
La novità di GoT sta nella sua capacità di applicare trasformazioni a questi pensieri, perfezionando ulteriormente il processo di ragionamento. Le trasformazioni cardinali comprendono l’Aggregazione, che consente la fusione di più pensieri in un’idea consolidata; Affinamento, dove vengono eseguite iterazioni continue su un singolo pensiero per migliorarne la precisione; e Generazione, che facilita la concezione di nuovi pensieri derivanti da quelli esistenti. Tali trasformazioni, con un’enfasi sulla fusione dei percorsi di ragionamento, forniscono un punto di vista più intricato rispetto ai modelli precedenti come CoT o ToT.
Inoltre, GoT introduce una dimensione valutativa attraverso Scoring e Ranking. Ogni singolo pensiero, rappresentato da un vertice, viene sottoposto a una valutazione basata sulla sua pertinenza e qualità, facilitata da un’apposita funzione di scoring. È importante sottolineare che questa funzione contempla l’intera catena del ragionamento, assegnando punteggi che potrebbero essere contestualizzati rispetto ad altri vertici del grafico. Il quadro dota inoltre il sistema della competenza per gerarchizzare questi pensieri in base ai rispettivi punteggi, una caratteristica che si rivela determinante nel discernere quali idee meritano la precedenza o l’implementazione.
Mantiene un’unica catena di contesto in evoluzione, eliminando la necessità di query ridondanti come nell’albero del pensiero. Esplora un percorso mutevole di ragionamento.
Mentre ToT e GoT affrontano la sfida del ragionamento LLM attraverso meccanismi basati sulla ricerca, producendo una miriade di percorsi di ragionamento in forme grafiche. Tuttavia, la loro forte dipendenza da numerose query LLM, che a volte si contano a centinaia per un singolo problema, pone inefficienze computazionali.
IL Algoritmo dei pensieri (AoT) offre un metodo innovativo che prevede un percorso di ragionamento dinamico e mutevole. Mantenendo un’unica catena di contesto di pensiero in evoluzione, AoT consolida l’esplorazione del pensiero, migliorando l’efficienza e riducendo il sovraccarico computazionale.
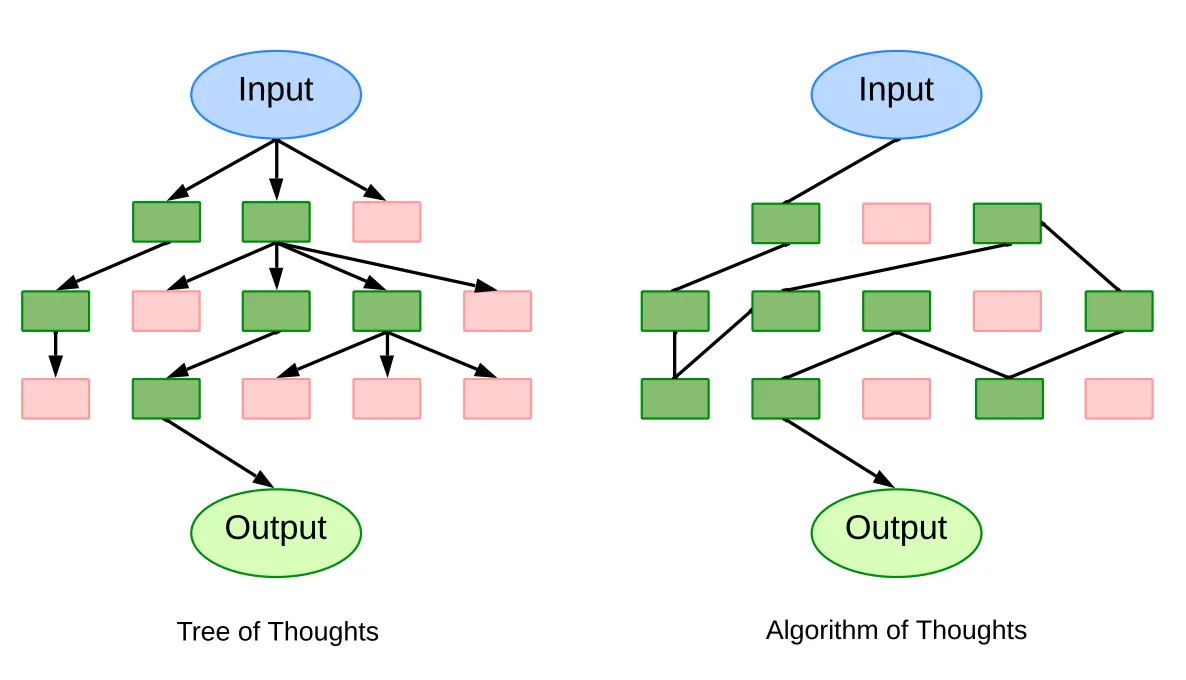
L’ingegnosità dietro AoT nasce dall’osservazione che gli LLM, sebbene potenti, occasionalmente ritornano a soluzioni precedenti quando si trovano ad affrontare problemi nuovi ma familiari. Per superare questo problema, AoT assimila esempi contestualizzati, attingendo ad algoritmi di ricerca collaudati nel tempo come la ricerca in profondità (DFS) e la ricerca in ampiezza (BFS). Emulando il comportamento algoritmico, AoT sottolinea l’importanza di ottenere risultati positivi e raccogliere informazioni dai tentativi falliti.
La pietra angolare dell’AoT risiede nelle sue quattro componenti principali: 1) scomposizione di problemi complessi in sottoproblemi digeribili, considerando sia la loro interrelazione che la facilità con cui possono essere affrontati individualmente; 2) Proporre soluzioni coerenti per questi sottoproblemi in modo continuo e ininterrotto; 3) Valutare intuitivamente la fattibilità di ogni soluzione o sottoproblema senza fare affidamento su espliciti suggerimenti esterni; e 4) Determinazione dei percorsi più promettenti da esplorare o su cui tornare indietro, sulla base di esempi contestualizzati e linee guida algoritmiche.
Genera prima un progetto di risposta prima di arricchire parallelamente i dettagli, riducendo il tempo necessario per generare una risposta completa.
IL Scheletro del pensiero (SoT) Il paradigma è specificamente progettato non principalmente per aumentare le capacità di ragionamento dei Large Language Models (LLM), ma per affrontare la sfida cruciale di ridurre al minimo la latenza di generazione end-to-end. La metodologia opera sulla base di un approccio in due fasi che si concentra sulla produzione di un progetto preliminare della risposta, seguito dalla sua espansione completa.
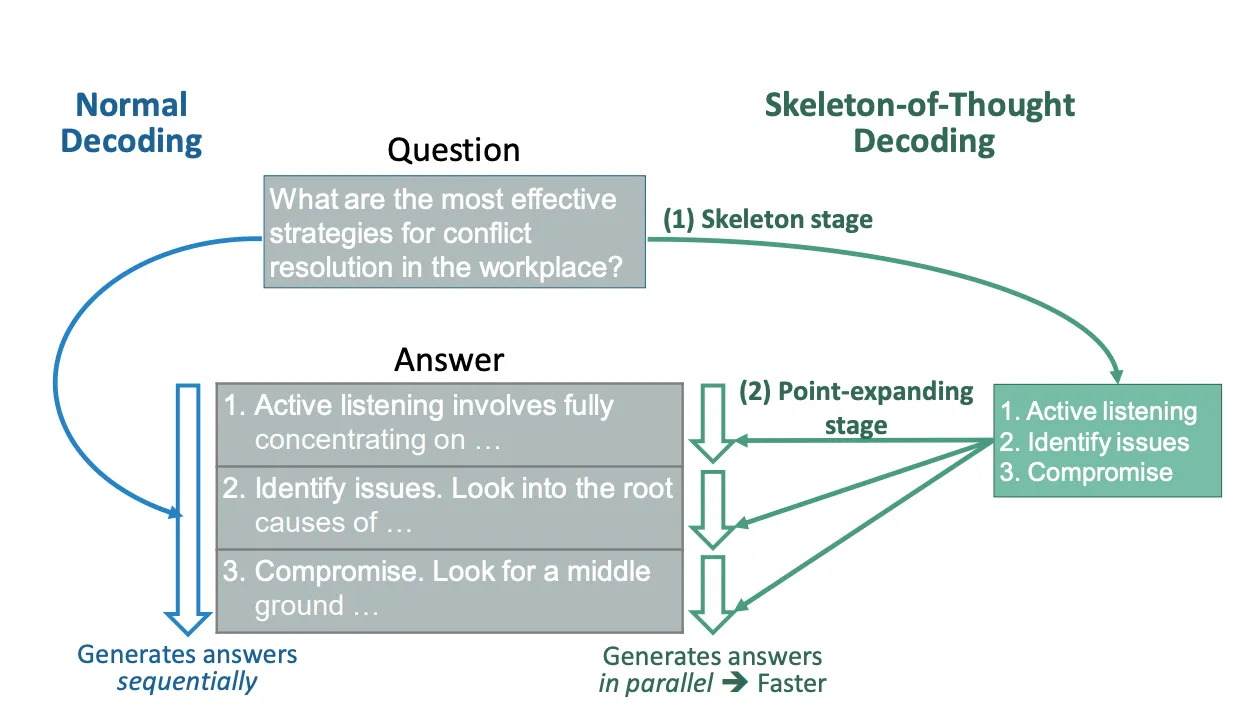
Nella “fase di scheletro” iniziale, invece di produrre una risposta completa, il modello viene invitato a generare uno scheletro di risposta conciso. Questa rappresentazione abbreviata, suggerita attraverso un modello di scheletro meticolosamente realizzato, cattura gli elementi fondamentali della potenziale risposta, stabilendo così una base per la fase successiva.
Nella successiva “fase di espansione dei punti”, il LLM amplifica sistematicamente ogni componente delineato nello scheletro della risposta. Sfruttando un modello di prompt in espansione di punti, il modello elabora contemporaneamente ciascun segmento dello scheletro. Questo approccio dicotomico, che separa il processo generativo in una formulazione scheletrica preliminare e in un’espansione dettagliata parallelizzata, non solo accelera la generazione della risposta, ma si sforza anche di mantenere la coerenza e la precisione degli output.
Formulare il ragionamento alla base della risposta alle domande in un programma eseguibile, incorporando l’output dell’interprete del programma come parte della risposta finale.
Programma di Pensiero (PoT) è un approccio unico al ragionamento LLM, invece di limitarsi a generare una risposta in linguaggio naturale, PoT impone la creazione di un programma eseguibile, il che significa che può essere eseguito su un interprete di programma, come Python, per produrre risultati tangibili. Questo metodo si contrappone ai modelli più diretti, sottolineando la sua capacità di scomporre il ragionamento in passaggi sequenziali e di associare significati semantici alle variabili. Di conseguenza, PoT offre un modello più chiaro, più espressivo e fondato su come vengono derivate le risposte, migliorando l’accuratezza e la comprensione, in particolare per domande logiche di tipo matematico in cui sono necessari calcoli numerici.
È importante notare che l’esecuzione del programma PoT non è necessariamente mirata alla risposta finale ma può essere parte del passaggio intermedio verso la risposta finale.

Fonte: towardsdatascience.com

