
introduzione
Incorporando capacità visive nel potente modello linguistico GPT-4, ChatGPT-4 Vision, o GPT-4V, rappresenta una svolta degna di nota nel campo dell'intelligenza artificiale. Con questo miglioramento, il modello può ora elaborare, comprendere e produrre contenuti visivi, rendendolo uno strumento flessibile adatto a vari usi. Le funzioni principali di ChatGPT-4 Vision, come l'analisi delle immagini, l'analisi video e la generazione di immagini, saranno trattate in dettaglio in questo articolo, insieme ad alcuni esempi di come queste funzionalità potrebbero essere utilizzate in diversi contesti.

Panoramica
- ChatGPT-4 Vision integra le funzionalità visive con GPT-4, consentendo l'elaborazione di immagini e video insieme alla generazione di testo.
- L'analisi delle immagini di ChatGPT-4 Vision comprende il rilevamento degli oggetti, la classificazione e la comprensione della scena, offrendo informazioni accurate ed efficienti.
- Le caratteristiche principali includono il rilevamento di oggetti per attività automatizzate, la classificazione di immagini per vari settori e la comprensione della scena per applicazioni avanzate.
- ChatGPT-4 Vision è in grado di generare immagini da descrizioni di testo, offrendo soluzioni innovative per la progettazione, la creazione di contenuti e altro ancora.
- Le capacità di analisi video di ChatGPT-4 Vision includono il riconoscimento delle azioni, il rilevamento del movimento e l'identificazione degli eventi, potenziando vari campi come la sicurezza e l'analisi sportiva.
- Le applicazioni pratiche spaziano dalla diagnostica sanitaria alla ricerca visiva nel commercio al dettaglio, dalla sorveglianza di sicurezza all'apprendimento interattivo, dimostrando la versatilità di ChatGPT-4 Vision.
Analisi delle immagini
L'estrazione di informazioni utili dalle immagini è nota come analisi delle immagini. Consente il completamento di attività come il rilevamento di oggetti, la classificazione delle immagini e la comprensione della scena. Con la sua sofisticata architettura di rete neurale, ChatGPT-4 Vision è in grado di completare queste attività con un elevato grado di efficienza e accuratezza.
Caratteristiche principali
- Object Detection è il processo di ricerca e identificazione di elementi in un'immagine. I suoi utilizzi includono la gestione dell'inventario, le auto senza conducente e la sorveglianza automatizzata.
- Classificazione delle immagini: la classificazione delle immagini in gruppi predeterminati è nota come classificazione delle immagini. Ciò aiuta nell'identificazione delle malattie nell'imaging medico, nella moderazione dei contenuti dei social media e nella classificazione dei prodotti al dettaglio.
- Comprendere la scena: esaminare lo sfondo e le connessioni tra i numerosi elementi di un'immagine può essere utile per applicazioni in ambito robotico, di realtà aumentata e di assistenza virtuale.
Esempio di caso d'uso
Visione di ChatGPT-4 in un sistema di sicurezza per la casa intelligente può esaminare i filmati delle telecamere di sicurezza per trovare attività anomale o intrusi. Può categorizzare cose come persone, animali domestici e auto e far scattare gli allarmi in base a linee guida di sicurezza prestabilite.
Implementazione dell'analisi delle immagini
Per prima cosa installiamo le dipendenze necessarie
!pip install openai
!pip install requestsImportazione delle librerie necessarie
import openai
import requests
import base64
from openai import OpenAI
from PIL import Image
from io import BytesIO
from IPython.display import displayAnalisi delle immagini con url
client = OpenAI(api_key='Enter your Key')
response = client.chat.completions.create(
model="gpt-4o",
messages=(
{
"role": "user",
"content": (
{"type": "text", "text": "Describe me this image"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
),
}
),
max_tokens=300,
)
response.choices(0).message.contentNel codice sopra, stiamo passando l'url dell'immagine insieme al prompt per descrivere l'immagine nell'url. Di seguito è riportata l'immagine che stiamo passando.

Produzione

Analisi delle immagini con immagini locali
api_key = "Enter your key"
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "/content/cat.jpeg"
# Getting the base64 string
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": (
{
"role": "user",
"content": (
{
"type": "text",
"text": "Describe me this image"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
)
}
),
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
Nell'esempio sopra, passiamo l'immagine del gatto sottostante, mostrando la modalità per descrivere l'immagine.

Produzione
print(response.json()("choices")(0)("message")("content"))
Passaggio di più immagini
from openai import OpenAI
client = OpenAI(api_key='Enter your Key')
response = client.chat.completions.create(
model="gpt-4o",
messages=(
{
"role": "user",
"content": (
{
"type": "text",
"text": "Tell me the difference and similarities of these two images",
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/3/3f/Walking_tiger_female.jpg/1920px-Walking_tiger_female.jpg",
},
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/7/73/Lion_waiting_in_Namibia.jpg",
},
},
),
}
),
max_tokens=300,
)
Nel codice sopra, passiamo più immagini usando i loro URL. Di seguito sono riportate le immagini che stiamo passando.


Abbiamo sollecitato il confronto di queste due immagini per individuarne somiglianze e differenze.
Produzione
print(response.choices(0).message.content)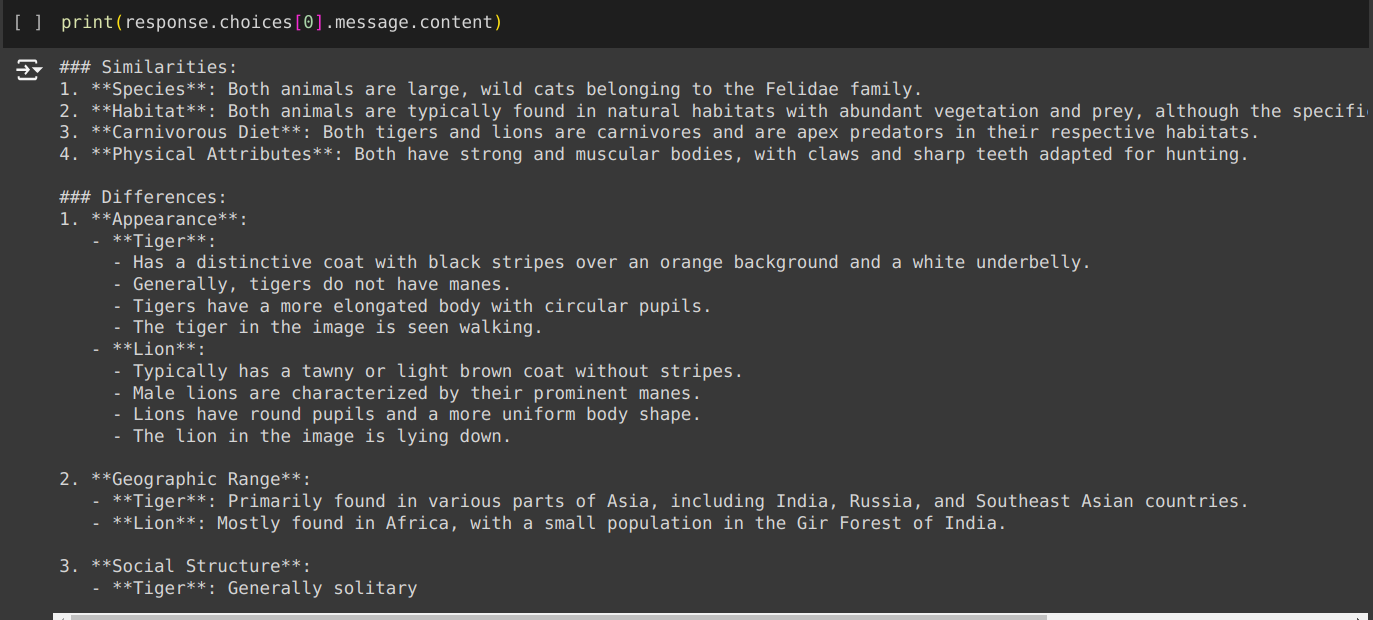
Generazione di immagini
Uno di ChatGPT-4 La caratteristica più intrigante di Vision è la sua capacità di produrre immagini da descrizioni testuali. Ciò crea nuove opportunità per la progettazione, la produzione di contenuti e le applicazioni creative.
Caratteristiche principali
- Generazione testo-immagine: il processo di produzione di elementi visivi da descrizioni scritte esaustive. Ha applicazioni nei settori dell'intrattenimento, dell'istruzione e della pubblicità.
- Trasferimento di stile: trasferire lo stile di un'immagine a un'altra è noto come trasferimento di stile. Ciò aiuta a creare materiale su social network, graphic design e arte digitale.
- L'editing delle immagini è il processo di alterazione di immagini preesistenti in risposta a istruzioni di testo. Può migliorare le attività che coinvolgono manipolazione, restauro e fotoritocco.
Esempio di caso d'uso
I designer del settore della moda possono usare ChatGPT-4 Vision per creare immagini di design di indumenti da descrizioni scritte. Questo può accelerare il processo di progettazione, abilitare la prototipazione virtuale e migliorare lo scambio di idee.
Leggi anche: Ecco come utilizzare l'API GPT 4o per la visione, il testo, le immagini e altro ancora.
Implementazione della generazione di immagini
L'API Images fornisce tre metodi per interagire con le immagini:
- Creazione di immagini da zero basate su un prompt di testo (DALL-E 3 e DALL – E 2)
- Creazione di varianti di un'immagine esistente (solo DALL – E 2)
Creazione di immagini tramite prompt
from openai import OpenAI
client = OpenAI(api_key='Enter your key')
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data(0).url
Abbiamo attivato la modalità DALL-E 3 per creare un'immagine di un gatto siamese bianco.
# Download the image
image_response = requests.get(image_url)
# Open the image using PIL
image = Image.open(BytesIO(image_response.content))
# Display the image
display(image)Produzione

Variazione dell'immagine di un'immagine esistente
from openai import OpenAI
client = OpenAI(api_key='Enter your key')
response = client.images.create_variation(
model="dall-e-2",
image=open("/content/spider_man.png", "rb"),
n=1,
size="1024x1024"
)
image_url = response.data(0).url
Stiamo utilizzando DALL-E 2 per creare una variante dell'immagine esistente. Stiamo passando l'immagine sottostante all'API per creare una variante.

# Download the image
image_response = requests.get(image_url)
# Open the image using PIL
image = Image.open(BytesIO(image_response.content))
# Display the image
display(image)Produzione

Possiamo vedere che il modello ha creato una variante della nostra immagine.
Analisi video
È possibile estrarre informazioni utili tramite l'elaborazione di flussi video, espandendo l'ambito dell'analisi delle immagini nel dominio temporale. L'identificazione delle azioni, il rilevamento del movimento e il rilevamento degli eventi nei video sono tra le funzioni di cui ChatGPT-4 Vision è capace.
Caratteristiche principali
- Riconoscimento dell'azione: Riconoscere particolari movimenti fatti dai partecipanti in un video. Può essere utilizzato nella sorveglianza, nell'interazione uomo-computer e nell'analisi sportiva.
- Rilevamento del movimento: Ciò può essere utile per le applicazioni di animazione, videosorveglianza e monitoraggio del traffico.
- Rilevamento degli eventi: È il processo di individuazione di eventi importanti in un video. Può essere applicato in vari campi, tra cui la sicurezza per il rilevamento di incidenti, l'intrattenimento per la generazione automatizzata di momenti salienti e l'assistenza sanitaria per il monitoraggio delle attività dei pazienti.
Esempio di caso d'uso
ChatGPT-4 Vision può analizzare i video di gioco in analisi sportive per identificare le attività dei giocatori come palleggio, tiro e passaggio a basket. Questi dati possono fornire informazioni sulle prestazioni dei giocatori, sulla strategia di gioco e sull'efficacia dell'allenamento.
Leggi anche: Come utilizzare l'API DALL-E 3 per la generazione di immagini?
Implementazione dell'analisi video
import cv2
import base64
import requests
def encode_image(image):
_, buffer = cv2.imencode('.jpg', image)
return base64.b64encode(buffer).decode('utf-8')
def extract_frames(video_path, frame_interval=30):
cap = cv2.VideoCapture(video_path)
frames = ()
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if frame_count % frame_interval == 0:
frames.append(frame)
frame_count += 1
cap.release()
return frames
def analyze_frame(frame, api_key):
base64_image = encode_image(frame)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": (
{
"role": "user",
"content": (
{
"type": "text",
"text": "Describe me this image"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
)
}
),
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
return response.json()
def analyze_video(video_path, api_key, frame_interval=30):
frames = extract_frames(video_path, frame_interval)
analysis_results = ()
for frame in frames:
result = analyze_frame(frame, api_key)
analysis_results.append(result)
return analysis_results
# Path to your video
video_path = "/content/Kendall_Jenner.mp4"
api_key = "Enter your key"
# Analyze the video
results = analyze_video(video_path, api_key)
for result in results:
print(result('choices')(0)("message")("content"))Nel codice sopra riportato, stiamo registrando un video di una celebrità che fa una passeggiata sulla rampa; stiamo registrando i nostri fotogrammi a un intervallo di 30 ed effettuando una chiamata API per conoscerne la descrizione.
Produzione

Leggi anche: Guida all'elaborazione del linguaggio con GPT-4 nell'intelligenza artificiale
Applicazioni pratiche della visione GPT-4
Ecco le applicazioni di GPT-4 Vision:
Cure mediche
In campo medico, GPT-4 Vision utilizza l'analisi delle immagini per aiutare a diagnosticare malattie, come MRI e raggi X. Può aiutare i medici a prendere decisioni consapevoli evidenziando aree di interesse e offrendo secondi punti di vista.
Ad esempio
L'analisi delle immagini mediche individua anomalie nelle radiografie, come tumori o fratture, e fornisce ai radiologi descrizioni complete di questi risultati.
E-commerce e vendita al dettaglio
GPT-4 Vision migliora l'esperienza di acquisto sia per i clienti al dettaglio che per quelli online offrendo descrizioni di prodotto approfondite e funzionalità di ricerca visiva. I clienti possono caricare fotografie per individuare articoli correlati o raccomandazioni in base alle loro preferenze visive.
Ad esempio
Ricerca visiva: Consentire ai clienti di caricare fotografie per cercare prodotti, ad esempio per trovare un vestito che assomigli a quello indossato da un personaggio famoso.
Descrizioni automatizzate dei prodotti: Generazione di descrizioni dettagliate dei prodotti basate sulle immagini, migliorando la gestione del catalogo e l'esperienza utente.
Conclusione
GPT-4 Vision è un progresso rivoluzionario in intelligenza artificiale che combina perfettamente la comprensione del linguaggio naturale con l'analisi visiva. Le sue applicazioni sono utilizzate in vari settori, tra cui sanità, commercio al dettaglio, sicurezza e istruzione. Offrono soluzioni creative e migliorano le esperienze degli utenti. Utilizzando sofisticate topologie di trasformatori e apprendimento multimodale, GPT-4 Vision crea nuove strade per interagire e comprendere il mondo visivo.
Domande frequenti
Risposta: GPT-4 Vision è un modello di intelligenza artificiale avanzato che integra l'elaborazione del linguaggio naturale con capacità di analisi di immagini e video, consentendo un'interpretazione dettagliata e la generazione di contenuti visivi.
Risposta: Le principali applicazioni includono l'assistenza sanitaria (analisi di immagini mediche), la vendita al dettaglio (ricerca visiva e descrizioni di prodotti), la sicurezza (videosorveglianza e rilevamento delle intrusioni) e l'istruzione (apprendimento interattivo e valutazione degli incarichi).
Risposta: GPT-4 Vision identifica oggetti, scene e attività all'interno delle immagini e genera descrizioni dettagliate in linguaggio naturale del contenuto visivo.
Risposta: Sì, GPT-4 Vision può analizzare sequenze di fotogrammi nei video per identificare azioni, eventi e cambiamenti nel tempo, migliorando le applicazioni in sicurezza, intrattenimento e altro ancora.
Risposta: Sì, GPT-4 Vision può generare immagini da descrizioni testuali, il che è utile nelle applicazioni di progettazione creativa e prototipazione.
Fonte: www.analyticsvidhya.com

