
introduzione
Domande e risposte su dati personalizzati sono uno dei casi d’uso più ricercati dei modelli linguistici di grandi dimensioni. Le capacità di conversazione simili a quelle umane dei LLM combinate con metodi di recupero vettoriale rendono molto più semplice estrarre risposte da documenti di grandi dimensioni. Con qualche variazione, possiamo creare sistemi per interagire con qualsiasi dato (strutturato, non strutturato e semi-strutturato) archiviato come incorporamento in un database vettoriale. Questo metodo per aumentare gli LLM con i dati recuperati in base ai punteggi di somiglianza tra l’incorporamento delle query e gli incorporamenti dei documenti è chiamato RAG o generazione aumentata di recupero. Questo metodo può semplificare molte cose, come leggere documenti su arXiv.
Se ti piacciono l’intelligenza artificiale e l’informatica, devi aver sentito “arXiv” almeno una volta. arXiv è un archivio ad accesso aperto per prestamp e postprint elettronici. Ospita articoli verificati ma non sottoposti a revisione paritaria su vari argomenti, come machine learning, intelligenza artificiale, matematica, fisica, statistica, elettronica, ecc. ArXiv ha svolto un ruolo fondamentale nel promuovere la ricerca aperta nell’intelligenza artificiale e nelle scienze dure. Ma leggere i documenti di ricerca è spesso arduo e richiede molto tempo. Quindi, possiamo migliorare un po’ le cose utilizzando un chatbot RAG che ci consenta di estrarre contenuti rilevanti dal documento e di ottenere risposte?
In questo articolo creeremo un chatbot RAG per i documenti aXiv utilizzando uno strumento open source chiamato Haystack.

obiettivi formativi
- Capisci cos’è Haystack? E si tratta di componenti per la creazione di applicazioni basate su LLM.
- Costruisci un componente per recuperare i documenti Arxiv utilizzando la libreria “arxiv”.
- Scopri come creare pipeline di indicizzazione e query con i nodi Haystack.
- Impara a creare un’interfaccia di chat con Gradio, coordinare le pipeline per recuperare documenti da un archivio vettoriale e generare risposte da un LLM.
Questo articolo è stato pubblicato come parte del Blogathon sulla scienza dei dati.
Cos’è Haystack?
Haystack è un framework PNL all-in-one open source per creare applicazioni scalabili basate su LLM. Haystack fornisce un approccio altamente modulare e personalizzabile per creare applicazioni NLP pronte per la produzione come ricerca semantica, risposta alle domande, RAG, ecc. È costruito attorno al concetto di pipeline e nodi; le pipeline forniscono un approccio molto snello all’organizzazione dei nodi per creare applicazioni NLP efficienti.
- Nodi: I nodi sono gli elementi costitutivi fondamentali di Haystack. Un nodo realizza una singola cosa, come la preelaborazione di documenti, il recupero da archivi di vettori, la generazione di risposte da LLM, ecc.
- Tubatura: La pipeline aiuta a connettere un nodo a un altro per costruire una catena di nodi. Ciò semplifica la creazione di applicazioni con Haystack.
Haystack offre anche il supporto immediato per i principali negozi di vettori, come Weaviate, Milvus, Elastic Search, Qdrant, ecc. Per ulteriori informazioni, fare riferimento al repository pubblico di Haystack: https://github.com/deepset-ai/haystack.
Quindi, in questo articolo, utilizzeremo Haystack per creare un chatbot di domande e risposte per i documenti Arxiv con un’interfaccia Gradio.
Costruito
Gradio è una soluzione open source di Huggingface per configurare e condividere una demo di qualsiasi applicazione di machine learning. È alimentato da Fastapi sul backend e snello per i componenti front-end. Ci consente di scrivere app Web personalizzabili con Python. Ideale per creare e condividere app demo per modelli di machine learning o prove di concetti. Per ulteriori informazioni, visita il sito ufficiale di Gradio GitHub. Per saperne di più sulla creazione di applicazioni con Gradio, fare riferimento a questo articolo, “Costruiamo Chat GPT con Gradio.”
Costruire il Chatbot
Prima di creare l’applicazione, tracciamo brevemente il flusso di lavoro. Si inizia con la comunicazione da parte dell’utente dell’ID del documento Arxiv e si termina con la ricezione delle risposte alle domande. Quindi, ecco un semplice flusso di lavoro del nostro chatbot Arxiv.
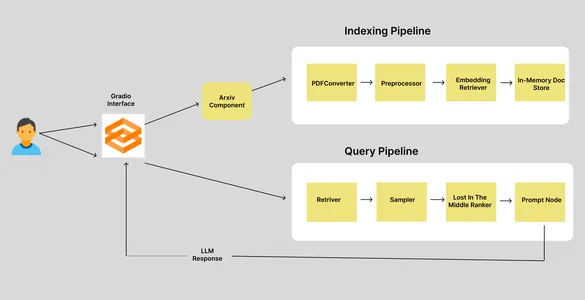
Abbiamo due pipeline: la pipeline di indicizzazione e la pipeline di query. Quando un utente inserisce un ID articolo Arxiv, va al componente Arxiv, che recupera e scarica il documento corrispondente in una directory specificata e attiva la pipeline di indicizzazione. La pipeline di indicizzazione è composta da quattro nodi, ciascuno responsabile dell’esecuzione di una singola attività. Quindi, vediamo cosa fanno questi nodi.
Pipeline di indicizzazione
In una pipeline Haystack, l’output del nodo precedente verrà utilizzato come input del nodo corrente. In una pipeline di indicizzazione, l’input iniziale è il percorso del documento.
- PDFToTextConverter: la libreria Arxiv ci consente di scaricare documenti in formato PDF. Ma abbiamo bisogno dei dati nel testo. Quindi, questo nodo estrae i testi dal PDF.
- Preprocessore: i dati estratti devono essere puliti ed elaborati prima di archiviarli nel database vettoriale. Questo nodo è responsabile della pulizia e della suddivisione dei testi.
- EmbeddingRetriver: questo nodo definisce l’archivio vettoriale in cui i dati devono essere archiviati e il modello di incorporamento utilizzato per ottenere gli incorporamenti.
- InMemoryDocumentStore: questo è l’archivio vettoriale in cui vengono archiviati gli incorporamenti. In questo caso, abbiamo utilizzato l’archivio documenti in memoria predefinito di Haystacks. Ma puoi anche utilizzare altri negozi di vettori, come Qdrant, Weaviate, Elastic Search, Milvus, ecc.
Pipeline di query
La pipeline di query viene attivata quando l’utente invia query. La pipeline di query recupera i documenti “k” più vicini agli incorporamenti di query dall’archivio vettoriale e genera una risposta LLM. Anche qui abbiamo quattro nodi.
- Retriever: recupera il documento “k” più vicino agli incorporamenti della query dall’archivio vettoriale.
- Campionatore: filtra i documenti in base alla probabilità cumulativa dei punteggi di somiglianza tra la query e i documenti utilizzando il campionamento p superiore.
- LostInTheMiddleRanker: questo algoritmo riordina i documenti estratti. Posiziona i documenti più rilevanti all’inizio o alla fine del contesto.
- PromptNode: PromptNode è responsabile della generazione di risposte alle domande dal contesto fornito al LLM.
Quindi, si trattava del flusso di lavoro del nostro chatbot Arxiv. Ora tuffiamoci nella parte di codifica.
Configura inv
Prima di installare qualsiasi dipendenza, crea un ambiente virtuale. Puoi utilizzare Venv e Poetry per creare un ambiente virtuale.
python -m venv my-env-name
source bin/activateOra installa le seguenti dipendenze di sviluppo. Per scaricare i documenti Arxiv è necessario che sia installata la libreria Arxiv.
farm-haystack
arxiv
gradio
Ora importeremo le librerie.
import arxiv
import os
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes import (
EmbeddingRetriever,
PreProcessor,
PDFToTextConverter,
PromptNode,
PromptTemplate,
TopPSampler
)
from haystack.nodes.ranker import LostInTheMiddleRanker
from haystack.pipelines import Pipeline
import gradio as grComponente Arxiv di costruzione
Questo componente sarà responsabile del download e dell’archiviazione dei file PDF Arxiv. COSÌ. ecco come definiamo il componente.
class ArxivComponent:
"""
This component is responsible for retrieving arXiv articles based on an arXiv ID.
"""
def run(self, arxiv_id: str = None):
"""
Retrieves and stores an arXiv article for the given arXiv ID.
Args:
arxiv_id (str): ArXiv ID of the article to be retrieved.
"""
# Set the directory path where arXiv articles will be stored
dir: str = DIR
# Create an instance of the arXiv client
arxiv_client = arxiv.Client()
# Check if an arXiv ID is provided; if not, raise an error
if arxiv_id is None:
raise ValueError("Please provide the arXiv ID of the article to be retrieved.")
# Search for the arXiv article using the provided arXiv ID
search = arxiv.Search(id_list=(arxiv_id))
response = arxiv_client.results(search)
paper = next(response) # Get the first result
title = paper.title # Extract the title of the article
# Check if the specified directory exists
if os.path.isdir(dir):
# Check if the PDF file for the article already exists
if os.path.isfile(dir + "/" + title + ".pdf"):
return {"file_path": (dir + "/" + title + ".pdf")}
else:
# If the directory does not exist, create it
os.mkdir(dir)
# Attempt to download the PDF for the arXiv article
try:
paper.download_pdf(dirpath=dir, filename=title + ".pdf")
return {"file_path": (dir + "/" + title + ".pdf")}
except:
# If there's an error during the download, raise a ConnectionError
raise ConnectionError(message=f"Error occurred while downloading PDF for \
arXiv article with ID: {arxiv_id}")
Il componente precedente inizializza un client Arxiv, quindi recupera l’articolo Arxiv associato all’ID e controlla se è già stato scaricato; restituisce il percorso del PDF o lo scarica nella directory.
Costruire la pipeline di indicizzazione
Ora definiremo la pipeline di indicizzazione per elaborare e archiviare i documenti nel nostro database vettoriale.
document_store = InMemoryDocumentStore()
embedding_retriever = EmbeddingRetriever(
document_store=document_store,
embedding_model="sentence-transformers/All-MiniLM-L6-V2",
model_format="sentence_transformers",
top_k=10
)
def indexing_pipeline(file_path: str = None):
pdf_converter = PDFToTextConverter()
preprocessor = PreProcessor(split_by="word", split_length=250, split_overlap=30)
indexing_pipeline = Pipeline()
indexing_pipeline.add_node(
component=pdf_converter,
name="PDFConverter",
inputs=("File")
)
indexing_pipeline.add_node(
component=preprocessor,
name="PreProcessor",
inputs=("PDFConverter")
)
indexing_pipeline.add_node(
component=embedding_retriever,
name="EmbeddingRetriever",
inputs=("PreProcessor")
)
indexing_pipeline.add_node(
component=document_store,
name="InMemoryDocumentStore",
inputs=("EmbeddingRetriever")
)
indexing_pipeline.run(file_paths=file_path)Per prima cosa definiamo il nostro archivio documenti in memoria e poi l’embedding-retriever. Nell’embedding-retriever specifichiamo l’archivio documenti, i modelli di incorporamento e il numero di documenti da recuperare.
Abbiamo anche definito i quattro nodi di cui abbiamo parlato in precedenza. pdf_converter converte PDF in testo, il preprocessore pulisce e crea blocchi di testo, embedding_retriever effettua incorporamenti di documenti e InMemoryDocumentStore memorizza incorporamenti di vettori. Il metodo run con il percorso del file attiva la pipeline e ciascun nodo viene eseguito nell’ordine in cui è stato definito. Puoi anche notare come ciascun nodo utilizza gli output dei nodi precedenti come input.
Costruire la pipeline di query
Anche la pipeline delle query è composta da quattro nodi. Questo è responsabile dell’incorporamento dal testo interrogato, della ricerca di documenti simili da archivi di vettori e infine della generazione di risposte da LLM.
def query_pipeline(query: str = None):
if not query:
raise gr.Error("Please provide a query.")
prompt_text = """
Synthesize a comprehensive answer from the provided paragraphs of an Arxiv
article and the given question.\n
Focus on the question and avoid unnecessary information in your answer.\n
\n\n Paragraphs: {join(documents)} \n\n Question: {query} \n\n Answer:
"""
prompt_node = PromptNode(
"gpt-3.5-turbo",
default_prompt_template=PromptTemplate(prompt_text),
api_key="api-key",
max_length=768,
model_kwargs={"stream": False},
)
query_pipeline = Pipeline()
query_pipeline.add_node(
component = embedding_retriever,
name = "Retriever",
inputs=("Query")
)
query_pipeline.add_node(
component=TopPSampler(
top_p=0.90),
name="Sampler",
inputs=("Retriever")
)
query_pipeline.add_node(
component=LostInTheMiddleRanker(1024),
name="LostInTheMiddleRanker",
inputs=("Sampler")
)
query_pipeline.add_node(
component=prompt_node,
name="Prompt",
inputs=("LostInTheMiddleRanker")
)
pipeline_obj = query_pipeline.run(query = query)
return pipeline_obj("results")embedding_retriever recupera “k” documenti simili dall’archivio vettoriale. Il campionatore è responsabile del campionamento dei documenti. LostInTheMiddleRanker classifica i documenti all’inizio o alla fine del contesto in base alla loro pertinenza. Infine, il prompt_node, dove LLM è “gpt-3.5-turbo”. Abbiamo anche aggiunto un modello di prompt per aggiungere più contesto alla conversazione. Il metodo run restituisce un oggetto pipeline, un dizionario.
Questo era il nostro backend. Ora progettiamo l’interfaccia.
Interfaccia Gradio
Questo ha una classe Blocks per creare un’interfaccia web personalizzabile. Quindi, per questo progetto, abbiamo bisogno di una casella di testo che accetti l’ID Arxiv come input dell’utente, un’interfaccia di chat e una casella di testo che accetti le query dell’utente. Ecco come possiamo farlo.
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=60):
text_box = gr.Textbox(placeholder="Input Arxiv ID",
interactive=True).style(container=False)
with gr.Column(scale=40):
submit_id_btn = gr.Button(value="Submit")
with gr.Row():
chatbot = gr.Chatbot(value=()).style(height=600)
with gr.Row():
with gr.Column(scale=70):
query = gr.Textbox(placeholder = "Enter query string",
interactive=True).style(container=False)Esegui il comando gradio app.py nella riga di comando e visita l’URL localhost visualizzato.
Ora dobbiamo definire gli eventi trigger.
submit_id_btn.click(
fn = embed_arxiv,
inputs=(text_box),
outputs=(text_box),
)
query.submit(
fn=add_text,
inputs=(chatbot, query),
outputs=(chatbot, ),
queue=False
).success(
fn=get_response,
inputs = (chatbot, query),
outputs = (chatbot,)
)
demo.queue()
demo.launch()Per far funzionare gli eventi, dobbiamo definire le funzioni menzionate in ciascun evento. Fare clic su send_iid_btn, inviare l’input dalla casella di testo come parametro alla funzione embed_arxiv. Questa funzione coordinerà il recupero e l’archiviazione del PDF Arxiv nell’archivio vettoriale.
arxiv_obj = ArxivComponent()
def embed_arxiv(arxiv_id: str):
"""
Args:
arxiv_id: Arxiv ID of the article to be retrieved.
"""
global FILE_PATH
dir: str = DIR
file_path: str = None
if not arxiv_id:
raise gr.Error("Provide an Arxiv ID")
file_path_dict = arxiv_obj.run(arxiv_id)
file_path = file_path_dict("file_path")
FILE_PATH = file_path
indexing_pipeline(file_path=file_path)
return"Successfully embedded the file"Abbiamo definito un oggetto ArxivComponent e la funzione embed_arxiv. Esegue il metodo “esegui” e utilizza il percorso del file restituito come parametro per la pipeline di indicizzazione.
Ora passiamo all’evento di invio con la funzione add_text come parametro. Questo è responsabile del rendering della chat nell’interfaccia della chat.
def add_text(history, text: str):
if not text:
raise gr.Error('enter text')
history = history + ((text,''))
return historyOra definiamo la funzione get_response, che recupera e trasmette in streaming le risposte LLM nell’interfaccia della chat.
def get_response(history, query: str):
if not query:
gr.Error("Please provide a query.")
response = query_pipeline(query=query)
for text in response(0):
history(-1)(1) += text
yield history, ""Questa funzione prende la stringa di query e la passa alla pipeline di query per ottenere una risposta. Infine, iteriamo sulla stringa di risposta e la restituiamo al chatbot.
Mettere tutto insieme.
# Create an instance of the ArxivComponent class
arxiv_obj = ArxivComponent()
def embed_arxiv(arxiv_id: str):
"""
Retrieves and embeds an arXiv article for the given arXiv ID.
Args:
arxiv_id (str): ArXiv ID of the article to be retrieved.
"""
# Access the global FILE_PATH variable
global FILE_PATH
# Set the directory where arXiv articles are stored
dir: str = DIR
# Initialize file_path to None
file_path: str = None
# Check if arXiv ID is provided
if not arxiv_id:
raise gr.Error("Provide an Arxiv ID")
# Call the ArxivComponent's run method to retrieve and store the arXiv article
file_path_dict = arxiv_obj.run(arxiv_id)
# Extract the file path from the dictionary
file_path = file_path_dict("file_path")
# Update the global FILE_PATH variable
FILE_PATH = file_path
# Call the indexing_pipeline function to process the downloaded article
indexing_pipeline(file_path=file_path)
return "Successfully embedded the file"
def get_response(history, query: str):
if not query:
gr.Error("Please provide a query.")
# Call the query_pipeline function to process the user's query
response = query_pipeline(query=query)
# Append the response to the chat history
for text in response(0):
history(-1)(1) += text
yield history
def add_text(history, text: str):
if not text:
raise gr.Error('Enter text')
# Add user-provided text to the chat history
history = history + ((text, ''))
return history
# Create a Gradio interface using Blocks
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=60):
# Text input for Arxiv ID
text_box = gr.Textbox(placeholder="Input Arxiv ID",
interactive=True).style(container=False)
with gr.Column(scale=40):
# Button to submit Arxiv ID
submit_id_btn = gr.Button(value="Submit")
with gr.Row():
# Chatbot interface
chatbot = gr.Chatbot(value=()).style(height=600)
with gr.Row():
with gr.Column(scale=70):
# Text input for user queries
query = gr.Textbox(placeholder="Enter query string",
interactive=True).style(container=False)
# Define the actions for button click and query submission
submit_id_btn.click(
fn=embed_arxiv,
inputs=(text_box),
outputs=(text_box),
)
query.submit(
fn=add_text,
inputs=(chatbot, query),
outputs=(chatbot, ),
queue=False
).success(
fn=get_response,
inputs=(chatbot, query),
outputs=(chatbot,)
)
# Queue and launch the interface
demo.queue()
demo.launch()
Esegui l’applicazione utilizzando il comando gradio app.py e visita l’URL per interagire con Arxic Chatbot.
Ecco come apparirà.
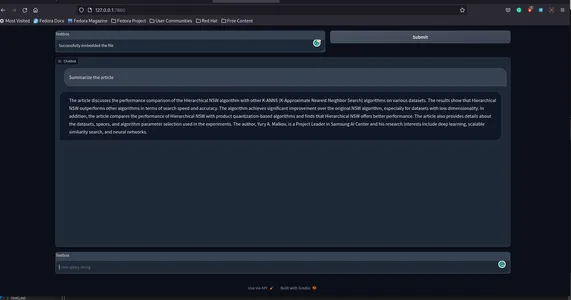
Ecco il repository GitHub per l’app sunilkumardash9/chat-arxiv.
Possibili miglioramenti
Abbiamo creato con successo una semplice applicazione per chattare con qualsiasi documento Arxiv, ma è possibile apportare alcuni miglioramenti.
- Negozio Vector autonomo: invece di utilizzare l’archivio vettoriale già pronto, puoi utilizzare archivi vettoriali autonomi disponibili con Haystack, come Weaviate, Milvus, ecc. Ciò non solo ti darà maggiore flessibilità ma anche miglioramenti significativi delle prestazioni.
- Citazioni: Possiamo aggiungere certezza alle risposte LLM aggiungendo citazioni appropriate.
- Più funzionalità: invece di limitarsi a un’interfaccia di chat, possiamo aggiungere funzionalità per eseguire il rendering delle pagine di PDF utilizzate come fonti per le risposte LLM. Dai un’occhiata a questo articolo, “Crea un ChatGPT per PDF con Langchain“, e il Repositorio GitHub per un’applicazione simile.
- Fine frontale: Un frontend migliore e più interattivo sarebbe molto meglio.
Conclusione
Quindi, si trattava di creare un’app di chat per i documenti Arxiv. Questa applicazione non è limitata solo ad Arxiv. Possiamo estenderlo anche ad altri siti, come PubMed. Con qualche modifica potremo utilizzare un’architettura simile anche per chattare con qualsiasi sito web. Quindi, in questo articolo, siamo passati dalla creazione di un componente Arxiv per scaricare i documenti Arxiv all’incorporarli utilizzando pipeline haystack e infine al recupero delle risposte dal LLM.
Punti chiave
- Haystack è una soluzione open source per la creazione di applicazioni NLP scalabili e pronte per la produzione.
- Haystack fornisce un approccio altamente modulare alla creazione di app del mondo reale. Fornisce nodi e pipeline per semplificare il recupero delle informazioni, la preelaborazione dei dati, l’incorporamento e la generazione di risposte.
- È una libreria open source di Huggingface per prototipare rapidamente qualsiasi applicazione. Fornisce un modo semplice per condividere modelli ML con chiunque.
- Utilizza un flusso di lavoro simile per creare app di chat per altri siti, come PubMed.
Domande frequenti
A. Costruisci chatbot IA personalizzati utilizzando moderni framework PNL come Haystack, Llama Index e Langchain.
R. I chatbot con risposta alle domande sono realizzati appositamente utilizzando metodi NLP all’avanguardia per rispondere a domande su dati personalizzati, come PDF, fogli di calcolo, CSV, ecc.
R. Haystack è un framework NLP open source per la creazione di applicazioni basate su LLM, come agenti AI, QA, RAG, ecc.
A. Arxiv è un archivio ad accesso aperto per la pubblicazione di articoli di ricerca su varie categorie, incluse ma non limitate a matematica, informatica, fisica, statistica, ecc.
R. I chatbot basati sull’intelligenza artificiale utilizzano tecnologie all’avanguardia di elaborazione del linguaggio naturale per offrire capacità di conversazione simili a quelle umane.
R. Crea un chatbot gratuitamente utilizzando framework open source come Langchain, haystack, ecc. Ma l’inferenza da LLM, come get-3.5, costa denaro.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell’autore.
Imparentato
Fonte: www.analyticsvidhya.com

