
Utilizzi GPT-4o, GPT-4o Mini o GPT-3.5 Turbo? Comprendere i costi associati a ciascun modello è fondamentale per gestire il budget in modo efficace. Monitorando l'utilizzo a livello di attività, ottieni una prospettiva dettagliata dei costi associati al tuo progetto. Esploriamo come monitorare e gestire in modo efficiente l'utilizzo del prezzo dell'API OpenAI nelle sezioni seguenti.

Prezzo dell'API OpenAI
Questi sono i prezzi per 1 milione di token:
| Modello | Token di input (per 1 milione) | Gettoni di output (per 1 milione) |
| GPT-3.5-Turbo | $ 3,00 | $ 6,00 |
| GPT-4 | $ 30,00 | $ 60,00 |
| GPT-4o | $ 2,50 | $ 10,00 |
| GPT-4o-mini | $ 0,15 | $ 0,60 |
- GPT-4o-mini è l'opzione più conveniente, costa molto meno degli altri modelli, con una lunghezza del contesto di 16k, che lo rende ideale per attività leggere che non richiedono l'elaborazione di grandi quantità di token di input o output.
- GPT-4 è il modello più costoso, con una lunghezza del contesto di 32k, che fornisce prestazioni ineguagliabili per attività che richiedono estese interazioni input-output o ragionamenti complessi.
- GPT-4o offre un'opzione bilanciata per applicazioni ad alto volume, combinando un costo inferiore con una maggiore lunghezza del contesto di 128k, rendendolo adatto per attività che richiedono un'elaborazione dettagliata e ad alto contesto su larga scala.
- GPT-3.5-Turbocon una lunghezza del contesto di 16k, non è un'opzione multimodale ed elabora solo l'input di testo, offrendo una via di mezzo in termini di costo e funzionalità.
Per costi ridotti puoi prendere in considerazione l'API Batch che viene addebitata con il 50% in meno sia sui token di input che sui token di output. Gli input memorizzati nella cache aiutano anche a ridurre i costi:
Input memorizzati nella cache: gli input memorizzati nella cache si riferiscono ai token che sono stati precedentemente elaborati dal modello, consentendo un riutilizzo più rapido ed economico nelle richieste successive. Riduce i costi dei token di input del 50%.
API Batch: l'API Batch consente di inviare più richieste insieme, elaborarle in blocco e fornire la risposta entro una finestra di 24 ore.
Costi nell'utilizzo effettivo
Puoi sempre controllare la dashboard di OpenAI per monitorare il tuo utilizzo e controllare l'attività per vedere il numero di richieste inviate: Piattaforma OpenAI.
Concentriamoci sul monitoraggio per richiesta per avere un'idea a livello di attività. Inviamo alcuni suggerimenti ai modelli e stimiamo il costo sostenuto.
from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(api_key = "API-KEY")
# Models and costs per 1M tokens
models = (
{"name": "gpt-3.5-turbo", "input_cost": 3.00, "output_cost": 6.00},
{"name": "gpt-4", "input_cost": 30.00, "output_cost": 60.00},
{"name": "gpt-4o", "input_cost": 2.50, "output_cost": 10.00},
{"name": "gpt-4o-mini", "input_cost": 0.15, "output_cost": 0.60}
)
# A question to ask the models
question = "What's the largest city in India?"
# Initialize an empty list to store results
results = ()
# Loop through each model and send the request
for model in models:
completion = client.chat.completions.create(
model=model("name"),
messages=(
{"role": "user", "content": question}
)
)
# Extract the response content and token usage from the completion
response_content = completion.choices(0).message.content
input_tokens = completion.usage.prompt_tokens
output_tokens = completion.usage.completion_tokens
total_tokens = completion.usage.total_tokens
model_name = completion.model
# Calculate the cost based on token usage (cost per million tokens)
input_cost = (input_tokens / 1_000_000) * model("input_cost")
output_cost = (output_tokens / 1_000_000) * model("output_cost")
total_cost = input_cost + output_cost
# Append the result to the results list
results.append({
"Model": model_name,
"Input Tokens": input_tokens,
"Output Tokens": output_tokens,
"Total cost": total_cost,
"Response": response_content
})
import pandas as pd
# display the results in a table format
df = pd.DataFrame(results)
df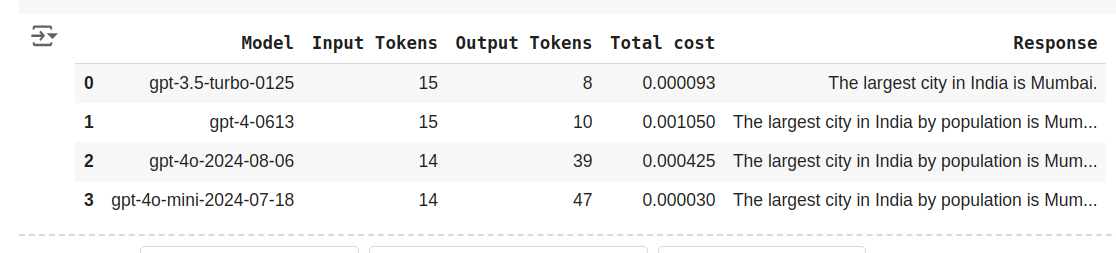
I costi sono rispettivamente $ 0,000093, $ 0,001050, $ 0,000425, $ 0,000030 per GPT-3.5-Turbo, GPT-4, GPT-4o e GPT-4o-mini. Il costo dipende sia dai token di input che dai token di output e possiamo vedere che, nonostante GPT-4o-mini generi 47 token per la domanda “Qual è la città più grande dell'India”, è il più economico tra tutti gli altri modelli qui.
Nota: i token sono una sequenza di caratteri e non sono esattamente parole e si noti che i token di input sono diversi nonostante il prompt sia lo stesso poiché utilizzano un tokenizzatore diverso.
Come ridurre i costi?
Imposta un limite massimo per i token massimi
question = "Explain VAE?"
completion = client.chat.completions.create(
model="gpt-4o-mini-2024-07-18",
messages=(
{"role": "user", "content": question}
),
max_tokens=50 # Set the desired upper limit for output tokens
)
print("Output Tokens: ",completion.usage.completion_tokens, "\n")
print("Output: ", completion.choices(0).message.content)Limitare i token di output aiuta a ridurre i costi e ciò consentirà anche al modello di concentrarsi maggiormente sulla risposta. Ma in questo caso è fondamentale scegliere un numero appropriato per il limite.
API batch
L'utilizzo dell'API Batch riduce i costi del 50% sia sui token di input che sui token di output, l'unico compromesso qui è che ci vuole del tempo per ottenere le risposte (può essere fino a 24 ore a seconda del numero di richieste).
question="What's a tokenizer"Creazione di un dizionario con parametri di richiesta per una richiesta POST.
input_dict = {
"custom_id": f"request-1",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini-2024-07-18",
"messages": (
{
"role": "user",
"content": question
}
),
"max_tokens": 100
}
}Scrittura di input_dict serializzato in un file JSONL.
import json
request_file = "/content/batch_request_file.jsonl"
with open(request_file, 'w') as f:
f.write(json.dumps(input_dict))
f.write('\n')
print(f"Successfully wrote a dictionary to {request_file}.")Invio di una richiesta batch utilizzando 'client.batches.create'
from openai import OpenAI
client = OpenAI(api_key = "API-KEY")
batch_input_file = client.files.create(
file=open(request_file, "rb"),
purpose="batch"
)
batch_input_file_id = batch_input_file.id
input_batch = client.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "GPT4o-Mini-Test"
}
)Controllando lo stato del batch, potrebbero essere necessarie fino a 24 ore per ottenere la risposta. Se il numero di richieste o batch è inferiore, dovrebbe essere abbastanza veloce (come in questo esempio).
status_response = client.batches.retrieve(input_batch.id)
print(input_batch.id,status_response.status, status_response.request_counts)
completed BatchRequestCounts(completed=1, failed=0, total=1)
if status_response.status == 'completed':
output_file_id = status_response.output_file_id
# Retrieve the content of the output file
output_response = client.files.content(output_file_id)
output_content = output_response.content
# Write the content to a file
with open('/content/batch_output.jsonl', 'wb') as f:
f.write(output_content)
print("Batch results saved to batch_output.jsonl")Questa è la risposta che ho ricevuto nel file JSONL:
"content": "A tokenizer is a tool or process used in natural language
processing (NLP) and text analysis that splits a stream of text into
smaller, manageable pieces called tokens. These tokens can represent various
data units such as words, phrases, symbols, or other meaningful elements in
the text.\\n\\nThe process of tokenization is crucial for various NLP
applications, including:\\n\\n1. **Text Analysis**: Breaking down text into
components makes it easier to analyze, allowing for tasks like frequency
analysis, sentiment analysis, and more"
Conclusione
Comprendere e gestire API ChatGPT Il costo è essenziale per massimizzare il valore dei modelli OpenAI nei tuoi progetti. Analizzando l'utilizzo dei token e i prezzi specifici del modello, puoi prendere decisioni informate per bilanciare prestazioni e convenienza. Tra le opzioni, GPT-4o-mini è un modello conveniente per la maggior parte delle attività, mentre GPT-4o offre un'alternativa potente ma economica per applicazioni ad alto volume poiché ha una lunghezza del contesto maggiore a 128k. L'API batch è un'altra alternativa utile per ridurre i costi dell'elaborazione in blocco per attività non urgenti.
Inoltre, se stai cercando un corso di intelligenza artificiale generativa online, esplora: Programma GenAI Pinnacle
Domande frequenti
Ris. Puoi ridurre i costi impostando un limite massimo sui token massimi, utilizzando l'API Batch per l'elaborazione in blocco
Ris. Imposta un budget mensile nelle impostazioni di fatturazione per interrompere le richieste una volta raggiunto il limite. Puoi anche impostare un avviso e-mail quando ti avvicini al budget e monitorare l'utilizzo tramite la dashboard di monitoraggio.
Ris. Sì, l'utilizzo di Playground è considerato uguale al normale utilizzo dell'API.
Ris. Gli esempi includono gpt-4-vision-preview, gpt-4-turbo, gpt-4o e gpt-4o-mini che elaborano e analizzano sia testo che immagini per varie attività.
Sono un appassionato di tecnologia, laureato al Vellore Institute of Technology. Sto lavorando come tirocinante in scienza dei dati in questo momento. Sono molto interessato al Deep Learning e all'intelligenza artificiale generativa.
Fonte: www.analyticsvidhya.com

