
introduzione
Dopo un anno di adozione di ChatGPT, il panorama dell’intelligenza artificiale accoglie l’attesissimo Gemini di Google, un formidabile concorrente. La serie Gemini comprende tre potenti modelli linguistici: Gemini Pro, Gemini Nano e Gemini Ultra di livello superiore, che ha dimostrato prestazioni eccezionali in vari benchmark, anche se deve ancora essere rilasciato sul mercato. Attualmente, i modelli Gemini Pro offrono prestazioni paragonabili a gpt-3.5-turbo, fornendo una soluzione accessibile ed economica per la comprensione del linguaggio naturale e le attività visive. Questi modelli possono essere applicati a diversi scenari del mondo reale, tra cui la narrazione video, la risposta visiva alle domande (QA), RAG (Retrieval-Augmented Generation) e altro ancora. In questo articolo esamineremo le funzionalità dei modelli Gemini Pro e ti guideremo nella creazione di un bot QA multimodale utilizzando Gemini e Gradio.

obiettivi formativi
- Esplora i modelli Gemini.
- Autentica VertexAI per accedere ai modelli Gemini.
- Esplora l’API Gemini e l’SDK GCP Python.
- Ulteriori informazioni su Gradio e i suoi componenti.
- Costruisci un bot QA multimodale funzionale utilizzando Gemini e Gradio.
Questo articolo è stato pubblicato come parte del Blogathon sulla scienza dei dati.
Prima di iniziare a costruire il nostro bot QA utilizzando Gemini e Gradio, comprendiamo le funzionalità di Gemini.
Cos’è Google Gemini?
Similmente al GPT, la famiglia di modelli Gemini utilizza decodificatori di trasformatori ottimizzati per l’addestramento su scala e l’inferenza sulle unità di elaborazione tensore di Google. Questi modelli vengono sottoposti a formazione congiunta su varie modalità di dati, inclusi testo, immagini, audio e video, per sviluppare modelli linguistici di grandi dimensioni (LLM) con funzionalità versatili e una comprensione completa di più modalità. Gemini comprende tre classi di modelli: Gemini Pro, Nano e Ultra, ciascuna ottimizzata per casi d’uso specifici.
- Gemelli Ultra: Il più performante di Google ha mostrato prestazioni all’avanguardia in attività come matematica, ragionamento, capacità multimodali, ecc. Secondo il rapporto tecnico di Google, Gemini Ultra ha ottenuto risultati migliori di GPT-4 su molti benchmark .
- Gemelli Pro: il modello Pro è ottimizzato per prestazioni, scalabilità e inferenza a bassa latenza. È un modello capace che rivaleggia con il gpt-3.5-turbo con capacità multimodali.
- Gemelli Nano: Nano ha due LLM più piccoli con parametri 1.8B e 3B. Viene addestrato distillando da modelli Gemini più grandi ottimizzati per l’esecuzione su dispositivi con memoria bassa e alta.
Puoi accedere ai modelli tramite GCP Vertex AI o Google AI Studio. Sebbene Vertex AI sia adatto per applicazioni di produzione, richiede un account GCP. Tuttavia, con Studio AIgli sviluppatori possono creare una chiave API per accedere ai modelli Gemini senza un account GCP. Esploreremo entrambi i metodi in questo articolo, ma implementeremo il metodo VertexAI. Puoi implementare quest’ultimo con alcune modifiche al codice.
Ora iniziamo con la creazione del bot QA utilizzando Gemini!
Accesso a Gemini utilizzando VertexAI
È possibile accedere ai modelli Gemini da VertexAI su GCP. Pertanto, per iniziare a costruire con questi modelli, dobbiamo configurare la CLI di Google Cloud ed eseguire l’autenticazione con Vertex AI. Primo, installare la CLI di GCP e inizializzarla con gcloud init.
Crea una credenziale di autenticazione per il tuo account con il comando gcloud auth application-accesso predefinito. Si aprirà un portale per accedere a Google e seguire le istruzioni. Una volta terminato, puoi lavorare con Google Cloud da un ambiente locale.
Ora crea un ambiente virtuale e installa la libreria Python. Questo è l’SDK Python per GCP per accedere ai modelli Gemini.
pip install --upgrade google-cloud-aiplatformOra che il nostro ambiente è pronto. Comprendiamo l’API Gemini.
Richiedi corpo all’API Gemini
Google ha rilasciato solo i modelli Pro e Pro Vision per uso pubblico. Gemini Pro è un LLM di solo testo adatto a casi d’uso di generazione di testo, come riepilogo, parafrasi, traduzione, ecc. Ha una dimensione di contesto di 32k. Tuttavia, il modello di visione può elaborare immagini e video. Ha una dimensione del contesto di 16k. Possiamo inviare 16 file di immagine o un video alla volta.
Di seguito è riportato il corpo della richiesta all’API Gemini:
{
"contents": (
{
"role": string,
"parts": (
{
// Union field data can be only one of the following:
"text": string,
"inlineData": {
"mimeType": string,
"data": string
},
"fileData": {
"mimeType": string,
"fileUri": string
},
// End of list of possible types for union field data.
"videoMetadata": {
"startOffset": {
"seconds": integer,
"nanos": integer
},
"endOffset": {
"seconds": integer,
"nanos": integer
}
}
}
)
}
),
"tools": (
{
"functionDeclarations": (
{
"name": string,
"description": string,
"parameters": {
object (OpenAPI Object Schema)
}
}
)
}
),
"safetySettings": (
{
"category": enum (HarmCategory),
"threshold": enum (HarmBlockThreshold)
}
),
"generationConfig": {
"temperature": number,
"topP": number,
"topK": number,
"candidateCount": integer,
"maxOutputTokens": integer,
"stopSequences": (
string
)
}
}Nello schema JSON sopra riportato, abbiamo ruoli (utente, sistema o funzione), testo, dati di file per immagini o video e configurazione di generazione per ulteriori parametri del modello e impostazioni di sicurezza per alterare la tolleranza di sensibilità del modello.
Questa è la risposta JSON dall’API.
{
"candidates": (
{
"content": {
"parts": (
{
"text": string
}
)
},
"finishReason": enum (FinishReason),
"safetyRatings": (
{
"category": enum (HarmCategory),
"probability": enum (HarmProbability),
"blocked": boolean
}
),
"citationMetadata": {
"citations": (
{
"startIndex": integer,
"endIndex": integer,
"uri": string,
"title": string,
"license": string,
"publicationDate": {
"year": integer,
"month": integer,
"day": integer
}
}
)
}
}
),
"usageMetadata": {
"promptTokenCount": integer,
"candidatesTokenCount": integer,
"totalTokenCount": integer
}
}Come risposta, otteniamo un JSON con risposte, citazioni, valutazioni di sicurezza e dati di utilizzo. Quindi, questi sono gli schemi JSON di richieste e risposte all’API Gemini. Per ulteriori informazioni fare riferimento a questo ufficiale documentazione per i Gemelli.
Puoi comunicare direttamente con l’API con JSON. A volte è meglio comunicare direttamente con gli endpoint API piuttosto che dipendere dagli SDK, poiché questi ultimi spesso subiscono modifiche importanti.
Per semplicità, utilizzeremo l’SDK Python che abbiamo installato in precedenza per comunicare con i modelli.
from vertexai.preview.generative_models import GenerativeModel, Image, Part, GenerationConfig
model = GenerativeModel("gemini-pro-vision", generation_config= GenerationConfig())
response = model.generate_content(
(
"Explain this image step-by-step, using bullet marks in detail",
Part.from_image(Image.load_from_file("whisper_arch.png"))
),
)
print(response)Ciò genererà un oggetto Generation.
candidates {
content {
role: "model"
parts {
text: " * response
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 271
candidates_token_count: 125
total_token_count: 396
}Possiamo recuperare i testi con il seguente codice.
print(response.candidates(0).content.parts(0).text)Produzione
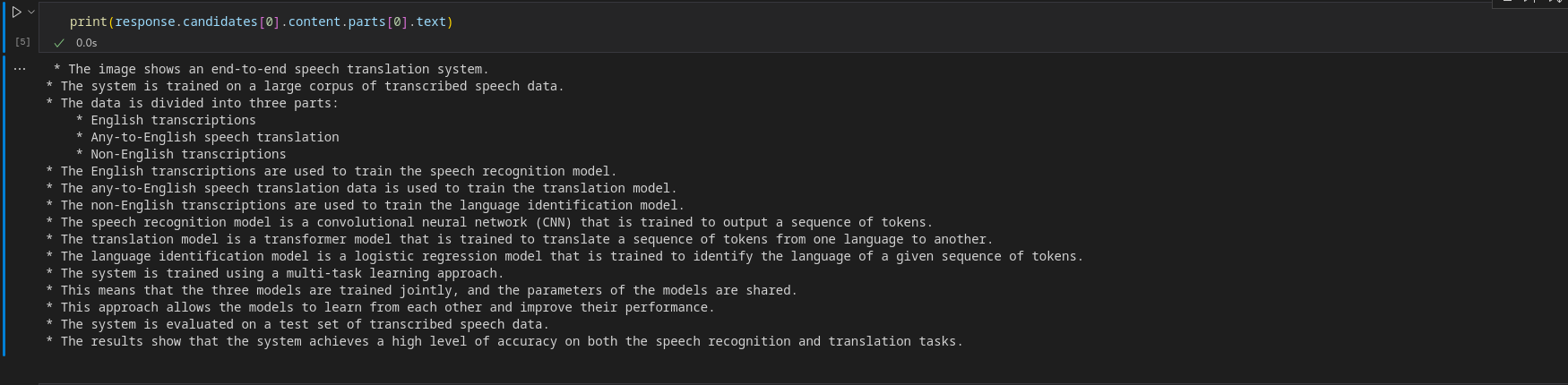
Per ricevere un oggetto in streaming, imposta lo streaming su True.
response = model.generate_content(
(
"Explain this image step-by-step, using bullet marks in detail?",
Part.from_image(Image.load_from_file("whisper_arch.png"))
), stream=True
)Per recuperare blocchi, scorrere l’oggetto StreamingGeneration.
for resp in response:
print(resp.candidates(0).content.parts(0).text)Produzione
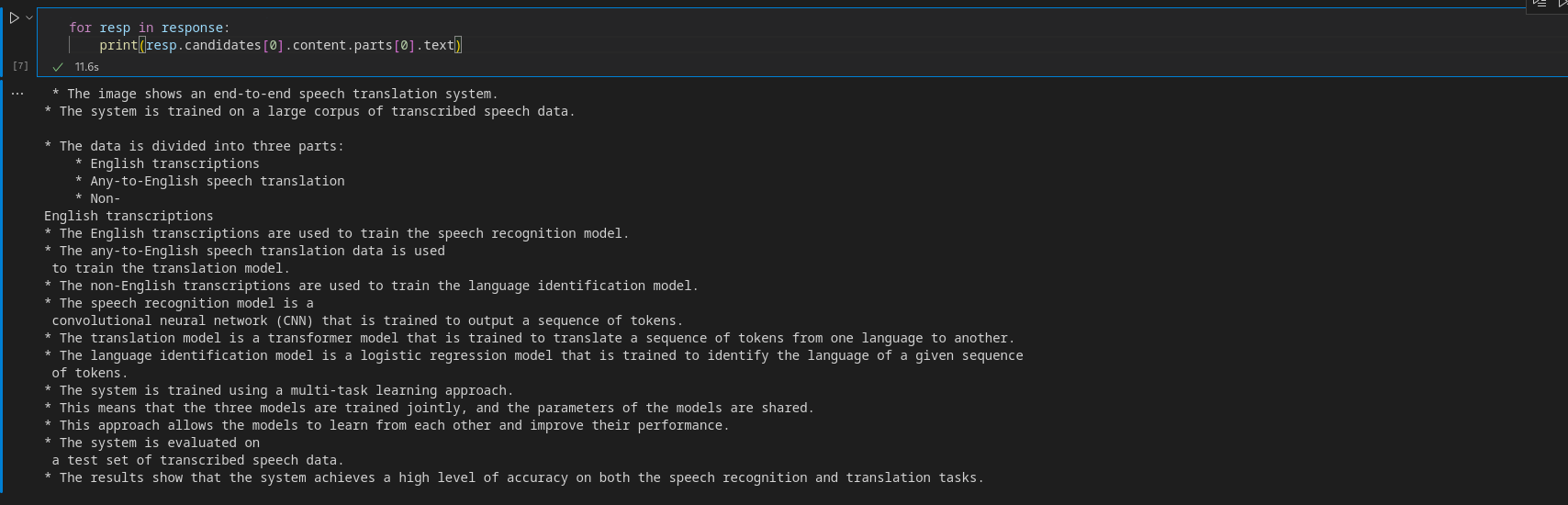
Prima di creare l’app, diamo una breve introduzione a Gradio.
Accesso a Gemini utilizzando AI Studio
Google AI Studio ti consente di accedere ai modelli Gemini tramite un’API. Quindi, vai al pagina ufficiale e creare una chiave API. Ora installa la seguente libreria.
pip install google-generativeaiConfigura la chiave API impostandola come variabile di ambiente:
import google.generativeai as genai
api_key = "api-key"
genai.configure(api_key=api_key)Ora, deduzione dai modelli.
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("What is the meaning of life?",)La struttura della risposta è simile al metodo precedente.
print(response.candidates(0).content.parts(0).text)Produzione

Allo stesso modo, puoi anche dedurre dal modello di visione.
import PIL.Image
img = "whisper_arch.png"
img = PIL.Image.open(img)
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(("Explain the architecture step by step in detail", img),
stream=True)
response.resolve()
for resp in response:
print(resp.text)
Produzione
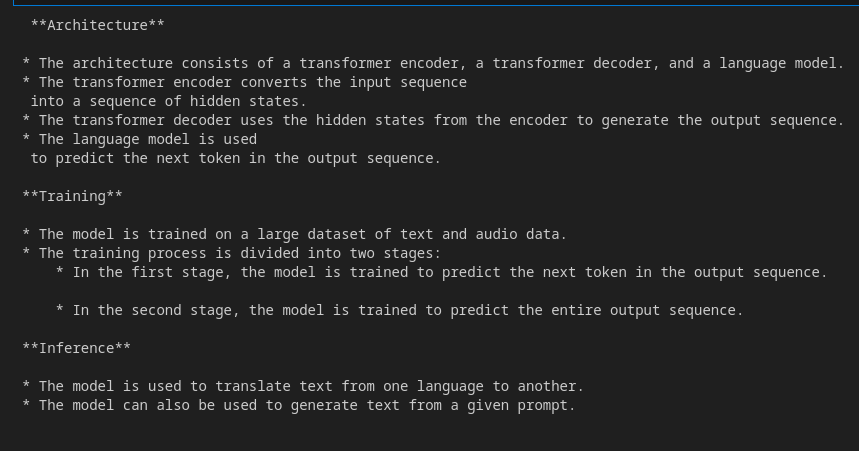
Ai Studio è un ottimo posto per accedere a questi modelli se non desideri utilizzare GCP. Poiché utilizzeremo VertexAI, puoi utilizzarlo invece con alcune modifiche.
Iniziamo a creare un bot QA utilizzando Gradio
Gradio è uno strumento open source per creare app Web in Python per condividere modelli di machine learning. Dispone di componenti modulari che possono essere assemblati per creare un’app Web senza coinvolgere codici JavaScript o HTML. Gradio dispone dell’API Blocks che ti consente di creare interfacce utente Web con maggiore personalizzazione. Il backend di Gradio è realizzato con Fastapi e il front-end è realizzato con Svelte. La libreria Python astrae le complessità sottostanti e ci consente di creare rapidamente un’interfaccia utente web. In questo articolo utilizzeremo Gradio per creare l’interfaccia utente del nostro bot QA.
Fare riferimento a questo articolo per una guida dettagliata sulla creazione di un chatbot Gradio: Costruiamo il tuo chatbot GPT con Gradio
Front-End con Gradio
Utilizzeremo l’API Blocks di Gradio e altri componenti per creare il nostro front-end. Quindi, installa Gradio con pip se non l’hai già fatto e importa la libreria.
Per il front-end, abbiamo bisogno di un’interfaccia utente di chat per domande e risposte, una casella di testo per inviare domande agli utenti, una casella di file per caricare immagini/video e componenti come uno slider e un pulsante di opzione per personalizzare i parametri del modello, come temperatura, top-k , in alto, ecc.
Ecco come possiamo farlo con Gradio.
# Importing necessary libraries or modules
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=3):
gr.Markdown("Chatbot")
# Adding a Chatbot with a height of 650 and a copy button
chatbot = gr.Chatbot(show_copy_button=True, height=650)
with gr.Row():
# Creating a column with a scale of 6
with gr.Column(scale=6):
# Adding a Textbox with a placeholder "write prompt"
prompt = gr.Textbox(placeholder="write your queries")
# Creating a column with a scale of 2
with gr.Column(scale=2):
# Adding a File
file = gr.File()
# Creating a column with a scale of 2
with gr.Column(scale=2):
# Adding a Button
button = gr.Button()
# Creating another column with a scale of 1
with gr.Column(scale=1):
with gr.Row():
gr.Markdown("Model Parameters")
# Adding a Button with the value "Reset"
reset_params = gr.Button(value="Reset")
gr.Markdown("General")
# Adding a Dropdown for model selection
model = gr.Dropdown(value="gemini-pro", choices=("gemini-pro", "gemini-pro-vision"),
label="Model", info="Choose a model", interactive=True)
# Adding a Radio for streaming option
stream = gr.Radio(label="Streaming", choices=(True, False), value=True,
interactive=True, info="Stream while responses are generated")
# Adding a Slider for temperature
temparature = gr.Slider(value=0.6, maximum=1.0, label="Temperature", interactive=True)
# Adding a Textbox for stop sequence
stop_sequence = gr.Textbox(label="Stop Sequence",
info="Stops generation when the string is encountered.")
# Adding a Markdown with the text "Advanced"
gr.Markdown(value="Advanced")
# Adding a Slider for top-k parameter
top_p = gr.Slider(
value=0.4,
label="Top-k",
interactive=True,
info="""Top-k changes how the model selects tokens for output:
lower = less random, higher = more diverse. Defaults to 40."""
)
# Adding a Slider for top-p parameter
top_k = gr.Slider(
value=8,
label="Top-p",
interactive=True,
info="""Top-p changes how the model selects tokens for output.
Tokens are selected from most probable to least until
the sum of their probabilities equals the top-p value"""
)
demo.queue()
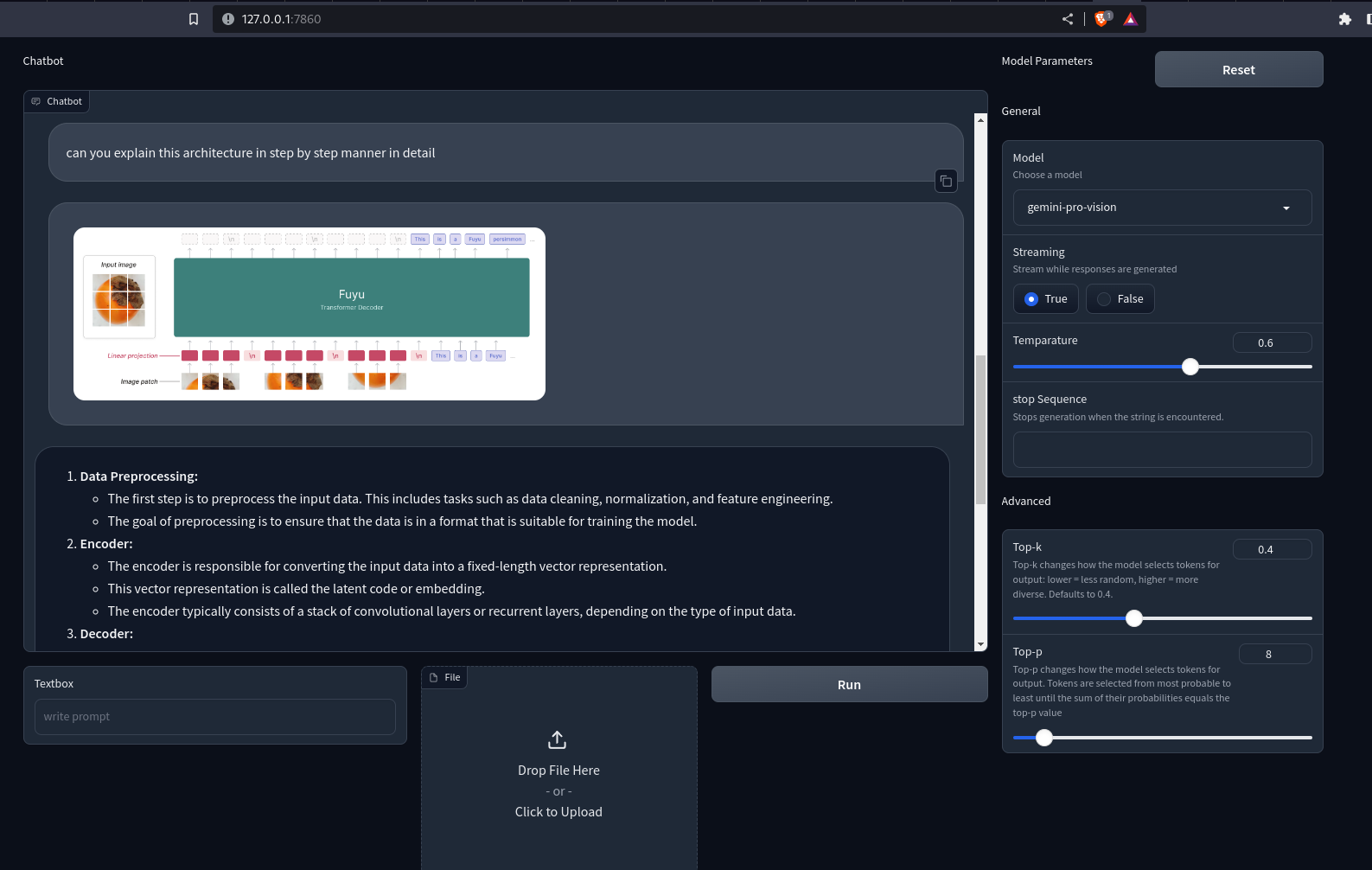
demo.launch()Abbiamo utilizzato l’API Row and Column di Gradio per personalizzare l’interfaccia web. Ora esegui il file Python con il file creazione di app.py. Questo aprirà un server Uvicorn su localhost:7860. Ecco come apparirà la nostra app.
Produzione
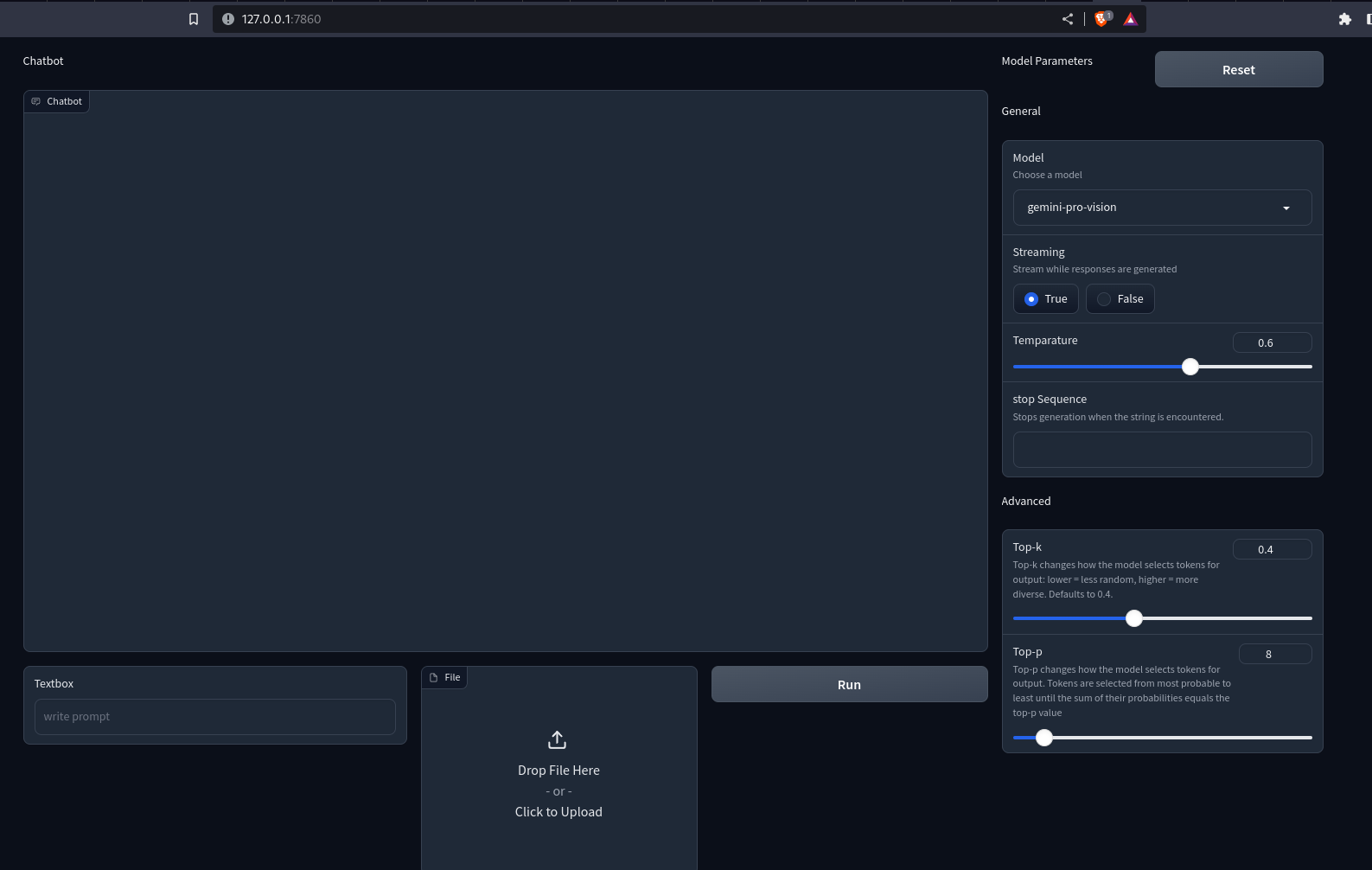
Noti che non succede nulla quando premi i pulsanti. Per renderlo interattivo, dobbiamo definire i gestori di eventi. Qui abbiamo bisogno di gestori per i pulsanti Esegui e Ripristina. Ecco come possiamo farlo.
button.click(fn=add_content, inputs=(prompt, chatbot, file), outputs=(chatbot))\
.success(fn = gemini_generator.run, inputs=(chatbot, prompt, file, model, stream,
temparature, stop_sequence,
top_k, top_p), outputs=(prompt,file,chatbot)
)
reset_params.click(fn=reset, outputs=(model, stream, temparature,
stop_sequence, top_p, top_k))Quando si preme il pulsante di clic, la funzione nel parametro fn viene richiamata con tutti gli input. I valori restituiti dalla funzione vengono inviati ai componenti negli output. L’evento di successo è il modo in cui possiamo concatenare più eventi. Ma noti che non abbiamo definito le funzioni. Dobbiamo definire queste funzioni per renderle interattive.
Costruire il back-end
La prima funzione che definiremo qui è add_content. Ciò visualizzerà i messaggi utente e API sull’interfaccia della chat. Ecco come possiamo farlo.
def add_content(text:str, chatbot:Chatbot, file: str)->Chatbot:
# Check if both file and text are provided
if file and text:
# Concatenate the existing chatbot content with new text and file content
chatbot = chatbot + ((text, None), ((file,), None))
# Check if only text is provided
elif text and not file:
# Concatenate the existing chatbot content with a new text
chatbot += ((text, None))
# Check if only the file is provided
elif file and not text:
# Concatenate the existing chatbot content with a new file content
chatbot += (((file,), None))
else:
# Raise an error if neither text nor file is provided
raise gr.Error("Enter a valid text or a file")
# Return the updated chatbot content
return chatbot
La funzione riceve il testo, il chatbot e il percorso del file. Il chatbot è un elenco di elenchi di tuple. Il primo membro della tupla è la query dell’utente e il secondo è la risposta del chatbot. Per inviare file multimediali, sostituiamo la stringa con un’altra tupla. Il primo membro di questa tupla è il percorso del file o l’URL e il secondo è il testo alternativo. Questa è la convenzione per la visualizzazione dei contenuti multimediali nell’interfaccia utente della chat in Gradio.
Ora creeremo una classe con metodi per gestire le risposte dell’API Gemini.
from typing import Union, ByteString
from gradio import Part, GenerationConfig, GenerativeModel
class GeminiGenerator:
"""Multi-modal generator class for Gemini models"""
def _convert_part(self, part: Union(str, ByteString, Part)) -> Part:
# Convert different types of parts (str, ByteString, Part) to Part objects
if isinstance(part, str):
return Part.from_text(part)
elif isinstance(part, ByteString):
return Part.from_data(part.data, part.mime_type)
elif isinstance(part, Part):
return part
else:
msg = f"Unsupported type {type(part)} for part {part}"
raise ValueError(msg)
def _check_file(self, file):
# Check if file is provided
if file:
return True
return False
def run(self, history, text: str, file: str, model: str, stream: bool, temperature: float,
stop_sequence: str, top_k: int, top_p: float):
# Configure generation parameters
generation_config = GenerationConfig(
temperature=temperature,
top_k=top_k,
top_p=top_p,
stop_sequences=stop_sequence
)
self.client = GenerativeModel(model_name=model, generation_config=generation_config,)
# Generate content based on input parameters
if text and self._check_file(file):
# Convert text and file to Part objects and generate content
contents = (self._convert_part(part) for part in (text, file))
response = self.client.generate_content(contents=contents, stream=stream)
elif text:
# Convert text to a Part object and generate content
content = self._convert_part(text))
response = self.client.generate_content(contents=content, stream=stream)
elif self._check_file(file):
# Convert file to a Part object and generate content
content = self._convert_part(file)
response = self.client.generate_content(contents=content, stream=stream)
# Check if streaming is True
if stream:
# Update history and yield responses for streaming
history(-1)(-1) = ""
for resp in response:
history(-1)(-1) += resp.candidates(0).content.parts(0).text
yield "", gr.File(value=None), history
else:
# Append the generated content to the chatbot history
history.append((None, response.candidates(0).content.parts(0).text))
return " ", gr.File(value=None), history
Nello snippet di codice sopra, abbiamo definito una classe GeminiGenerator. Il run() avvia un client con un nome di modello e una configurazione di generazione. Quindi, recuperiamo le risposte dai modelli Gemini in base ai dati forniti. _convert_part() converte i dati in un oggetto Part. generate_content() richiede che i dati siano una stringa, un’immagine o una parte. Qui stiamo convertendo ogni dato in Parte per mantenere l’omogeneità.
Ora avvia un oggetto con la classe.
gemini-generator = GeminiGenerator()Dobbiamo definire la funzione reset_parameter. Ciò ripristina i parametri ai valori predefiniti.
def reset() -> List(Component):
return (
gr.Dropdown(value = "gemini-pro",choices=("gemini-pro", "gemini-pro-vision"),
label="Model",
info="Choose a model", interactive=True),
gr.Radio(label="Streaming", choices=(True, False), value=True, interactive=True,
info="Stream while responses are generated"),
gr.Slider(value= 0.6,maximum=1.0, label="Temparature", interactive=True),
gr.Textbox(label="Token limit", value=2048),
gr.Textbox(label="stop Sequence",
info="Stops generation when the string is encountered."),
gr.Slider(
value=40,
label="Top-k",
interactive=True,
info="""Top-k changes how the model selects tokens for output: lower = less
random, higher = more diverse. Defaults to 40."""
),
gr.Slider(
value=8,
label="Top-p",
interactive=True,
info="""Top-p changes how the model selects tokens for output.
Tokens are selected from most probable to least until
the sum of their probabilities equals the top-p value"""
)
)Qui stiamo semplicemente restituendo le impostazioni predefinite. Ciò reimposta i parametri.
Ora ricarica l’app su localhost. Ora puoi inviare query di testo e immagini/video ai modelli Gemini. Le risposte verranno visualizzate sul chatbot. Se il flusso è impostato su True, i blocchi di risposta verranno sottoposti a rendering progressivamente un blocco alla volta.
Produzione
Ecco il repository GitHub per l’app Gradio: sunilkumardash9/multimodal-chatbot
Conclusione
Spero che ti sia piaciuto creare un bot QA utilizzando Gemini e Gradio!
Il modello multimodale di Google può essere utile per diversi casi d’uso. Un chatbot personalizzato basato su di esso è uno di questi casi d’uso. Possiamo estendere l’applicazione per includere diverse funzionalità, come l’aggiunta di altri modelli come GPT-4 e altri modelli open source. Quindi, invece di passare da un sito Web all’altro, puoi avere il tuo aggregatore LLM. Allo stesso modo, possiamo estendere l’applicazione per supportare RAG multimodale, narrazione video, estrazione di entità visive, ecc.
Punti chiave
- Gemini è una famiglia di modelli con tre classi di modelli. Ultra, Pro e Nano.
- I modelli sono stati addestrati congiuntamente su più modalità per ottenere una comprensione multimodale all’avanguardia.
- Sebbene l’Ultra sia il modello più capace, Google ha reso pubblici solo i modelli Pro.
- È possibile accedere ai modelli Gemini Pro e Vision da Google Cloud VertexAI o Google AI Studio.
- Gradio è uno strumento Python open source per la creazione di demo Web rapide di app ML.
- Abbiamo utilizzato l’API Blocks di Gradio e altre funzionalità per creare un bot QA interattivo utilizzando i modelli Gemini.
Domande frequenti
R. Sebbene Google affermi che Gemini Ultra sia un modello migliore, non è stato ancora reso pubblico. I modelli Gemini disponibili al pubblico sono più simili al gpt-3.5-turbo in termini di prestazioni grezze rispetto al GPT-4.
R. È possibile accedere gratuitamente ai modelli Gemini Pro e Gemini Pro Vision su Google AI Studio per gli sviluppatori con 60 richieste al minuto.
A. Un chatbot in grado di elaborare e comprendere diverse modalità di dati, come testi, immagini, audio, video, ecc.
R. È uno strumento Python open source che ti consente di condividere rapidamente modelli di machine learning con chiunque.
R. Gradio Interface è una classe potente e di alto livello che consente la creazione rapida di un’interfaccia utente grafica (GUI) basata sul Web con solo poche righe di codice.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell’autore.
Imparentato
Fonte: www.analyticsvidhya.com

