
Introduzione
Nella seconda parte della nostra serie sulla creazione di un'applicazione RAG su un Raspberry Pi, approfondiremo le basi gettate nella prima parte, in cui abbiamo creato e testato la pipeline principale. Nella prima parte, abbiamo creato la pipeline principale e l'abbiamo testata per assicurarci che tutto funzionasse come previsto. Ora, faremo un ulteriore passo avanti creando un'applicazione FastAPI per servire la nostra pipeline RAG e creando un'app Reflex per offrire agli utenti un modo semplice e interattivo per accedervi. Questa parte ti guiderà attraverso la configurazione del back-end FastAPI, la progettazione del front-end con Reflex e l'avvio e l'esecuzione di tutto sul tuo Raspberry Pi. Alla fine, avrai un'applicazione completa e funzionante, pronta per l'uso nel mondo reale.
Obiettivi di apprendimento
- Impostare un back-end FastAPI per integrarlo con la pipeline RAG esistente ed elaborare le query in modo efficiente.
- Progettare un'interfaccia intuitiva utilizzando Reflex per interagire con il back-end FastAPI e la pipeline RAG.
- Crea e testa gli endpoint API per l'interrogazione e l'inserimento di documenti, assicurando il corretto funzionamento con FastAPI.
- Distribuisci e testa l'applicazione completa su un Raspberry Pi, assicurandoti che i componenti back-end e front-end funzionino senza problemi.
- Comprendere l'integrazione tra FastAPI e Reflex per un'esperienza applicativa RAG coerente.
- Implementare e risolvere i problemi dei componenti FastAPI e Reflex per fornire un'applicazione RAG completamente operativa su un Raspberry Pi.
Se vi siete persi l'edizione precedente, assicuratevi di dargli un'occhiata qui: Self-hosting di applicazioni RAG su dispositivi Edge con Langchain e Ollama – Parte I.
Questo articolo è stato pubblicato come parte della Blogathon sulla scienza dei dati.
Creazione dell'ambiente Python
Prima di iniziare a creare l'applicazione, dobbiamo configurare l'ambiente. Crea un ambiente e installa le dipendenze sottostanti:
deeplake
boto3==1.34.144
botocore==1.34.144
fastapi==0.110.3
gunicorn==22.0.0
httpx==0.27.0
huggingface-hub==0.23.4
langchain==0.2.6
langchain-community==0.2.6
langchain-core==0.2.11
langchain-experimental==0.0.62
langchain-text-splitters==0.2.2
langsmith==0.1.83
marshmallow==3.21.3
numpy==1.26.4
pandas==2.2.2
pydantic==2.8.2
pydantic_core==2.20.1
PyMuPDF==1.24.7
PyMuPDFb==1.24.6
python-dotenv==1.0.1
pytz==2024.1
PyYAML==6.0.1
reflex==0.5.6
requests==2.32.3
reflex==0.5.6
reflex-hosting-cli==0.1.13Una volta installati i pacchetti richiesti, dobbiamo avere i modelli richiesti presenti nel dispositivo. Lo faremo usando Ollama. Segui i passaggi della Parte 1 di questo articolo per scaricare sia il linguaggio che i modelli di incorporamento. Infine, crea due directory per le applicazioni back-end e front-end.
Una volta estratti i modelli tramite Ollama, siamo pronti per creare l'applicazione finale.
Sviluppo del back-end con FastAPI
Nella Parte 1 di questo articolo, abbiamo creato la pipeline RAG con entrambi i moduli Ingestion e QnA. Abbiamo testato entrambe le pipeline utilizzando alcuni documenti e funzionavano perfettamente. Ora dobbiamo avvolgere la pipeline con FastAPI per creare un'API consumabile. Questo ci aiuterà a integrarla con qualsiasi applicazione front-end come Streamlit, Chainlit, Gradio, Reflex, React, Angular ecc. Iniziamo creando una struttura per l'applicazione. Seguire la struttura è completamente facoltativo, ma assicurati di controllare le importazioni di dipendenza se segui una struttura diversa per creare l'app.
Di seguito è riportata la struttura ad albero che seguiremo:
backend
├── app.py
├── requirements.txt
└── src
├── config.py
├── doc_loader
│ ├── base_loader.py
│ ├── __init__.py
│ └── pdf_loader.py
├── ingestion.py
├── __init__.py
└── qna.pyCominciamo con config.py. Questo file conterrà tutte le opzioni configurabili per l'applicazione, come l'URL Ollama, il nome LLM e il nome del modello di incorporamento. Di seguito un esempio:
LANGUAGE_MODEL_NAME = "phi3"
EMBEDDINGS_MODEL_NAME = "nomic-embed-text"
OLLAMA_URL = "http://localhost:11434"Il file base_loader.py contiene la classe del caricatore di documenti padre che verrà ereditata dal caricatore di documenti figlio. In questa applicazione stiamo lavorando solo con file PDF, quindi una classe PDFLoader figlio sarà
creato che erediterà la classe BaseLoader.
Di seguito sono riportati i contenuti di base_loader.py e pdf_loader.py:
# base_loader.py
from abc import ABC, abstractmethod
class BaseLoader(ABC):
def __init__(self, file_path: str) -> None:
self.file_path = file_path
@abstractmethod
async def load_document(self):
pass
# pdf_loader.py
import os
from .base_loader import BaseLoader
from langchain.schema import Document
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.text_splitter import CharacterTextSplitter
class PDFLoader(BaseLoader):
def __init__(self, file_path: str) -> None:
super().__init__(file_path)
async def load_document(self):
self.file_name = os.path.basename(self.file_path)
loader = PyMuPDFLoader(file_path=self.file_path)
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
)
pages = await loader.aload()
total_pages = len(pages)
chunks = ()
for idx, page in enumerate(pages):
chunks.append(
Document(
page_content=page.page_content,
metadata=dict(
{
"file_name": self.file_name,
"page_no": str(idx + 1),
"total_pages": str(total_pages),
}
),
)
)
final_chunks = text_splitter.split_documents(chunks)
return final_chunksAbbiamo discusso il funzionamento di pdf_loader in Parte 1 dell'articolo.
Ora, creiamo la classe Ingestion. È la stessa che abbiamo creato nella Parte 1 di questo articolo.
Codice per la classe di ingestione
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from .doc_loader import PDFLoader
class Ingestion:
"""Document Ingestion pipeline."""
def __init__(self):
try:
self.embeddings = OllamaEmbeddings(
model=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.vector_store = DeepLake(
dataset_path="data/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
except Exception as e:
raise RuntimeError(f"Failed to initialize Ingestion system. ERROR: {e}")
async def create_and_add_embeddings(
self,
file: str,
):
try:
loader = PDFLoader(
file_path=file,
)
chunks = await loader.load_document()
size = await self.vector_store.aadd_documents(documents=chunks)
return len(size)
except (ValueError, RuntimeError, KeyError, TypeError) as e:
raise Exception(f"ERROR: {e}")Ora che abbiamo impostato la classe Ingestion, andremo avanti con la creazione della classe QnA. Anche questa è uguale a quella che abbiamo creato nella Parte 1 di questo articolo.
Codice per la classe QnA
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from langchain_community.llms.ollama import Ollama
from .doc_loader import PDFLoader
class QnA:
"""Document Ingestion pipeline."""
def __init__(self):
try:
self.embeddings = OllamaEmbeddings(
model=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.model = Ollama(
model=cfg.LANGUAGE_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
verbose=True,
temperature=0.2,
)
self.vector_store = DeepLake(
dataset_path="data/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
self.retriever = self.vector_store.as_retriever(
search_type="similarity",
search_kwargs={
"k": 10,
},
)
except Exception as e:
raise RuntimeError(f"Failed to initialize Ingestion system. ERROR: {e}")
def create_rag_chain(self):
try:
system_prompt = """\n\nContext: {context}"
"""
prompt = ChatPromptTemplate.from_messages(
(
("system", system_prompt),
("human", "{input}"),
)
)
question_answer_chain = create_stuff_documents_chain(self.model, prompt)
rag_chain = create_retrieval_chain(self.retriever, question_answer_chain)
return rag_chain
except Exception as e:
raise RuntimeError(f"Failed to create retrieval chain. ERROR: {e}")Con questo abbiamo finito di creare le funzionalità del codice dell'app RAG. Ora avvolgiamo l'app con FastAPI.
Codice per l'applicazione FastAPI
import sys
import os
import uvicorn
from src import QnA, Ingestion
from fastapi import FastAPI, Request, File, UploadFile
from fastapi.responses import StreamingResponse
app = FastAPI()
ingestion = Ingestion()
chatbot = QnA()
rag_chain = chatbot.create_rag_chain()
@app.get("https://www.analyticsvidhya.com/")
def hello():
return {"message": "API Running in server 8089"}
@app.post("/query")
async def ask_query(request: Request):
data = await request.json()
question = data.get("question")
async def event_generator():
for chunk in rag_chain.pick("answer").stream({"input": question}):
yield chunk
return StreamingResponse(event_generator(), media_type="text/plain")
@app.post("/ingest")
async def ingest_document(file: UploadFile = File(...)):
try:
os.makedirs("files", exist_ok=True)
file_location = f"files/{file.filename}"
with open(file_location, "wb+") as file_object:
file_object.write(file.file.read())
size = await ingestion.create_and_add_embeddings(file=file_location)
return {"message": f"File ingested! Document count: {size}"}
except Exception as e:
return {"message": f"An error occured: {e}"}
if __name__ == "__main__":
try:
uvicorn.run(app, host="0.0.0.0", port=8089)
except KeyboardInterrupt as e:
print("App stopped!")Analizziamo l'app in base a ciascun endpoint:
- Per prima cosa inizializziamo l'app FastAPI, l'Ingestion e gli oggetti QnA. Quindi creiamo una catena RAG usando il metodo create_rag_chain della classe QnA.
- Il nostro primo endpoint è un semplice metodo GET. Questo ci aiuterà a sapere se l'app è sana o meno. Pensalo come un endpoint 'Hello World'.
- Il secondo è l'endpoint della query. Questo è un metodo POST e verrà utilizzato per eseguire la catena. Accetta un parametro di richiesta, da cui estraiamo la query dell'utente. Quindi creiamo un metodo asincrono che funge da wrapper asincrono attorno alla chiamata di funzione chain.stream. Dobbiamo farlo per consentire a FastAPI di gestire la chiamata di funzione stream dell'LLM, per ottenere un'esperienza simile a ChatGPT nell'interfaccia della chat. Quindi avvolgiamo il metodo asincrono con la classe StreamingResponse e lo restituiamo.
- Il terzo endpoint è l'endpoint di ingestione. È anche un metodo POST che accetta l'intero file come byte come input. Memorizziamo questo file nella directory locale e poi lo ingeriamo usando il metodo create_and_add_embeddings della classe Ingestion.
Infine, eseguiamo l'app usando il pacchetto uvicorn, usando host e porta. Per testare l'app, esegui semplicemente l'applicazione usando il seguente comando:
python app.py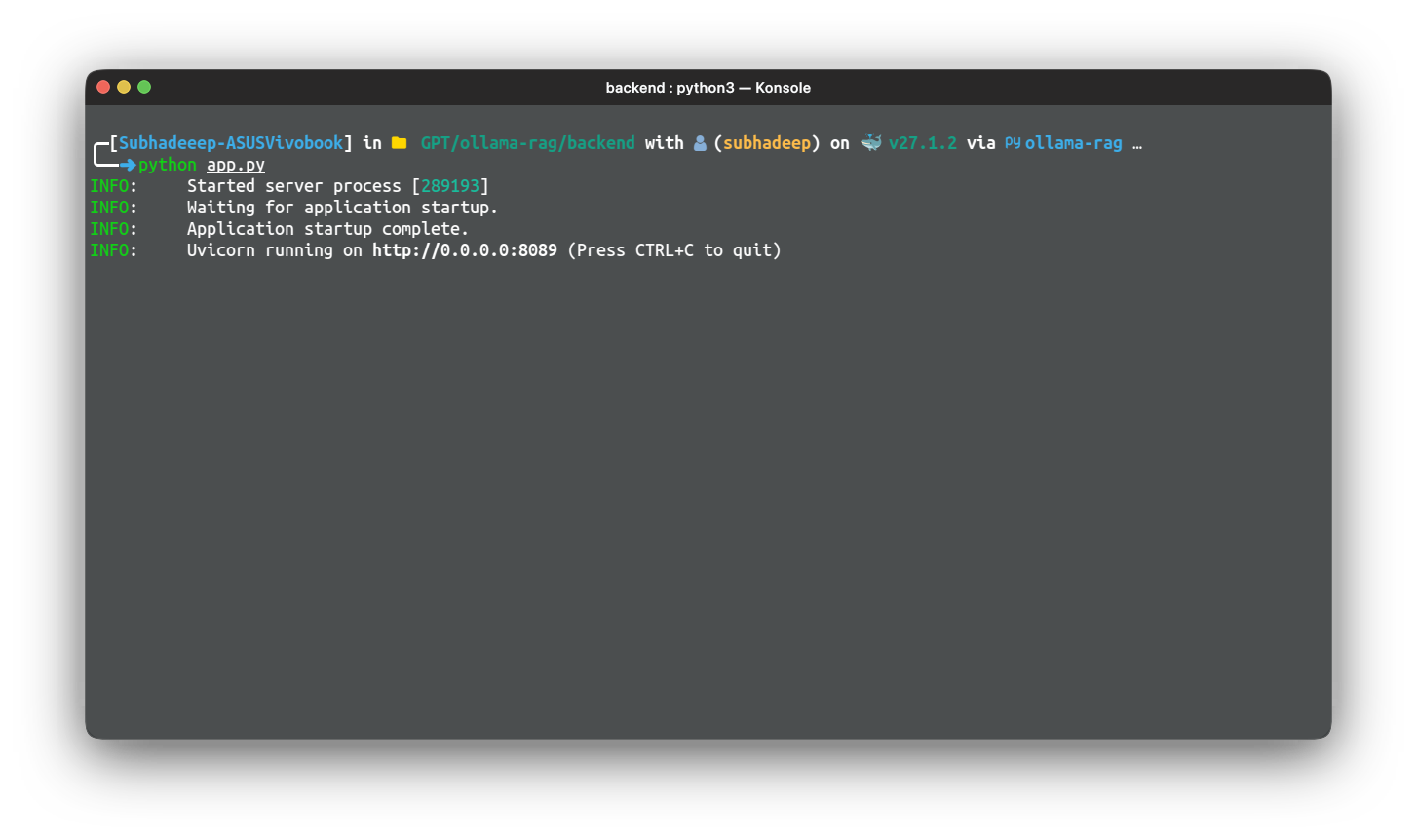
Utilizza un IDE di test API come Postman, Insomnia o Bruno per testare l'applicazione. Puoi anche usare l'estensione Thunder Client per fare lo stesso.
Test dell'endpoint di ingestione:
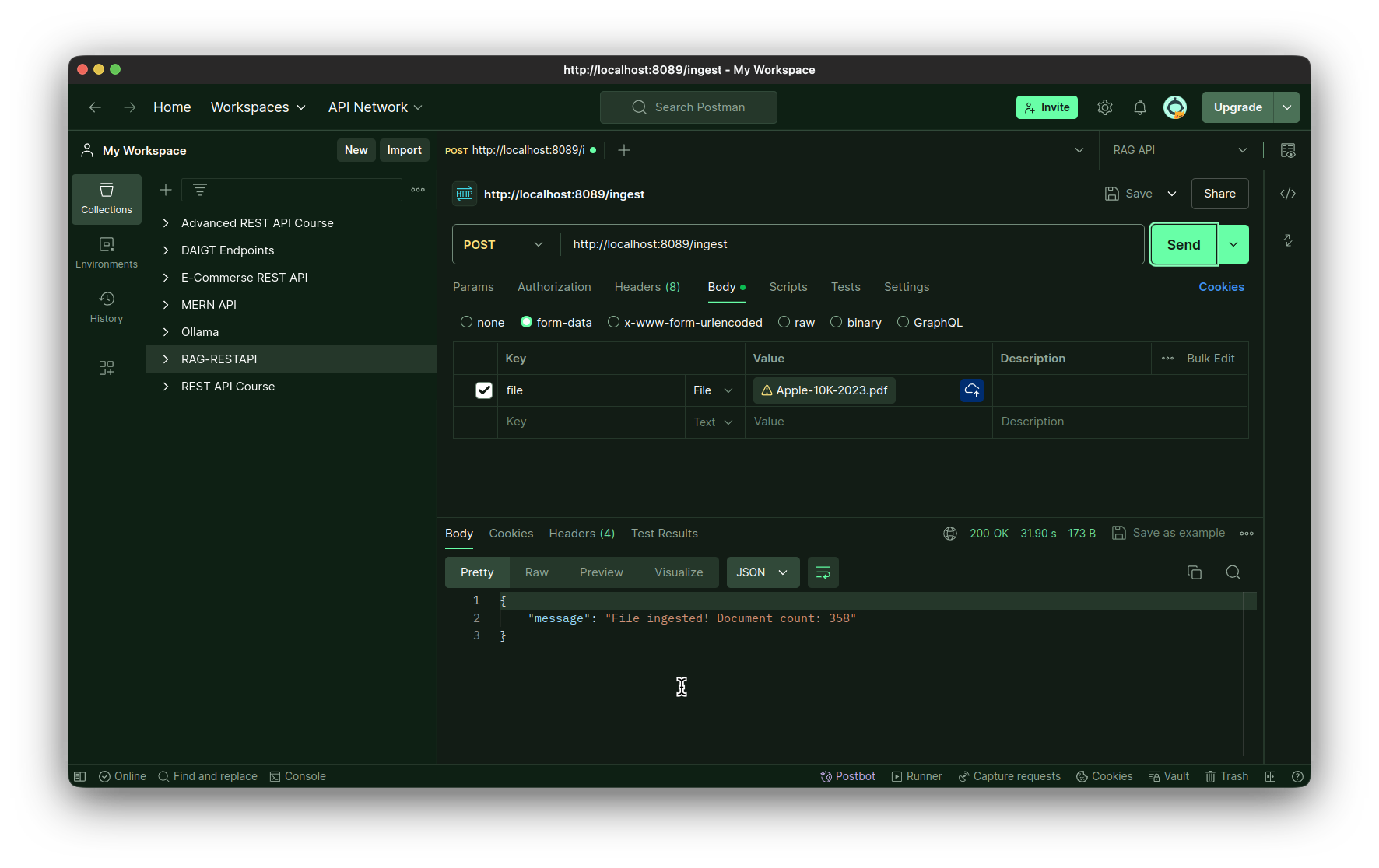
Test dell'endpoint della query:
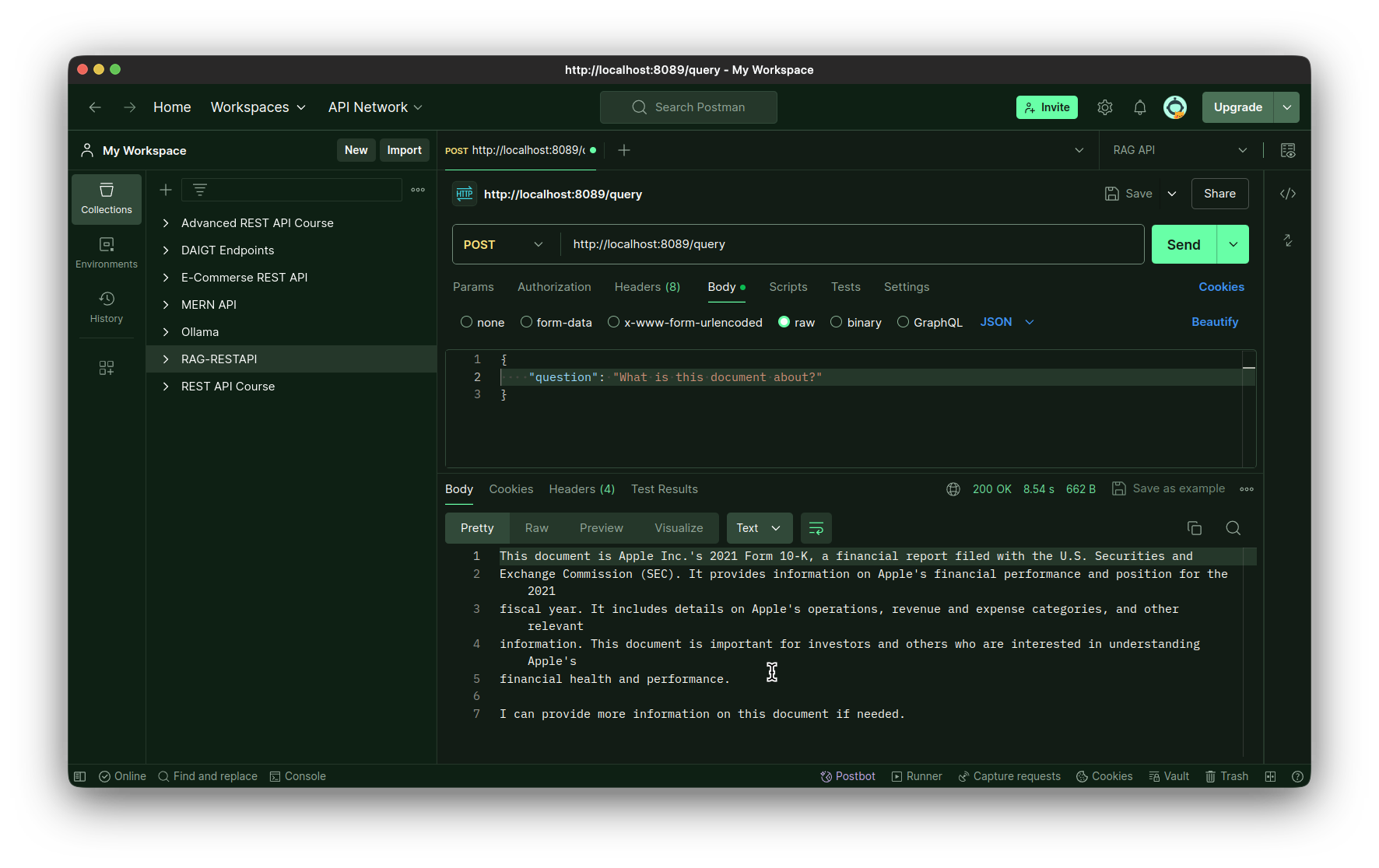
Progettare il Front-End con Reflex
Abbiamo creato con successo un'app FastAPI per il backend della nostra applicazione RAG. È il momento di creare il nostro front-end. Puoi scegliere qualsiasi libreria front-end per questo, ma per questo articolo specifico creeremo il front-end usando Reflex. Reflex è una libreria front-end solo python, creata per creare applicazioni web, usando esclusivamente python. Ci dimostra con modelli per applicazioni comuni come calcolatrice, generazione di immagini e chatbot. Useremo il modello di applicazione chatbot come punto di partenza per la nostra interfaccia utente. La nostra app finale avrà la seguente struttura, quindi teniamola qui come riferimento.
Directory di Frontend
Per questo avremo una directory frontend:
frontend
├── assets
│ └── favicon.ico
├── docs
│ └── demo.gif
├── chat
│ ├── components
│ │ ├── chat.py
│ │ ├── file_upload.py
│ │ ├── __init__.py
│ │ ├── loading_icon.py
│ │ ├── modal.py
│ │ └── navbar.py
│ ├── __init__.py
│ ├── chat.py
│ └── state.py
├── requirements.txt
├── rxconfig.py
└── uploaded_filesPassaggi per l'app finale
Seguire i passaggi per preparare la messa a terra per l'app finale.
Passaggio 1: clonare il repository dei modelli di chat nella directory frontend
git clone https://github.com/reflex-dev/reflex-chat.git .Passaggio 2: eseguire il seguente comando per inizializzare la directory come app reflex
reflex init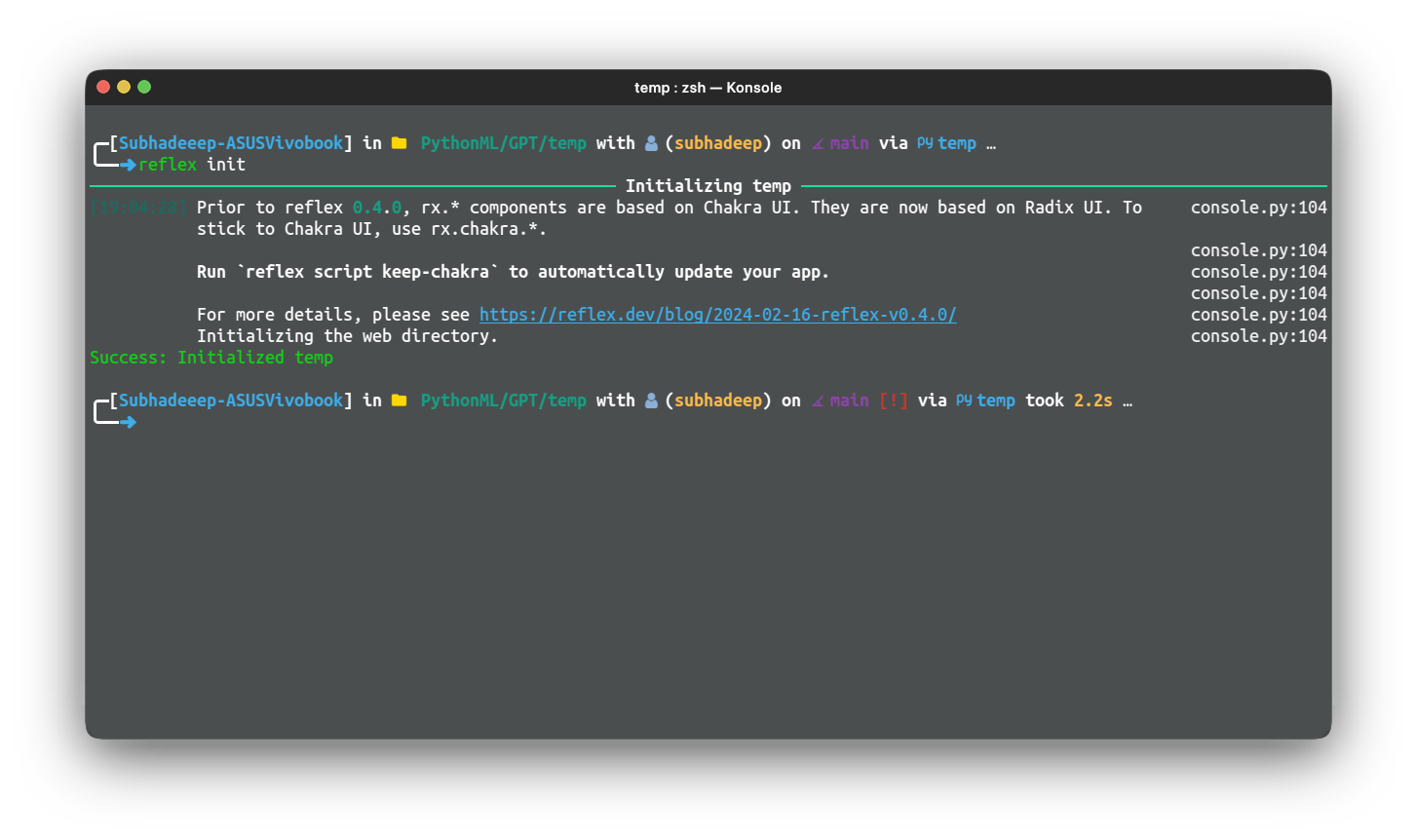
In questo modo verrà configurata l'app Reflex, che sarà pronta per essere eseguita e sviluppata.
Passaggio 3: testare l'app, utilizzare il seguente comando dall'interno della directory frontend
reflex run
Cominciamo a modificare i componenti. Per prima cosa modifichiamo il file chat.py.
Di seguito è riportato il codice per lo stesso:
import reflex as rx
from reflex_demo.components import loading_icon
from reflex_demo.state import QA, State
message_style = dict(
display="inline-block",
padding="0 10px",
border_radius="8px",
max_width=("30em", "30em", "50em", "50em", "50em", "50em"),
)
def message(qa: QA) -> rx.Component:
"""A single question/answer message.
Args:
qa: The question/answer pair.
Returns:
A component displaying the question/answer pair.
"""
return rx.box(
rx.box(
rx.markdown(
qa.question,
background_color=rx.color("mauve", 4),
color=rx.color("mauve", 12),
**message_style,
),
text_align="right",
margin_top="1em",
),
rx.box(
rx.markdown(
qa.answer,
background_color=rx.color("accent", 4),
color=rx.color("accent", 12),
**message_style,
),
text_align="left",
padding_top="1em",
),
width="100%",
)
def chat() -> rx.Component:
"""List all the messages in a single conversation."""
return rx.vstack(
rx.box(rx.foreach(State.chats(State.current_chat), message), width="100%"),
py="8",
flex="1",
width="100%",
max_width="50em",
padding_x="4px",
align_self="center",
overflow="hidden",
padding_bottom="5em",
)
def action_bar() -> rx.Component:
"""The action bar to send a new message."""
return rx.center(
rx.vstack(
rx.chakra.form(
rx.chakra.form_control(
rx.hstack(
rx.input(
rx.input.slot(
rx.tooltip(
rx.icon("info", size=18),
content="Enter a question to get a response.",
)
),
placeholder="Type something...",
id="question",
width=("15em", "20em", "45em", "50em", "50em", "50em"),
),
rx.button(
rx.cond(
State.processing,
loading_icon(height="1em"),
rx.text("Send", font_family="Ubuntu"),
),
type="submit",
),
align_items="center",
),
is_disabled=State.processing,
),
on_submit=State.process_question,
reset_on_submit=True,
),
rx.text(
"ReflexGPT may return factually incorrect or misleading responses. Use discretion.",
text_align="center",
font_size=".75em",
color=rx.color("mauve", 10),
font_family="Ubuntu",
),
rx.logo(margin_top="-1em", margin_bottom="-1em"),
align_items="center",
),
position="sticky",
bottom="0",
left="0",
padding_y="16px",
backdrop_filter="auto",
backdrop_blur="lg",
border_top=f"1px solid {rx.color('mauve', 3)}",
background_color=rx.color("mauve", 2),
align_items="stretch",
width="100%",
)Le modifiche sono minime rispetto a quelle presenti nativamente nel modello.
Successivamente, modificheremo l'app chat.py. Questo è il componente principale della chat.
Codice per il componente principale della chat
Di seguito il codice:
import reflex as rx
from reflex_demo.components import chat, navbar, upload_form
from reflex_demo.state import State
@rx.page(route="/chat", title="RAG Chatbot")
def chat_interface() -> rx.Component:
return rx.chakra.vstack(
navbar(),
chat.chat(),
chat.action_bar(),
background_color=rx.color("mauve", 1),
color=rx.color("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
@rx.page(route="https://www.analyticsvidhya.com/", title="RAG Chatbot")
def index() -> rx.Component:
return rx.chakra.vstack(
navbar(),
upload_form(),
background_color=rx.color("mauve", 1),
color=rx.color("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
# Add state and page to the app.
app = rx.App(
theme=rx.theme(
appearance="dark",
accent_color="jade",
),
stylesheets=("https://fonts.googleapis.com/css2?family=Ubuntu&display=swap"),
style={
"font_family": "Ubuntu",
},
)
app.add_page(index)
app.add_page(chat_interface)Questo è il codice per l'interfaccia della chat. Abbiamo aggiunto solo la famiglia Font alla configurazione dell'app, il resto del codice è lo stesso.
Ora modifichiamo il file state.py. Qui è dove il frontend chiamerà gli endpoint API per la risposta.
Modifica del file state.py
import requests
import reflex as rx
class QA(rx.Base):
question: str
answer: str
DEFAULT_CHATS = {
"Intros": (),
}
class State(rx.State):
chats: dict(str, list(QA)) = DEFAULT_CHATS
current_chat = "Intros"
url: str = "http://localhost:8089/query"
question: str
processing: bool = False
new_chat_name: str = ""
def create_chat(self):
"""Create a new chat."""
# Add the new chat to the list of chats.
self.current_chat = self.new_chat_name
self.chats(self.new_chat_name) = ()
def delete_chat(self):
"""Delete the current chat."""
del self.chats(self.current_chat)
if len(self.chats) == 0:
self.chats = DEFAULT_CHATS
self.current_chat = list(self.chats.keys())(0)
def set_chat(self, chat_name: str):
"""Set the name of the current chat.
Args:
chat_name: The name of the chat.
"""
self.current_chat = chat_name
@rx.var
def chat_titles(self) -> list(str):
"""Get the list of chat titles.
Returns:
The list of chat names.
"""
return list(self.chats.keys())
async def process_question(self, form_data: dict(str, str)):
# Get the question from the form
question = form_data("question")
# Check if the question is empty
if question == "":
return
model = self.openai_process_question
async for value in model(question):
yield value
async def openai_process_question(self, question: str):
"""Get the response from the API.
Args:
form_data: A dict with the current question.
"""
# Add the question to the list of questions.
qa = QA(question=question, answer="")
self.chats(self.current_chat).append(qa)
payload = {"question": question}
# Clear the input and start the processing.
self.processing = True
yield
response = requests.post(self.url, json=payload, stream=True)
# Stream the results, yielding after every word.
for answer_text in response.iter_content(chunk_size=512):
# Ensure answer_text is not None before concatenation
answer_text = answer_text.decode()
if answer_text is not None:
self.chats(self.current_chat)(-1).answer += answer_text
else:
answer_text = ""
self.chats(self.current_chat)(-1).answer += answer_text
self.chats = self.chats
yield
# Toggle the processing flag.
self.processing = FalseIn questo file abbiamo definito l'URL per l'endpoint della query. Abbiamo anche modificato il metodo openai_process_question per inviare una richiesta POST all'endpoint della query e ottenere lo streaming
risposta, che verrà visualizzata nell'interfaccia della chat.
Scrittura del contenuto del file file_upload.py
Infine, scriviamo il contenuto del file file_upload.py. Questo componente verrà visualizzato all'inizio e ci consentirà di caricare il file per l'ingestione.
import reflex as rx
import os
import time
import requests
class UploadExample(rx.State):
uploading: bool = False
ingesting: bool = False
progress: int = 0
total_bytes: int = 0
ingestion_url = "http://127.0.0.1:8089/ingest"
async def handle_upload(self, files: list(rx.UploadFile)):
self.ingesting = True
yield
for file in files:
file_bytes = await file.read()
file_name = file.filename
files = {
"file": (os.path.basename(file_name), file_bytes, "multipart/form-data")
}
response = requests.post(self.ingestion_url, files=files)
self.ingesting = False
yield
if response.status_code == 200:
# yield rx.redirect("/chat")
self.show_redirect_popup()
def handle_upload_progress(self, progress: dict):
self.uploading = True
self.progress = round(progress("progress") * 100)
if self.progress >= 100:
self.uploading = False
def cancel_upload(self):
self.uploading = False
return rx.cancel_upload("upload3")
def upload_form():
return rx.vstack(
rx.upload(
rx.flex(
rx.text(
"Drag and drop file here or click to select file",
font_family="Ubuntu",
),
rx.icon("upload", size=30),
direction="column",
align="center",
),
id="upload3",
border="1px solid rgb(233, 233,233, 0.4)",
margin="5em 0 10px 0",
background_color="rgb(107,99,246)",
border_radius="8px",
padding="1em",
),
rx.vstack(rx.foreach(rx.selected_files("upload3"), rx.text)),
rx.cond(
~UploadExample.ingesting,
rx.button(
"Upload",
on_click=UploadExample.handle_upload(
rx.upload_files(
upload_id="upload3",
on_upload_progress=UploadExample.handle_upload_progress,
),
),
),
rx.flex(
rx.spinner(size="3", loading=UploadExample.ingesting),
rx.button(
"Cancel",
on_click=UploadExample.cancel_upload,
),
align="center",
spacing="3",
),
),
rx.alert_dialog.root(
rx.alert_dialog.trigger(
rx.button("Continue to Chat", color_scheme="green"),
),
rx.alert_dialog.content(
rx.alert_dialog.title("Redirect to Chat Interface?"),
rx.alert_dialog.description(
"You will be redirected to the Chat Interface.",
size="2",
),
rx.flex(
rx.alert_dialog.cancel(
rx.button(
"Cancel",
variant="soft",
color_scheme="gray",
),
),
rx.alert_dialog.action(
rx.button(
"Continue",
color_scheme="green",
variant="solid",
on_click=rx.redirect("/chat"),
),
),
spacing="3",
margin_top="16px",
justify="end",
),
style={"max_width": 450},
),
),
align="center",
)Questo componente ci consentirà di caricare un file e di ingerirlo nello store vettoriale. Utilizza l'endpoint di ingestione della nostra app FastAPI per caricare e ingerire il file. Dopo l'ingestione, l'utente può semplicemente spostare
all'interfaccia della chat per porre domande.
Con questo abbiamo completato la creazione del front-end per la nostra applicazione. Ora dovremo testare l'applicazione usando un documento.
Test e distribuzione
Ora testiamo l'applicazione su alcuni manuali o documenti. Per utilizzare l'applicazione, dobbiamo eseguire separatamente sia l'app back-end che l'app reflex. Esegui l'app back-end dalla sua directory utilizzando
seguente comando:
python app.pyAttendi che FastAPI inizi a funzionare. Quindi, in un'altra istanza del terminale, esegui l'app front-end utilizzando il seguente comando:
reflex runUna volta che le app sono attive e funzionanti, vai a seguente URL per accedere all'app reflex. Inizialmente saremmo nella pagina Caricamento file. Carica un file e premi il pulsante di caricamento.
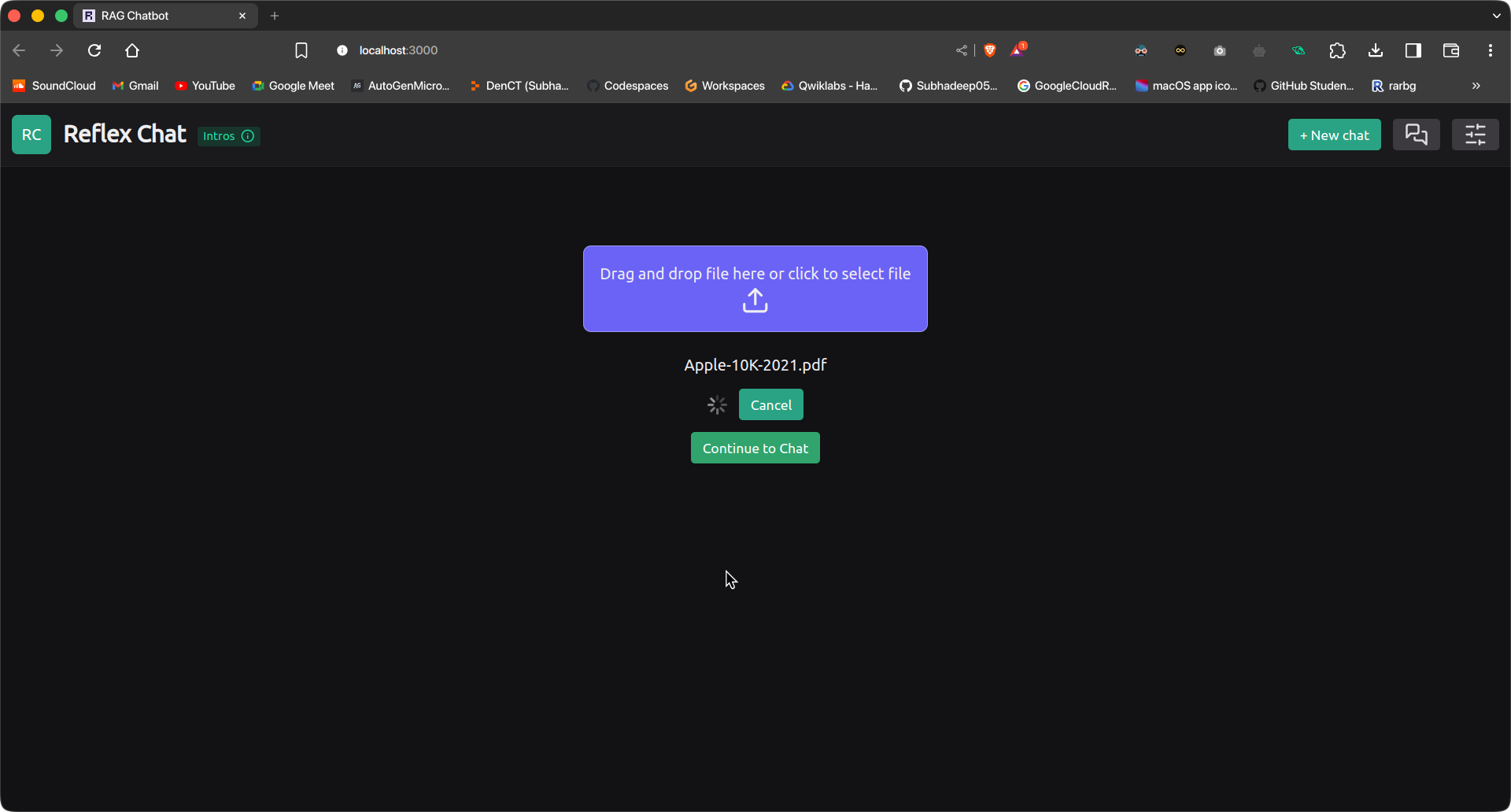
Il file verrà caricato e ingerito. Ciò richiederà un po' di tempo, a seconda delle dimensioni del documento e
le specifiche del dispositivo. Una volta fatto, clicca sul pulsante “Continua a chattare” per passare all'interfaccia della chat. Scrivi la tua query e premi Invia.
Conclusione
In questa serie in due parti, hai creato un'applicazione RAG completa e funzionale su un Raspberry Pi, dalla creazione della pipeline principale al suo confezionamento con un back-end FastAPI e allo sviluppo di un front-end basato su Reflex. Con questi strumenti, la tua pipeline RAG è accessibile e interattiva, fornendo elaborazione delle query in tempo reale tramite un'interfaccia web intuitiva. Padroneggiando questi passaggi, hai acquisito una preziosa esperienza nella creazione e distribuzione di applicazioni end-to-end su una piattaforma compatta ed efficiente. Questa configurazione apre le porte a innumerevoli possibilità per la distribuzione di applicazioni basate sull'intelligenza artificiale su dispositivi con risorse limitate come il Raspberry Pi, rendendo la tecnologia all'avanguardia più accessibile e pratica per l'uso quotidiano.
Punti chiave
- Viene fornita una guida dettagliata sulla configurazione dell'ambiente di sviluppo, inclusa l'installazione delle dipendenze e dei modelli necessari tramite Ollama, per garantire che l'applicazione sia pronta per la build finale.
- L'articolo spiega come integrare la pipeline RAG in un'applicazione FastAPI, inclusa la configurazione degli endpoint per l'interrogazione del modello e l'acquisizione di documenti, rendendo la pipeline accessibile tramite un'API Web.
- Il front-end dell'applicazione RAG è costruito usando Reflex, una libreria front-end solo Python. L'articolo mostra come modificare il modello dell'applicazione chat per creare un'interfaccia user-friendly per interagire con la pipeline RAG.
- L'articolo illustra come integrare il backend FastAPI con il front-end Reflex e come distribuire l'applicazione completa su un Raspberry Pi, garantendo un funzionamento fluido e l'accessibilità da parte dell'utente.
- Vengono forniti passaggi pratici per testare sia gli endpoint di ingestione che quelli di query utilizzando strumenti come Postman o Thunder Client, oltre all'esecuzione e al test del front-end Reflex per garantire che l'intera applicazione funzioni come previsto.
Domande frequenti
A. Esiste una piattaforma chiamata Tailscale che consente ai tuoi dispositivi di essere connessi a una rete privata sicura, accessibile solo a te. Puoi aggiungere il tuo Raspberry Pi e altri dispositivi ai dispositivi Tailscale e connetterti alla VPN per accedere alle tue app, da qualsiasi parte del mondo.
A. Questo è il vincolo dovuto alle basse specifiche hardware del Raspberry Pi. L'articolo è solo un tutorial di approfondimento su come iniziare a creare un'app RAG usando Raspberry Pi e Ollama.
I contenuti multimediali mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
Fonte: www.analyticsvidhya.com

