
La guida definitiva per scegliere il metodo giusto per il tuo caso d’uso
14 ore fa

Con l’aumento dell’ondata di interesse per i Large Language Models (LLM), molti sviluppatori e organizzazioni sono impegnati a creare applicazioni sfruttando la loro potenza. Tuttavia, quando i LLM pre-addestrati non funzionano come previsto o sperato, sorge la domanda su come migliorare le prestazioni dell’applicazione LLM. E alla fine arriviamo al punto in cui ci chiediamo: dovremmo usarlo Generazione aumentata di recupero (RAG) o messa a punto del modello per migliorare i risultati?
Prima di immergerci più a fondo, demistifichiamo questi due metodi:
STRACCIO: questo approccio integra la potenza del recupero (o della ricerca) nella generazione di testo LLM. Combina un sistema di recupero, che recupera frammenti di documenti rilevanti da un ampio corpus, e un LLM, che produce risposte utilizzando le informazioni di tali frammenti. In sostanza, RAG aiuta il modello a “cercare” informazioni esterne per migliorare le sue risposte.
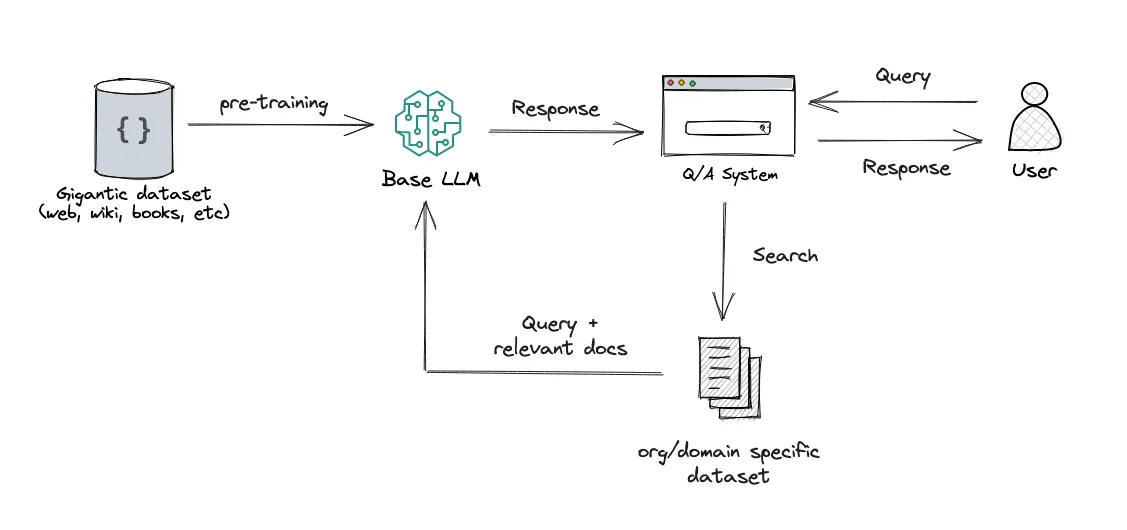
Ritocchi: questo è il processo di prendere un LLM pre-addestrato e formarlo ulteriormente su un set di dati più piccolo e specifico per adattarlo a un compito particolare o per migliorarne le prestazioni. Attraverso la messa a punto, stiamo adattando i pesi del modello in base ai nostri dati, rendendolo più adatto alle esigenze specifiche della nostra applicazione.

Sia RAG che finetuning fungono da potenti strumenti per migliorare le prestazioni delle applicazioni basate su LLM, ma affrontano aspetti diversi del processo di ottimizzazione e questo è fondamentale quando si tratta di scegliere l’uno rispetto all’altro.
In precedenza, suggerivo spesso alle organizzazioni di sperimentare RAG prima di dedicarsi alla messa a punto. Ciò si basava sulla mia percezione che entrambi gli approcci raggiungessero risultati simili ma variassero in termini di complessità, costo e qualità. Ho anche usato per illustrare questo punto con…

