
Sfide di rilevamento delle allucinazioni LLM e una possibile soluzione presentate in un importante documento di ricerca

Recentemente, i modelli linguistici di grandi dimensioni (LLM) hanno mostrato capacità impressionanti e crescenti, inclusa la generazione di risposte altamente fluenti e convincenti ai suggerimenti degli utenti. Tuttavia, gli LLM sono noti per la loro capacità di generare affermazioni non reali o prive di senso, più comunemente note come “allucinazioni”. Questa caratteristica può minare la fiducia in molti scenari in cui è richiesta la fattualità, come attività di riepilogo, risposte generative alle domande e generazioni di dialoghi.
Rilevare le allucinazioni è sempre stato difficile tra gli esseri umani, il che rimane vero nel contesto dei LLM. Ciò è particolarmente impegnativo, considerando che di solito non abbiamo accesso al contesto di verità per i controlli di coerenza. Ulteriori informazioni sulle generazioni del LLM, come le distribuzioni di probabilità di output, possono aiutare in questo compito. Tuttavia, spesso accade che questo tipo di informazioni non sia disponibile, rendendo il compito ancora più difficile.
Il rilevamento delle allucinazioni deve ancora essere risolto ed è un’area di ricerca attiva. In questo post del blog presenteremo l’attività in generale, le sue sfide e un possibile approccio pubblicato nel documento di ricerca SELFCHECKGPT: rilevamento di allucinazioni con scatola nera a risorse zero per modelli linguistici generativi di grandi dimensioni(1). Illustreremo alcuni degli approcci presentati nel documento con esempi reali, sottolineando alcuni pro e contro di ciascun metodo. Puoi rivedere tu stesso gli esempi andando a questo Taccuino di Google Colab.
Questo blog tratterà:
- Cos’è l’allucinazione LLM
- L’approccio: SelfCheckGPT
- Controllo di coerenza
1. Punteggio BERTS
2. Inferenza del linguaggio naturale
3. Richiesta LLM - Esperimenti
- Conclusione
- Riferimenti
Cos’è l’allucinazione LLM
Nella generazione del linguaggio naturale, l’allucinazione può essere definita come “contenuto generato privo di senso o infedele al contenuto sorgente fornito”(2). Il contenuto di origine può rappresentare diverse funzioni per diverse attività. Ad esempio, per i compiti di riepilogo, la fonte è il testo di input da riassumere, mentre per i compiti di risposta a domande generative, la fonte è considerata la conoscenza del mondo(2). Concentriamoci sull’attività di risposta alle domande e diamo un’occhiata a un esempio di domanda dell’utente e alla risposta fornita dal modello GPT di OpenAI (text-davinci-003):
Richiesta utente: Chi era Philip Hayworth?
Risposta LLM: Philip Hayworth era un avvocato e politico inglese che prestò servizio come membro del Parlamento per Thetford dal 1859 al 1868.
A prima vista sembra una risposta coerente, ma dopo un po’ potremmo porci una domanda molto ragionevole: è vero?
Tuttavia, non abbiamo molte informazioni per rispondere alla nostra nuova domanda. Non abbiamo un contesto con fatti provati che possiamo utilizzare per verificare l’affermazione. I LLM vengono generalmente formati sulla base di enormi corpora di testi e può essere difficile verificare se l’affermazione è fondata su una particolare fonte di informazioni. Una rapida ricerca su Google non mostra alcun risultato per una persona che corrisponde alla risposta. Ciò che costituisce esattamente un’allucinazione non è ancora ben stabilito, ma questo esempio potrebbe essere comprensibilmente considerato un’allucinazione perché il soggetto con questo nome, luogo e impiego potrebbe non essere affatto esistito.
Proviamo di nuovo con un’altra domanda:
Richiesta utente: Chi è Bill Gates?
Risposta LLM: Bill Gates è un imprenditore tecnologico, investitore e filantropo. È il co-fondatore di Microsoft Corporation ed è una delle persone più ricche del mondo.
Ok, queste affermazioni sono molto più facili da verificare e sono supportate da un rapido controllo su Wikipedia, quindi difficilmente si tratta di un’allucinazione. Durante la formazione, è molto probabile che LLM abbia visto molte dichiarazioni su Bill Gates, quindi i seguenti token dopo “Bill Gates è _” verranno probabilmente generati con elevata sicurezza. D’altra parte, il LLM potrebbe non essere sicuro di quali parole utilizzare dopo “Philip Hayworth è _”. Questa intuizione ci consente di collegare l’incertezza con la fattualità, poiché le frasi basate sui fatti conterranno probabilmente token predetti con una probabilità maggiore rispetto alle frasi allucinate. Tuttavia, potremmo non avere a portata di mano la distribuzione della probabilità di output per un buon numero di casi.
L’esempio e il contenuto della sessione attuale si basavano sul documento originale (1) e continueremo a esplorare l’approccio del documento nelle sezioni seguenti.
L’approccio: SelfCheckGPT
Nell’ultima sezione abbiamo considerato due considerazioni importanti per il nostro approccio: l’accesso a un contesto esterno e l’accesso alla distribuzione di probabilità di output del LLM. Quando un metodo non richiede un contesto o un database esterno per eseguire il controllo di coerenza, possiamo chiamarlo a a risorse zero metodo. Allo stesso modo, quando un metodo richiede solo il testo generato da LLM, può essere chiamato a scatola nera metodo.
L’approccio di cui vogliamo parlare in questo post del blog è un metodo di rilevamento delle allucinazioni a scatola nera a risorse zero e si basa sulla premessa che le risposte campionate allo stesso suggerimento probabilmente divergeranno e si contraddiranno a vicenda per i fatti allucinatori, e saranno probabilmente simili e coerenti tra loro per le affermazioni fattuali.
Rivisitiamo gli esempi precedenti. Per applicare il metodo di rilevamento, abbiamo bisogno di più campioni, quindi poniamo al LLM la stessa domanda altre tre volte:

In effetti, le risposte si contraddicono a vicenda: a volte Philip Hayworth è un politico britannico e in altri casi è un ingegnere australiano o un avvocato americano, che hanno vissuto e agito in periodi diversi.
Facciamo un confronto con l’esempio di Bill Gates:

Possiamo osservare che le occupazioni, le organizzazioni e i tratti assegnati a Bill Gates sono coerenti tra i campioni, con l’utilizzo di termini uguali o semanticamente simili.
Controllo di coerenza
Ora che abbiamo più campioni, il passaggio finale è eseguire un controllo di coerenza, un modo per determinare se le risposte concordano tra loro. Questo può essere fatto in diversi modi, quindi esploriamo alcuni approcci presentati nel documento. Sentiti libero di eseguire tu stesso il codice controllando questo Taccuino di Google Colab.
Punteggio BERTS
Un approccio intuitivo per eseguire questo controllo consiste nel misurare la somiglianza semantica tra i campioni e BERTScore(3) è un modo per farlo. BERTScore calcola un punteggio di somiglianza per ciascun token nella frase candidata con ciascun token nella frase di riferimento per calcolare un punteggio di somiglianza tra le frasi.
Nel contesto di SelfCheckGPT, il punteggio viene calcolato per frase. Ciascuna frase della risposta originale verrà confrontata con ciascuna frase di un dato campione per trovare la frase più simile. Di questi punteggi massimi di somiglianza verrà calcolata la media tra tutti i campioni, risultando in un punteggio finale di allucinazione per ciascuna frase nella risposta originale. Il punteggio finale deve tendere a 1 per frasi dissimili e a 0 per frasi simili, quindi dobbiamo sottrarre il punteggio di somiglianza da 1.
Mostriamo come funziona confrontando la prima frase della nostra risposta originale con il primo campione:

Il punteggio massimo per il primo campione è 0,69. Ripetendo il processo per i due campioni rimanenti e assumendo che gli altri punteggi massimi fossero 0,72 e 0,72, il nostro punteggio finale per questa frase sarebbe 1 — (0,69+0,72+0,72)/3 = 0,29.
Usare la somiglianza semantica per verificare la coerenza è un approccio intuitivo. È possibile utilizzare altri codificatori per incorporare rappresentazioni, quindi anche questo è un approccio che può essere ulteriormente esplorato.
Inferenza del linguaggio naturale
L’inferenza del linguaggio naturale ha il compito di determinare l’implicazione, cioè se un’ipotesi è vera, falsa o indeterminata sulla base di una premessa(4). Nel nostro caso, ogni campione viene utilizzato come premessa e ogni frase della risposta originale viene utilizzata come ipotesi. Viene calcolata la media dei punteggi dei campioni per ciascuna frase per ottenere il punteggio finale. L’implicazione viene eseguita con un modello Deberta ottimizzato per il set di dati Multi-NLI(5). Utilizzeremo la probabilità di previsione normalizzata invece delle classi effettive, come “implicazione” o “contraddizione”, per calcolare i punteggi.(6)
Il compito di implicazione è più vicino al nostro obiettivo di controllo della coerenza, quindi possiamo aspettarci che un modello messo a punto per quello scopo funzioni bene. L’autore ha anche condiviso pubblicamente il modello su HuggingFacee altri modelli NLI sono disponibili al pubblico, rendendo questo approccio molto accessibile.
Richiesta LLM
Considerando che utilizziamo già LLM per generare risposte ed esempi, potremmo anche utilizzare un LLM per eseguire il controllo di coerenza. Possiamo interrogare il LLM per un controllo di coerenza per ogni frase originale e ogni campione come contesto. L’immagine seguente, tratta dal repository del documento originale, illustra come ciò avviene:
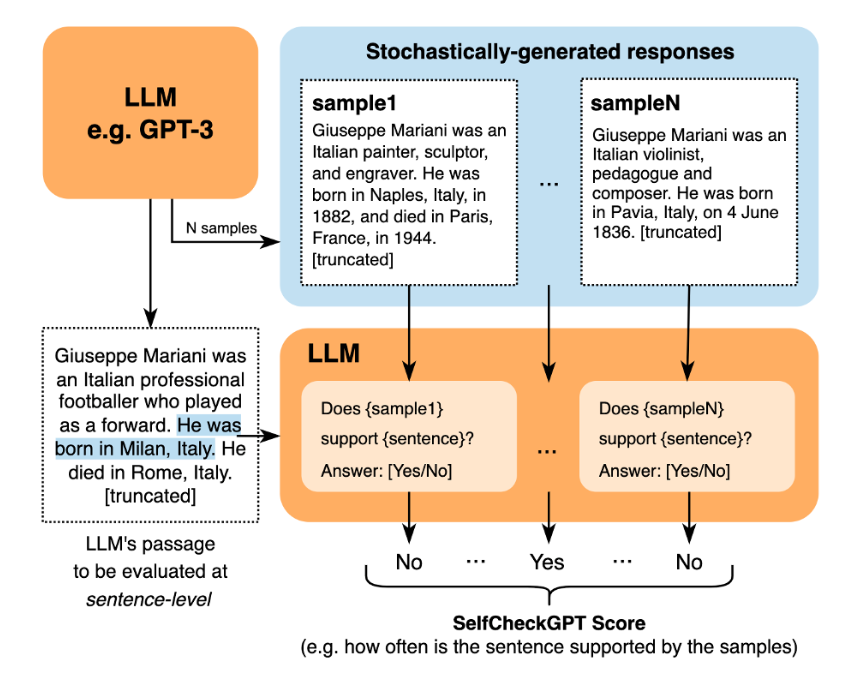
Il punteggio finale può essere calcolato assegnando 1 a “No”, 0 a “Sì”, 0,5 per N/A e calcolando la media dei valori tra i campioni.
A differenza degli altri due approcci, questo comporta chiamate aggiuntive al LLM di tua scelta, il che significa ulteriore latenza e, possibilmente, costi aggiuntivi. D’altra parte, possiamo sfruttare le capacità di LLM per aiutarci a eseguire questo controllo.
Esperimenti
Vediamo cosa otteniamo come risultati per i due esempi di cui abbiamo discusso per ciascuno dei tre approcci.
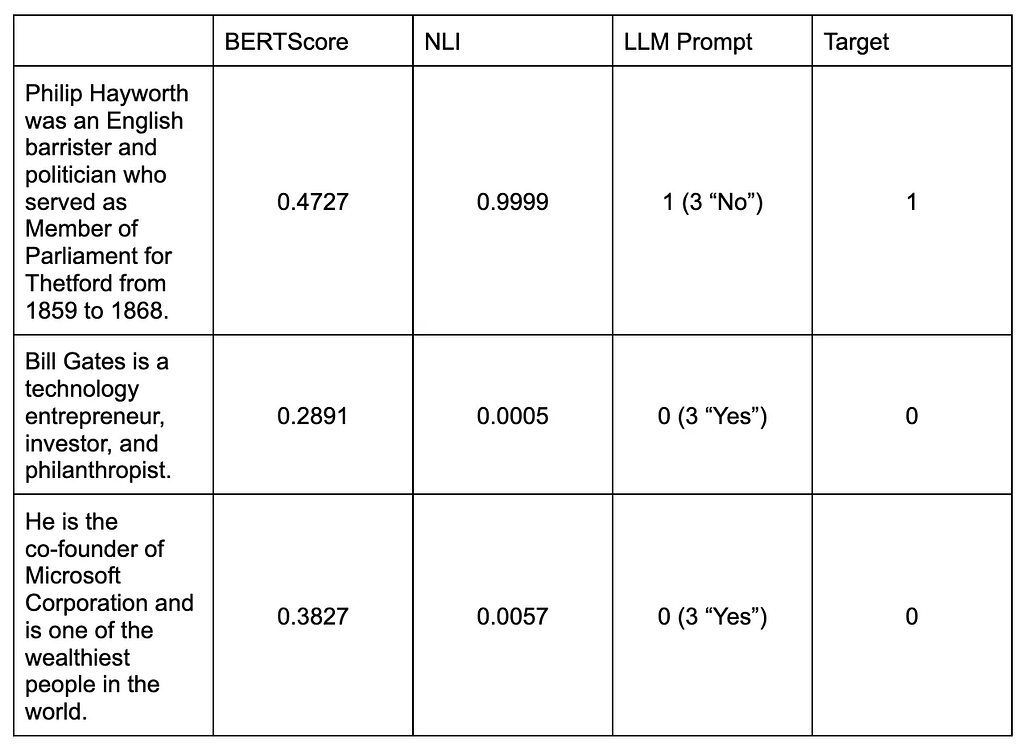
Questi valori hanno il solo scopo di illustrare il metodo. Con solo tre frasi, non dovrebbe essere un mezzo per confrontare e determinare quale sia l’approccio migliore. A tale scopo, l’articolo originale condivide i risultati sperimentali nell’archivio dell’articolo Quiche include versioni aggiuntive che non sono state discusse in questo post del blog. Non entrerò nei dettagli dei risultati, ma secondo tutti e tre i parametri (NonFact, Factual e Ranking), LLM-Prompt è la versione con le migliori prestazioni, seguita da vicino dalla versione NLI. La versione BERTScore sembra essere considerevolmente peggiore delle restanti due. I nostri semplici esempi sembrano seguire la linea dei risultati condivisi.
Conclusione
Ci auguriamo che questo post sul blog abbia contribuito a spiegare il problema delle allucinazioni e fornisca una possibile soluzione per il rilevamento delle allucinazioni. Si tratta di un problema relativamente nuovo ed è bello vedere che si stanno compiendo sforzi per risolverlo.
L’approccio discusso ha il vantaggio di non richiedere un contesto esterno (risorsa zero) e di non richiedere la distribuzione di probabilità di output del LLM (scatola nera). Tuttavia, ciò ha un costo: oltre alla risposta originale, dobbiamo generare campioni aggiuntivi per eseguire il controllo di coerenza, aumentando la latenza e i costi. Il controllo di coerenza richiederà inoltre ulteriori modelli computazionali e linguistici per codificare le risposte in incorporamenti, eseguire implicazioni testuali o interrogare il LLM, a seconda del metodo scelto.
Riferimenti
(1) — Manakul, Potsawee, Adian Liusie e Mark JF Gales. “Selfcheckgpt: rilevamento di allucinazioni in scatola nera a risorse zero per modelli linguistici generativi di grandi dimensioni.” prestampa di arXiv arXiv:2303.08896 (2023).
(2) — JI, Ziwei et al. Indagine sulle allucinazioni nella generazione del linguaggio naturale. Sondaggi informatici ACMv.55, n. 12, pag. 1–38, 2023.
(3) — ZHANG, Tianyi et al. Bertscore: valutazione della generazione di testo con bert. arXiv prestampa arXiv:1904.096752019.
(4)—https://nlpprogress.com/english/natural_lingual_inference.html
(5) — Williams, A., Nangia, N. e Bowman, SR (2017). Un corpus di sfide ad ampia copertura per la comprensione delle frasi attraverso l’inferenza. arXiv prestampa arXiv:1704.05426.
(6)—https://github.com/potsawee/selfcheckgpt/tree/main#selfcheckgpt-usage-nli
Comprendere e mitigare le allucinazioni LLM è stato originariamente pubblicato in Verso la scienza dei dati su Medium, dove le persone continuano la conversazione evidenziando e rispondendo a questa storia.
Fonte: towardsdatascience.com

