
introduzione
Viviamo in un’epoca in cui i modelli linguistici di grandi dimensioni (LLM) sono in aumento. Una delle prime cose che ci viene in mente oggigiorno quando sentiamo LLM è ChatGPT di OpenAI. Ora, sapevi che ChatGPT non è esattamente un LLM ma un’applicazione che funziona su modelli LLM come GPT 3.5 e GPT 4? Possiamo sviluppare applicazioni AI molto rapidamente richiedendo un LLM. Ma c’è una limitazione. Un’applicazione può richiedere più richieste su LLM, il che comporta la scrittura del codice di colla più volte. Questa limitazione può essere facilmente superata utilizzando LangChain.
Questo articolo riguarda LangChain e le sue applicazioni. Presumo che tu abbia una buona conoscenza di ChatGPT come applicazione. Per maggiori dettagli sugli LLM e sui principi base dell’AI generativa puoi fare riferimento al mio precedente articolo su ingegneria tempestiva nell’intelligenza artificiale generativa.
obiettivi formativi
- Conoscere le basi del framework LangChain.
- Sapere perché LangChain è più veloce.
- Comprendere i componenti essenziali di LangChain.
- Comprendere come applicare LangChain in Prompt Engineering.
Questo articolo è stato pubblicato come parte del Blogathon sulla scienza dei dati.
Cos’è LangChain?
LangChain, creato da Harrison Chase, è un framework open source che consente lo sviluppo di applicazioni basato su un modello linguistico. Ci sono due pacchetti vale a dire. Python e JavaScript (TypeScript) con particolare attenzione alla composizione e alla modularità.

Perché utilizzare LangChain?
Quando utilizziamo ChatGPT, LLM effettua internamente chiamate dirette all’API di OpenAI. Le chiamate API tramite LangChain vengono effettuate utilizzando componenti quali prompt, modelli e parser di output. LangChain semplifica il difficile compito di lavorare e costruire con modelli di intelligenza artificiale. Lo fa in due modi:
- Integrazione: Dati esterni come file, dati API e altre applicazioni vengono portati nei LLM.
- Agenzia: Facilita l’interazione tra gli LLM e il loro ambiente attraverso il processo decisionale.
Attraverso componenti, catene personalizzate, velocità e comunità, LangChain aiuta a evitare punti di attrito durante la creazione di applicazioni complesse basate su LLM.
Componenti di LangChain
Ci sono 3 componenti principali di LangChain.
- Modelli linguistici: Le interfacce comuni vengono utilizzate per richiamare modelli linguistici. LangChain fornisce l’integrazione per i seguenti tipi di modelli:
i) LLM: qui, il modello prende una stringa di testo come input e restituisce una stringa di testo.
ii) Modelli di chat: qui, il modello prende un elenco di messaggi di chat come input e restituisce un messaggio di chat. Un modello linguistico supporta questi tipi di modelli. - Richiede: Aiuta nella creazione di modelli e consente la selezione e la gestione dinamica degli input del modello. Si tratta di un insieme di istruzioni che l’utente trasmette per guidare il modello nella produzione di un output coerente basato sul linguaggio, come rispondere a domande, completare frasi, scrivere riepiloghi, ecc.
- Parser di output: Estrae informazioni dagli output del modello. Aiuta a ottenere informazioni più strutturate rispetto al semplice testo come output.
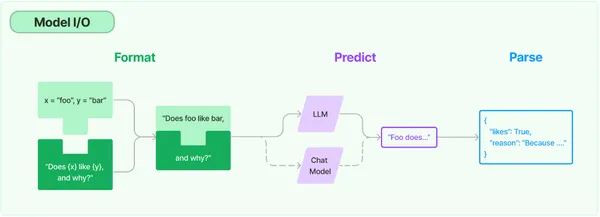
Applicazione pratica di LangChain
Iniziamo a lavorare con LLM con l’aiuto di LangChain.
openai_api_key='sk-MyAPIKey'Ora lavoreremo con gli aspetti pratici di LLM per comprendere i principi fondamentali di LangChain.
I ChatMessages verranno discussi all’inizio. Ha un tipo di messaggio con sistema, umano e AI. I ruoli di ciascuno di questi sono:
- Sistema: contesto di fondo utile che guida l’intelligenza artificiale.
- Umano: messaggio che rappresenta l’utente.
- AI – Messaggi che mostrano la risposta dell’AI.
#Importing necessary packages
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
chat = ChatOpenAI(temperature=.5, openai_api_key=openai_api_key)
#temperature controls output randomness (0 = deterministic, 1 = random)Abbiamo importato ChatOpenAI, HumanMessage, SystemMessage e AIMessage. La temperatura è un parametro che definisce il grado di casualità dell’output e varia da 0 a 1. Se la temperatura è impostata su 1, l’output generato sarà altamente casuale, mentre se è impostato su 0, l’output sarà meno casuale . Lo abbiamo impostato su .5.
# Creating a Chat Model
chat(
(
SystemMessage(content="You are a nice AI bot that helps a user figure out
what to eat in one short sentence"),
HumanMessage(content="I like Bengali food, what should I eat?")
)
)Nelle righe di codice sopra, abbiamo creato un modello di chat. Quindi, abbiamo digitato due messaggi: uno è un messaggio di sistema che capirà cosa mangiare in una breve frase, e l’altro è un messaggio umano che chiede quale cibo bengalese l’utente dovrebbe mangiare. Il messaggio dell’AI è:

Possiamo trasmettere più cronologia chat con le risposte dell’IA.
# Passing chat history
chat(
(
SystemMessage(content="You are a nice AI bot that helps a user figure out
where to travel in one short sentence"),
HumanMessage(content="I like the spirtual places, where should I go?"),
AIMessage(content="You should go to Madurai, Rameswaram"),
HumanMessage(content="What are the places I should visit there?")
)
)Nel caso sopra, stiamo dicendo che il bot AI suggerisce i luoghi in cui viaggiare in una breve frase. L’utente dice che gli piace visitare luoghi spirituali. Questo invia un messaggio all’IA che l’utente intende visitare Madurai e Rameswaram. Quindi, l’utente ha chiesto quali fossero i luoghi da visitare.

È interessante notare che alla modella non è stato detto dove sono andato. Ha invece fatto riferimento alla cronologia per scoprire dove è andato l’utente e ha risposto perfettamente.
Come funzionano i componenti di LangChain?
Vediamo come i tre componenti di LangChain, discussi in precedenza, fanno funzionare un LLM.
Il modello linguistico
Il primo componente è un modello linguistico. Un insieme diversificato di modelli rafforza l’API OpenAI con funzionalità diverse. Tutti questi modelli possono essere personalizzati per applicazioni specifiche.
# Importing OpenAI and creating a model
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", openai_api_key=openai_api_key)Il modello è stato modificato da predefinito a testo-ada-001. È il modello più veloce della serie GPT-3 e ha dimostrato di costare il più basso. Ora passeremo una semplice stringa al modello linguistico.
# Passing regular string into the language model
llm("What day comes after Saturday?")
Pertanto, abbiamo ottenuto l’output desiderato.
Il componente successivo è l’estensione del modello linguistico, cioè un modello di chat. Un modello di chat accetta una serie di messaggi e restituisce un output del messaggio.
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
chat = ChatOpenAI(temperature=1, openai_api_key=openai_api_key)Abbiamo impostato la temperatura su 1 per rendere il modello più casuale.
# Passing series of messages to the model
chat(
(
SystemMessage(content="You are an unhelpful AI bot that makes a joke at
whatever the user says"),
HumanMessage(content="I would like to eat South Indian food, what are some
good South Indian food I can try?")
)
)In questo caso il sistema trasmette il messaggio che il bot AI è inutile e scherza su qualunque cosa dicano gli utenti. L’utente chiede alcuni buoni suggerimenti sul cibo dell’India meridionale. Vediamo l’output.

Qui vediamo che all’inizio fa alcune battute, ma suggerisce anche del buon cibo dell’India meridionale.
Il suggerimento
Il secondo componente è il prompt. Funziona come input per il modello e raramente è codificato. Più componenti costruiscono un prompt e un modello di prompt è responsabile della costruzione di questo input. LangChain aiuta a semplificare il lavoro con i prompt.
# Instructional Prompt
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key)
prompt = """
Today is Monday, tomorrow is Wednesday.
What is wrong with that statement?
"""
llm(prompt)Le richieste di cui sopra sono di tipo didattico. Vediamo l’output

Quindi, ha rilevato correttamente l’errore.
I modelli di prompt sono come ricette predefinite per la generazione di prompt per LLM. Istruzioni, esempi brevi, contesto e domande specifici per una determinata attività fanno parte di un modello.
from langchain.llms import OpenAI
from langchain import PromptTemplate
llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key)
# Notice "location" below, that is a placeholder for another value later
template = """
I really want to travel to {location}. What should I do there?
Respond in one short sentence
"""
prompt = PromptTemplate(
input_variables=("location"),
template=template,
)
final_prompt = prompt.format(location='Kanyakumari')
print (f"Final Prompt: {final_prompt}")
print ("-----------")
print (f"LLM Output: {llm(final_prompt)}")Quindi, all’inizio abbiamo importato i pacchetti. Il modello che abbiamo usato qui è text-DaVinci-003, che può svolgere qualsiasi compito linguistico con una qualità migliore, risultati più lunghi e istruzioni coerenti rispetto a Curie, Babbage o Ada. Quindi, ora abbiamo creato un modello. La variabile di input è la posizione e il valore è Kanyakumari.

Il parser di output
Il terzo componente è il parser di output, che abilita il formato dell’output di un modello. Parser è un metodo che estrarrà l’output del testo del modello nel formato desiderato.
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key)# How you would like your response structured. This is basically a fancy prompt template
response_schemas = (
ResponseSchema(name="bad_string", description="This a poorly formatted user input string"),
ResponseSchema(name="good_string", description="This is your response, a reformatted response")
)
# How you would like to parse your output
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)# See the prompt template you created for formatting
format_instructions = output_parser.get_format_instructions()
print (format_instructions)
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
prompt = PromptTemplate(
input_variables=("user_input"),
partial_variables={"format_instructions": format_instructions},
template=template
)
promptValue = prompt.format(user_input="welcom to Gugrat!")
print(promptValue)
llm_output = llm(promptValue)
llm_output
output_parser.parse(llm_output)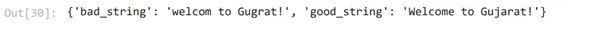
Il modello linguistico restituirà solo una stringa, ma se abbiamo bisogno di un oggetto JSON, dobbiamo analizzare quella stringa. Nello schema di risposta sopra, possiamo vedere che ci sono 2 oggetti campo, vale a dire, stringa valida e stringa errata. Quindi, abbiamo creato un modello di prompt.
Conclusione
In questo articolo abbiamo esaminato brevemente i componenti chiave della LangChain e le loro applicazioni. Fin dall’inizio, abbiamo capito cos’è LangChain e come semplifica il difficile compito di lavorare e costruire con modelli di intelligenza artificiale. Abbiamo anche compreso i componenti chiave di LangChain, vale a dire. richiede (una serie di istruzioni trasmesse da un utente per guidare il modello a produrre un output coerente), modelli linguistici (la base che aiuta a dare l’output desiderato) e parser di output (consente di ottenere informazioni più strutturate rispetto al semplice testo come output). Comprendendo questi componenti chiave, abbiamo costruito una solida base per la creazione di applicazioni personalizzate.
Punti chiave
- Gli LLM possiedono la capacità di rivoluzionare l’intelligenza artificiale. Apre una miriade di opportunità per chi cerca informazioni, poiché è possibile chiedere e rispondere a qualsiasi cosa.
- Mentre il prompt engineering di base di ChatGPT è di buon auspicio per molti scopi, lo sviluppo di applicazioni LLM basate su LangChain è molto più veloce.
- L’elevato grado di integrazione con varie piattaforme di intelligenza artificiale aiuta a utilizzare meglio i LLM.
Domande frequenti
Ris. Python e JavaScript sono i due pacchetti di LangChain.
Ris. La temperatura è un parametro che definisce il grado di casualità dell’output. Il suo valore varia da 0 a 1.
Ris. text-ada-001 è il modello più veloce della serie GPT-3.
Ris. Parser è un metodo che estrarrà l’output testuale di un modello nel formato desiderato.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell’autore.
Imparentato
Fonte: www.analyticsvidhya.com

