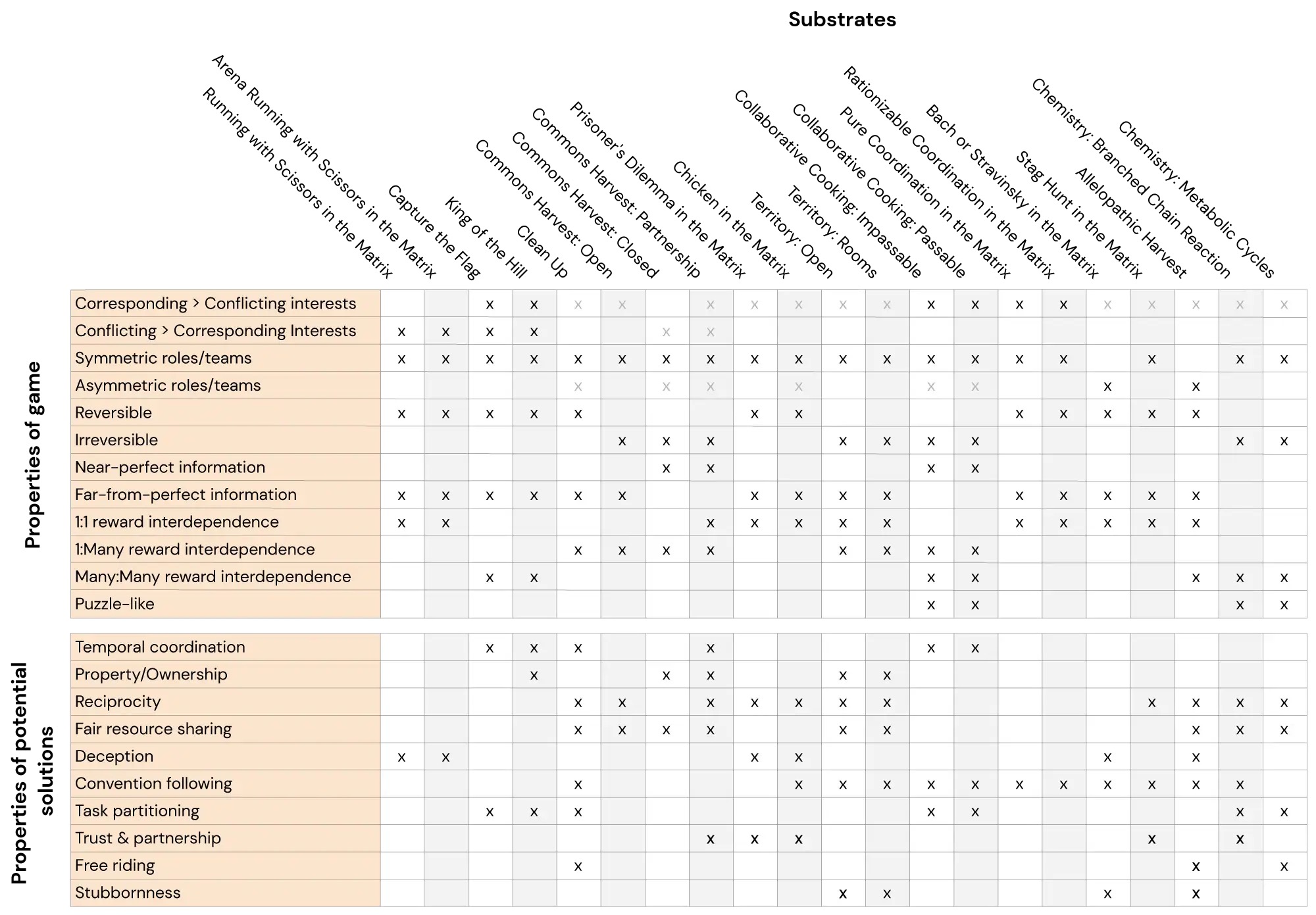
Ci auguriamo che Melting Pot diventi un punto di riferimento standard per l’apprendimento di rinforzo multi-agente. Abbiamo intenzione di mantenerlo e di estenderlo nei prossimi anni per coprire più interazioni sociali e scenari di generalizzazione.
Scopri di più dal nostro Pagina GitHub.

