
introduzione
Retriever è la parte più importante del RAG (generazione aumentata di recupero) tubatura. In questo articolo implementerai un retriever personalizzato che combina il retriever di ricerca per parole chiave e vettore utilizzando LlamaIndex. Chatta con più documenti utilizzando Gemini LLM è il caso d'uso del progetto su cui costruiremo questa pipeline RAG. Per iniziare con il progetto, comprenderemo innanzitutto alcuni componenti critici come il contesto del servizio e dello storage per creare un'applicazione di questo tipo.
obiettivi formativi
- Ottieni informazioni approfondite sulla pipeline RAG, comprendendo i ruoli dei componenti Retriever e Generator nella generazione contestuale delle risposte.
- Impara a integrare le tecniche di ricerca di parole chiave e vettori per sviluppare un retriever personalizzato, migliorando la precisione della ricerca nelle applicazioni RAG.
- Acquisire competenza nell'utilizzo LlamaIndex per l'immissione di dati, fornendo contesto ai LLM e approfondendo la connessione ai dati personalizzati.
- Comprendere l'importanza dei retriever personalizzati nel mitigare le allucinazioni LLM risposte attraverso meccanismi di ricerca ibridi.
- Esplora implementazioni avanzate di retriever come riclassificazione e HyDE per migliorare la pertinenza dei documenti in RAG.
- Impara a integrare Gemini LLM e gli incorporamenti all'interno di LlamaIndex per la generazione di risposte e l'archiviazione dei dati, migliorando le funzionalità RAG.
- Sviluppa capacità decisionali per la configurazione personalizzata del retriever, inclusa la selezione tra operazioni AND e OR per l'ottimizzazione dei risultati di ricerca.
Questo articolo è stato pubblicato come parte del Blogathon sulla scienza dei dati.
Cos'è LlamaIndex?
Il campo di Modelli linguistici di grandi dimensioni si sta espandendo rapidamente, migliorando significativamente ogni giorno. Con il rapido rilascio di un numero crescente di modelli, cresce la necessità di integrare questi modelli con dati personalizzati. Questa integrazione offre ad aziende, imprese e utenti finali maggiore flessibilità e una connessione più profonda ai propri dati.
LlamaIndex, inizialmente noto come indice GPT, è un framework di dati progettato per le tue applicazioni LLM. Poiché la popolarità della creazione di chatbot personalizzati basati sui dati piace ChatGPT continua a crescere, framework come LlamaIndex diventano sempre più preziosi. Fondamentalmente, LlamaIndex fornisce vari connettori dati per facilitare l'inserimento dei dati. In questo articolo esploreremo come trasmettere i nostri dati come contesto al LLM, questo concetto è ciò che intendiamo per Retrieval Augmented Generation, RAG in breve.
Cos'è il RAG?
In Recupero generazione aumentata in breve RAG, ci sono due componenti principali: Retriever e Generator.
- Retriever può essere il database vettoriale, il suo compito è recuperare i documenti rilevanti per la query dell'utente e passarli come contesto al prompt.
- Il modello Generator è un modello Large Language, il suo compito è portare i documenti recuperati insieme al prompt per generare una risposta significativa dal contesto.
In questo modo RAG è la soluzione ottimale per l'apprendimento contestuale tramite la guida automatizzata di pochi colpi.
Importanza del documentalista
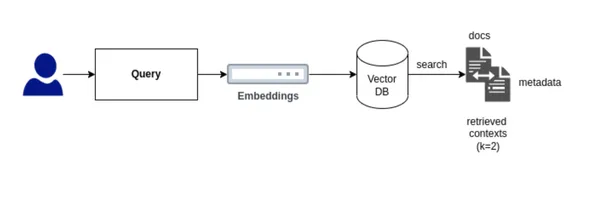
Comprendiamo l'importanza del componente Retriever nella pipeline RAG.
Per sviluppare un retriever personalizzato, è fondamentale determinare il tipo di retriever più adatto alle nostre esigenze. Per i nostri scopi, implementeremo una ricerca ibrida che integri sia la ricerca per parole chiave che la ricerca vettoriale.
La ricerca vettoriale identifica i documenti rilevanti per la query di un utente in base alla somiglianza o alla ricerca semantica, mentre la ricerca per parole chiave trova i documenti in base alla frequenza di occorrenza del termine. Questa integrazione può essere ottenuta in due modi utilizzando LlamaIndex. Quando si crea il retriever personalizzato per la ricerca ibrida, una decisione essenziale è scegliere tra l'utilizzo di un'operazione AND o OR:
- Operazione AND: Questo approccio recupera documenti che includono tutti i termini specificati, rendendolo più restrittivo ma garantendo un'elevata pertinenza. Puoi considerarlo come un'intersezione di risultati tra la ricerca per parole chiave e la ricerca vettoriale.
- Operazione OR: questo metodo recupera i documenti che contengono uno qualsiasi dei termini specificati, aumentando l'ampiezza dei risultati ma riducendo potenzialmente la pertinenza. Puoi considerarlo come un'unione di risultati tra la ricerca per parole chiave e la ricerca vettoriale.
Creazione di un recuperatore personalizzato utilizzando LLamaIndex
Costruiamo ora il customer retriever utilizzando LlamaIndex. Per costruirlo dobbiamo seguire alcuni passaggi.
Passaggio 1: installazione
Per iniziare con l'implementazione del codice su Google Colab o Jupyter Notebook, è necessario installare le librerie richieste, principalmente nel nostro caso utilizzeremo LlamaIndex per creare un retriever personalizzato, Gemini per il modello di incorporamento e l'inferenza LLM e PyPDF per il connettore dati .
!pip install llama-index
!pip install llama-index-multi-modal-llms-gemini
!pip install llama-index-embeddings-geminiPassaggio 2: imposta la chiave API di Google
In questo progetto, utilizzeremo Google Gemini come modello linguistico di grandi dimensioni per generare risposte e come modello di incorporamento per convertire e archiviare dati in database vettoriali o in memoria utilizzando LlamaIndex.
from getpass import getpass
GOOGLE_API_KEY = getpass("Enter your Google API:")Passaggio 3: caricare i dati e creare un nodo documento
In LlamaIndex, il caricamento dei dati viene eseguito utilizzando SimpleDirectoryLoader. Innanzitutto, devi creare una cartella e caricare i dati in qualsiasi formato in questa cartella dati. Nel nostro esempio, caricherò un file PDF nella cartella dati. Una volta caricato, il documento viene analizzato in nodi per suddividere il documento in segmenti più piccoli. Un nodo è uno schema di dati definito all'interno del framework LlamaIndex.
L'ultima versione di LlamaIndex ha aggiornato la struttura del codice, che ora include le definizioni per il parser del nodo, il modello di incorporamento e LLM nelle Impostazioni.
from llama_index.core import SimpleDirectoryReader
from llama_index.core import Settings
documents = SimpleDirectoryReader('data').load_data()
nodes = Settings.node_parser.get_nodes_from_documents(documents)Passaggio 4: impostazione del modello di incorporamento e del modello linguistico di grandi dimensioni
Gemini supporta vari modelli, tra cui gemini-pro, gemini-1.0-pro, gemini-1.5, vision model, tra gli altri. In questo caso, utilizzeremo il modello predefinito e forniremo la chiave API di Google. Per il modello di incorporamento in Gemini, attualmente utilizziamo embedding-001. Assicurati che venga aggiunta una chiave API valida.
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.llms.gemini import Gemini
Settings.embed_model = GeminiEmbedding(
model_name="models/embedding-001", api_key=GOOGLE_API_KEY
)
Settings.llm = Gemini(api_key=GOOGLE_API_KEY)Passaggio 5: definire il contesto di archiviazione e archiviare i dati
Una volta che i dati sono stati analizzati in nodi, LlamaIndex fornisce un contesto di archiviazione, che offre l'archiviazione predefinita dei documenti per archiviare gli incorporamenti vettoriali dei dati. Questo contesto di archiviazione mantiene i dati in memoria, consentendone l'indicizzazione successiva.
from llama_index.core import StorageContext
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)Crea indice: parola chiave e indice
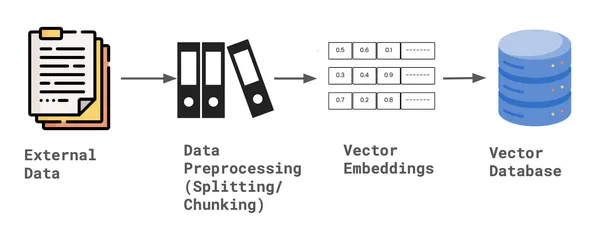
Per creare il retriever personalizzato per eseguire la ricerca ibrida, dobbiamo creare due indici. Primo Indice vettoriale che può eseguire la ricerca vettoriale, secondo Indice di parole chiave che può eseguire la ricerca per parola chiave. Per creare l'indice, abbiamo richiesto il contesto di archiviazione e i documenti del nodo, insieme alle impostazioni predefinite del modello di incorporamento e LLM.
from llama_index.core import SimpleKeywordTableIndex, VectorStoreIndex
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
keyword_index = SimpleKeywordTableIndex(nodes, storage_context=storage_context)Passaggio 6: costruire un retriever personalizzato
Per costruire un retriever personalizzato per la ricerca ibrida utilizzando LlamaIndex, dobbiamo prima definire lo schema, nello specifico configurando opportunamente i nodi. Per il retriever sono necessari sia un Vector Index Retriever che un Keyword Retriever. Ciò ci consente di eseguire ricerche ibride, integrando entrambe le tecniche per ridurre al minimo le allucinazioni. Inoltre, dobbiamo specificare la modalità, AND o OR, a seconda di come vogliamo combinare i risultati.
Una volta configurati i nodi, interroghiamo il bundle per ciascun ID nodo utilizzando sia il vettore che i recuperatori di parole chiave. In base alla modalità selezionata, definiamo e finalizziamo il retriever personalizzato.
from llama_index.core import QueryBundle
from llama_index.core.schema import NodeWithScore
from llama_index.core.retrievers import (
BaseRetriever,
VectorIndexRetriever,
KeywordTableSimpleRetriever,
)
from typing import List
class CustomRetriever(BaseRetriever):
def __init__(
self,
vector_retriever: VectorIndexRetriever,
keyword_retriever: KeywordTableSimpleRetriever,
mode: str = "AND") -> None:
self._vector_retriever = vector_retriever
self._keyword_retriever = keyword_retriever
if mode not in ("AND", "OR"):
raise ValueError("Invalid mode.")
self._mode = mode
super().__init__()
def _retrieve(self, query_bundle: QueryBundle) -> List(NodeWithScore):
vector_nodes = self._vector_retriever.retrieve(query_bundle)
keyword_nodes = self._keyword_retriever.retrieve(query_bundle)
vector_ids = {n.node.node_id for n in vector_nodes}
keyword_ids = {n.node.node_id for n in keyword_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in keyword_nodes})
if self._mode == "AND":
retrieve_ids = vector_ids.intersection(keyword_ids)
else:
retrieve_ids = vector_ids.union(keyword_ids)
retrieve_nodes = (combined_dict(r_id) for r_id in retrieve_ids)
return retrieve_nodesPassaggio 7: definire i recuperatori
Ora che la classe retriever personalizzata è definita, è necessario creare un'istanza del retriever e sintetizzare il motore di query. Un sintetizzatore di risposte viene utilizzato per generare una risposta da un LLM in base a una query dell'utente e a un determinato insieme di blocchi di testo. L'output di un sintetizzatore di risposta è un oggetto Response, che accetta il retriever personalizzato come uno dei parametri.
from llama_index.core import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
keyword_retriever = KeywordTableSimpleRetriever(index=keyword_index)
# custom retriever => combine vector and keyword retriever
custom_retriever = CustomRetriever(vector_retriever, keyword_retriever)
# define response synthesizer
response_synthesizer = get_response_synthesizer()
custom_query_engine = RetrieverQueryEngine(
retriever=custom_retriever,
response_synthesizer=response_synthesizer,
)Passaggio 8: eseguire il motore di query di recupero personalizzato
Infine, abbiamo sviluppato il nostro retriever personalizzato che riduce significativamente le allucinazioni. Per testarne l'efficacia, abbiamo eseguito le query degli utenti includendo un prompt dall'interno del contesto e un altro dall'esterno del contesto, quindi abbiamo valutato le risposte generate.
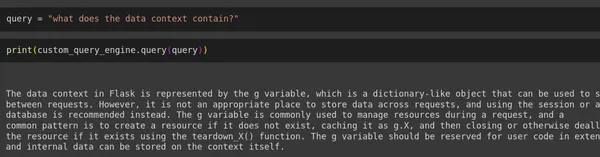
query = "what does the data context contain?"
print(custom_query_engine.query(query))
print(custom_query_engine.query("what is science?"))Produzione

Conclusione
Abbiamo implementato con successo un retriever personalizzato che esegue la ricerca ibrida combinando Vector e Keyword retriever utilizzando LlamaIndex, con il supporto di Gemini LLM e Embeddings. Questo approccio riduce efficacemente le allucinazioni LLM in una certa misura in una tipica pipeline RAG.
Punti chiave
- Sviluppo di un retriever personalizzato che integra sia Vector che Keyword retriever, migliorando le capacità di ricerca e l'accuratezza nell'identificazione dei documenti rilevanti per RAG.
- Implementazione di Gemini Embedding e LLM utilizzando LlamaIndex Settings, che è stato sostituito nell'ultima versione, in precedenza veniva eseguito utilizzando Service Context, che ora è deprecato.
- Nella creazione del retriever personalizzato, una decisione chiave è se utilizzare l'operazione AND o OR, bilanciando l'intersezione e l'unione dei risultati della ricerca di parole chiave e vettori in base alle esigenze specifiche.
- La configurazione del retriever personalizzato aiuta a ridurre in modo significativo le allucinazioni nelle risposte del modello linguistico di grandi dimensioni utilizzando un meccanismo di ricerca ibrido all'interno della pipeline RAG.
Domande frequenti
R. La ricerca ibrida è fondamentalmente una combinazione di ricerca in stile parola chiave e ricerca in stile vettoriale. Ha il vantaggio di eseguire la ricerca per parole chiave nonché il vantaggio di eseguire una ricerca semantica che otteniamo dagli incorporamenti e da una ricerca vettoriale.
R. Nel RAG Retriever c'è tutto. Se i relativi documenti non vengono restituiti al modello Generator non serve a nulla. Per ridurre le allucinazioni, il contesto deve essere accurato. È qui che esistono vari metodi per migliorare le prestazioni del Retriever. Alcuni di essi includono: riclassificazione, ricerca ibrida, recupero della finestra delle frasi, HyDE e così via.
R. Sì, la ricerca ibrida può essere utilizzata in Langchain. In Langchain, possiamo definire algoritmi come BM25 o TFIDF come parole chiave retriever e utilizzare un database vettoriale come retriever per la ricerca vettoriale. Una volta impostati entrambi i retriever, è possibile integrarli utilizzando Ensemble Retriever, che facilita la ricerca ibrida in Langchain. Questo approccio combinato può quindi essere inserito nella catena RetrievalQA per l'elaborazione delle query.
R. Esistono vari database vettoriali in grado di integrare internamente la ricerca ibrida utilizzando la ricerca vettoriale ed eliminando la necessità di ricerca per parole chiave. Alcuni di questi database vettoriali che supportano la ricerca ibrida interna includono Qdrant, Weaviate, Elastic Search, tra gli altri.
Riferimento
https://docs.llamaindex.ai/en/stable/examples/query_engine/CustomRetrievers/
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
Fonte: www.analyticsvidhya.com

